|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










Productive Parallel Programming for FPGA with HLS
Title: Productive Parallel Programming for FPGA with High-Level Synthesis
Speakers: Johannes de Fine Licht and Torsten Hoefler
Recording: Available on YouTube
Slides: Part 0 [Introduction], Part 1 [Technical]
Example code: available on github
HLS extensions [1]: available on github
Key techniques used in this tutorial are included in our paper, Transformations of High-Level Synthesis Codes for High-Performance Computing published at IEEE TPDS [2], and available on arXiv.
Abstract: Energy efficiency has become a first class citizen in the design of large computing systems. While GPUs and custom processors have shown merit in this regard, reconfigurable architectures, such as FPGAs, promise another major step in energy efficiency, constituting a middle ground between fixed hardware architectures and custom-built ASICs. Programming FPGAs has traditionally been done in hardware description languages, requiring extensive hardware knowledge and significant engineering effort. This tutorial shows how high-level synthesis (HLS) can be harnessed to productively achieve scalable pipeline parallelism on FPGAs. Attendees will learn how to target FPGA resources from high-level C++ or OpenCL code, guiding the mapping from imperative code to hardware, enabling them to develop massively parallel designs with real performance benefits. We treat well-known examples from the software world, relating traditional code optimizations to both corresponding and new transformations for hardware, building on existing knowledge when introducing new topics. By bridging the gap between software and hardware optimization, our tutorial aims to enable developers from a larger set of backgrounds to start tapping into the potential of FPGAs with real high performance codes.
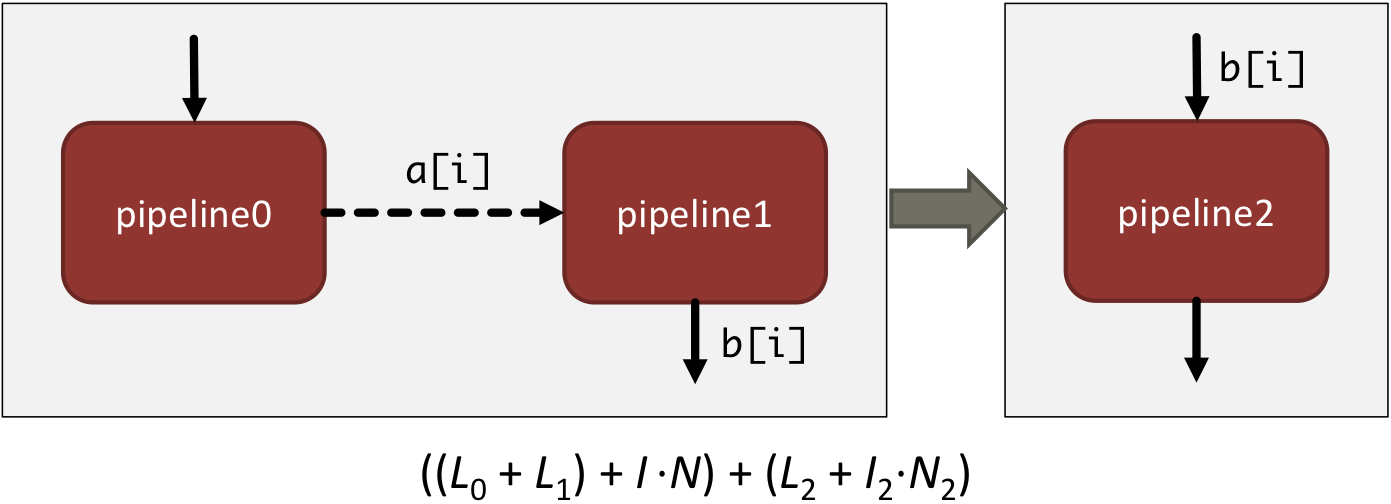
Iterations
SC'21
Venue: The International Conference for High Performance
Computing, Networking, Storage, and Analysis 2021 [SC'21]
Time: 8:00 AM — 12:00 PM CST, Sunday, November 14th, 2021
Location: TBD
ISC'21
Venue: ISC High Performance 2020 [ISC'21]
Time: 2:00 PM — 6:00 PM CEST, Friday, June 25th, 2021
Location: Virtual
SC'20
Venue: The International Conference for High Performance
Computing, Networking, Storage, and Analysis 2020 [SC'20]
Time: 10:00 AM — 2:00 PM EST, Monday, November 9th, 2020
Location: Virtual
HiPEAC'20
Venue: International Conference on High Performance and Embedded Architectures and Compilers [HiPEAC'20]
Time: 10:00 PM — 13:00 PM, Wednesday, February 22nd, 2020
Location: Bianca B, Palazzo dei Congressi, Bologna, Italy
SC'19
Venue: The International Conference for High Performance
Computing, Networking, Storage, and Analysis 2019 [SC'19]
Time: 1:30 PM — 5:00 PM, Sunday, November 17th, 2019
Location: 407, Colorado Convention Center, Denver, CO
SC'18
Venue: The International Conference for High Performance
Computing, Networking, Storage, and Analysis 2018 [SC'18]
Time: 13:30 - 17:00, Sunday November 11th, 2018
Location: C144, Kay Bailey Hutchison Convention Center, Dallas, TX
PPoPP'18
Venue: Principles and Practice of Parallel Programming 2018 [PPoPP'18]
Time: 08:30 - 12:00, Sunday February 25, 2018
Location: Pacific 2, Austria Trend Eventhotel Pyramide, Vienna, Austria
ETH
Venue: ETH Zurich
Time: 14:00 - 17:30, Tuesday May 15, 2018
Location: ETH Zurich ML H 37.1, Zurich, Switzerland
Content
We cover modeling, designing and implementing FPGA hardware using modern HLS tools. We include aspects of performance modeling, but the majority of the tutorial will focus on practice, with the goal of enabling attendees to start writing parallel hardware of their own.
After an introduction to dataflow architectures and an overview of existing technology in the domain of reconfigurable architectures, we move to the practical seciton by introducing the HLS abstraction. We use frequent code examples to introduce central properties of the mapping from imperative languages to hardware, and the performance aspects implied by this transformation. Examples will be demonstrated with small to medium length live coding sessions interleaved with the presentation, such that attendees are faced with real coding at a pace that is easy to follow. All examples shown are available to attendees, along with a virtual machine containing the relevant HLS tool, allowing them to follow and do further experiments before, during and/or after the tutorial.
All concepts demonstrated will be put in the context of HPC by highlighting their performance impact, constituting an approach to HLS that is built around the main strength of the FPGA architecture: pipeline parallelism. We show how to resolve common complications that arise when designing pipelines, such as loop-carried dependencies and memory interface contention, and how pipelined designs can be scaled up to exploit the full performance potential of the FPGA. After the break, we apply the concepts presented to an HPC application, demonstrating how an HLS design can be scaled up fully utilize a modern FPGA accelerator.
We close the tutorial with a discussion of the limitations of HLS (that are not usually advertised by vendors), and an overview of the current vendor, hardware, and toolset landscape.

Nallatech 520N (Intel Stratix 10).

Xilinx VCU1525 (Ultrascale+ VU9P).
Hands-on
The presentation is interleaved with live demos, exposing attendees to real code, synthesized live with an HLS tool by the presenter.
The tools required to build the provided code examples can be downloaded and installed from the Xilinx and/or Intel websites (this might require registering free accounts with Xilinx and/or Intel, respectively).
Prerequisite knowledge
This tutorial is aimed at audiences coming from an HPC background, interested in programming FPGAs for massive spatial parallelism. To benefit from the tutorial, the following prior knowledge is suggested:
- Proficiency in C++
- Basics of FPGA architecture
- Performance optimization techniques on CPU/GPU (tiling, unrolling, vectorization)
References
| [1] J. de Fine Licht, T. Hoefler: | ||
hlslib: Software Engineering for Hardware Design
In Fifth International Workshop on Heterogeneous High-performance Reconfigurable Computing (H2RC'19), presented in Denver, CO, United States, IEEE, Nov. 2019, 

| ||
| [2] J. de Fine Licht, M. Besta, S. Meierhans, T. Hoefler: | ||
Transformations of High-Level Synthesis Codes for High-Performance Computing
IEEE Transactions on Parallel and Distributed Systems. Vol 32, Nr. 5, pages 1014-1029, IEEE, May 2021,

| ||