|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










SPCL_Bcast(COMM_WORLD)
What: SPCL_Bcast is an open, online seminar series that covers a broad range of topics around parallel and high-performance computing, scalable machine learning, and related areas.
Who: We invite top researchers and engineers from all over the world to speak.
Where: Anyone is welcome to join over Zoom! This link will always redirect to the right Zoom meeting. When possible, we make recordings available on our YouTube channel.
Old talks: See the SPCL_Bcast archive.
Social media: Follow along with #spcl_bcast on Twitter!
When: Every two weeks on Thursdays, at 9AM or 6PM CET.
Fugaku: The First 'Exascale' Supercomputer – Past, Present and Future
Abstract: Fugaku is the first 'exascale' supercomputer of the world, not due to its peak double precision flops, but rather, its demonstrated performance in real applications that were expected of exascale machines on their conceptions 10 years ago, as well as reaching actual exaflops in new breeds of benchmarks such as HPL-AI. But the importance of Fugaku is its "applications first" philosophy under which it was developed, and its resulting mission to be the centerpiece for rapid realization of the so-called Japanese 'Society 5.0' as defined by the Japanese S&T national policy. As such, Fugaku's immense power is directly applicable not only to traditional scientific simulation applications, but can be a target of Society 5.0 applications that encompasses conversion of HPC & AI & Big Data as well as Cyber (IDC & Network) vs. Physical (IoT) space, with immediate societal impact. In fact, Fugaku is already in partial operation a year ahead of schedule, primarily to obtain early Society 5.0 results including combatting COVID-19 as well as resolving other important societal issues. The talk will introduce how Fugaku had been conceived, analyzed, and built over the 10 year period, look at its current efforts regarding Society 5.0 and COVID, as well as touch upon our thoughts on the next generation machine, or "Fugaku NeXT".
 Bio: Satoshi Matsuoka is the director of RIKEN R-CCS, the top-tier HPC center in Japan which operates the K Computer and will host its successor Supercomputer Fugaku, and he is a Specially Appointed Professor at Tokyo Tech since 2018. He had been a Full Professor at the Global Scientific Information and Computing Center (GSIC), Tokyo Institute of Technology, since 2000, where he has been the leader of the TSUBAME series of supercomputers that have won many accolades such as world #1 in power-efficient computing. Satoshi Matsuoka also leads various major supercomputing research projects in areas such as parallel algorithms and programming, resilience, green computing, and convergence of Big Data/AI with HPC. He has written over 500 articles, chaired numerous ACM/IEEE conferences, and has won many awards, such as the ACM Gordon Bell Prize in 2011 and the highly prestigious 2014 IEEE-CS Sidney Fernbach Memorial Award.
Bio: Satoshi Matsuoka is the director of RIKEN R-CCS, the top-tier HPC center in Japan which operates the K Computer and will host its successor Supercomputer Fugaku, and he is a Specially Appointed Professor at Tokyo Tech since 2018. He had been a Full Professor at the Global Scientific Information and Computing Center (GSIC), Tokyo Institute of Technology, since 2000, where he has been the leader of the TSUBAME series of supercomputers that have won many accolades such as world #1 in power-efficient computing. Satoshi Matsuoka also leads various major supercomputing research projects in areas such as parallel algorithms and programming, resilience, green computing, and convergence of Big Data/AI with HPC. He has written over 500 articles, chaired numerous ACM/IEEE conferences, and has won many awards, such as the ACM Gordon Bell Prize in 2011 and the highly prestigious 2014 IEEE-CS Sidney Fernbach Memorial Award.Homepage
A Paradigm Shift to Second Order Methods for Machine Learning
Abstract: The amount of compute needed to train modern NN architectures has been doubling every few months. With this trend, it is no longer possible to perform brute force hyperparameter tuning to train the model to good accuracy. However, first-order methods such as Stochastic Gradient Descent are quite sensitive to such hyperparameter tuning and can easily diverge for challenging problems. However, many of these problems can be addressed with second-order optimizers. In this direction, we introduce AdaHessian, a new stochastic optimization algorithm. AdaHessian directly incorporates approximate curvature information from the loss function, and it includes several novel performance-improving features, including: (i) a fast Hutchinson based method to approximate the curvature matrix with low computational overhead; and (ii) a spatial/temporal block diagonal averaging to smooth out variations of second-derivate over different parameters/iterations. Extensive tests on NLP, CV, and recommendation system tasks, show that AdaHessian achieves state-of-the-art results, with 10x less sensitivity to hyperparameter tuning as compared to ADAM.
In particular, we find that AdaHessian:
(i) outperforms AdamW for transformers by 0.13/0.33 BLEU score on IWSLT14/WMT14, 2.7/1.0 PPL on PTB/Wikitext-103;
(ii) outperforms AdamW for SqueezeBert by 0.41 points on GLUE;
(iii) achieves 1.45%/5.55% higher accuracy on ResNet32/ResNet18 on Cifar10/ImageNet as compared to Adam; and
(iv) achieves 0.032% better score than AdaGrad for DLRM on the Criteo Ad Kaggle dataset.
The cost per iteration of AdaHessian is comparable to first-order methods, and AdaHessian exhibits improved robustness towards variations in hyperparameter values.
 Bio: Amir Gholami is a senior research fellow at ICSI and Berkeley AI Research (BAIR). He received his PhD from UT Austin, working on large scale 3D image segmentation, a research topic which received UT Austin’s best doctoral dissertation award in 2018. He is a Melosh Medal finalist, the recipient of best student paper award in SC'17, Gold Medal in the ACM Student Research Competition, as well as best student paper finalist in SC’14. Amir is a recognized expert in industry with long lasting contributions. He was part of the Nvidia team that for the first time made FP16 training possible, enabling more than 10x increase in compute power through tensor cores. That technology has been widely adopted in GPUs today. Amir's current research focuses on exa-scale neural network training and efficient inference.
Bio: Amir Gholami is a senior research fellow at ICSI and Berkeley AI Research (BAIR). He received his PhD from UT Austin, working on large scale 3D image segmentation, a research topic which received UT Austin’s best doctoral dissertation award in 2018. He is a Melosh Medal finalist, the recipient of best student paper award in SC'17, Gold Medal in the ACM Student Research Competition, as well as best student paper finalist in SC’14. Amir is a recognized expert in industry with long lasting contributions. He was part of the Nvidia team that for the first time made FP16 training possible, enabling more than 10x increase in compute power through tensor cores. That technology has been widely adopted in GPUs today. Amir's current research focuses on exa-scale neural network training and efficient inference.Homepage
 Zhewei Yao is a Ph.D. student in the BAIR, RISELab (former AMPLab), BDD and Math Department at University of California at Berkeley. He is advised by Michael Mahoney, and he is also working very closely with Kurt Keutzer. His research interest lies in computing statistics, optimization, and machine learning. Currently, he is interested in leveraging tools from randomized linear algebra to provide efficient and scalable solutions for large-scale optimization and learning problems. He is also working on the theory and application of deep learning. Before joining UC Berkeley, he received his B.S. in Math from Zhiyuan Honor College at Shanghai Jiao Tong University.
Zhewei Yao is a Ph.D. student in the BAIR, RISELab (former AMPLab), BDD and Math Department at University of California at Berkeley. He is advised by Michael Mahoney, and he is also working very closely with Kurt Keutzer. His research interest lies in computing statistics, optimization, and machine learning. Currently, he is interested in leveraging tools from randomized linear algebra to provide efficient and scalable solutions for large-scale optimization and learning problems. He is also working on the theory and application of deep learning. Before joining UC Berkeley, he received his B.S. in Math from Zhiyuan Honor College at Shanghai Jiao Tong University.Homepage
Distributed Deep Learning with Second Order Information
Abstract: As the scale of deep neural networks continues to increase exponentially, distributed training is becoming an essential tool in deep learning. Especially in the context of un/semi/self-supervised pretraining, larger models tend to achieve much higher accuracy. This trend is especially clear in natural language processing, where the latest GPT-3 model has 175 billion parameters. The training of such models requires hybrid data+model-parallelism. In this talk, I will describe two of our recent efforts; 1) second-order optimization and 2) reducing memory footprint, in the context of large-scale distributed deep learning.
 Bio: Rio Yokota is an Associate Professor at the Tokyo Institute of Technology. His research interest lie at the intersection of HPC and ML. On the HPC side, he has worked on hierarchical low-rank approximation methods such as FMM and H-matrices. He has worked on GPU computing since 2007 and won the Gordon Bell prize using the first GPU supercomputer in 2009. On the ML side, he works on distributed deep learning and second-order optimization. His work on training ImageNet in 2 minutes with second-order methods has been extended to various applications using second-order information.
Bio: Rio Yokota is an Associate Professor at the Tokyo Institute of Technology. His research interest lie at the intersection of HPC and ML. On the HPC side, he has worked on hierarchical low-rank approximation methods such as FMM and H-matrices. He has worked on GPU computing since 2007 and won the Gordon Bell prize using the first GPU supercomputer in 2009. On the ML side, he works on distributed deep learning and second-order optimization. His work on training ImageNet in 2 minutes with second-order methods has been extended to various applications using second-order information.Homepage
High Performance Tensor Computations
Abstract: Tensor decompositions, contractions, and tensor networks are prevalent in applications ranging from data modeling to simulation of quantum systems. Numerical kernels within these methods present challenges associated with sparsity, symmetry, and other types of tensor structure. We describe recent innovations in algorithms for tensor contractions and tensor decompositions, which minimize costs and improve scalability. Further, we highlight new libraries for (1) automatic differentiation in the context of high-order tensor optimization, (2) efficient tensor decomposition, and (3) tensor network state simulation. These libraries all build on distributed tensor contraction kernels for sparse and dense tensors provided by the Cyclops library, enabling a shared ecosystem for applications of tensor computations.
 Bio: Edgar Solomonik is an assistant professor in the Department of Computer Science at the University of Illinois at Urbana-Champaign. He was previously an ETH Zurich Postdoctoral Fellow at ETH Zurich and did his PhD at the University of California, Berkeley. He has received the DOE Computational Science Graduate Fellowship, ACM/IEEE-CS George Michael Memorial HPC Fellowship, the David J. Sakrison Memorial Prize, the Alston S. Householder Prize, the IEEE-CS TCHPC Award for Excellence for Early Career Researchers in High Performance Computing, the SIAM Activity Group on Supercomputing Early Career Prize, and an NSF CAREER award. His research focuses on high performance numerical linear algebra, tensor computations, and parallel algorithms.
Bio: Edgar Solomonik is an assistant professor in the Department of Computer Science at the University of Illinois at Urbana-Champaign. He was previously an ETH Zurich Postdoctoral Fellow at ETH Zurich and did his PhD at the University of California, Berkeley. He has received the DOE Computational Science Graduate Fellowship, ACM/IEEE-CS George Michael Memorial HPC Fellowship, the David J. Sakrison Memorial Prize, the Alston S. Householder Prize, the IEEE-CS TCHPC Award for Excellence for Early Career Researchers in High Performance Computing, the SIAM Activity Group on Supercomputing Early Career Prize, and an NSF CAREER award. His research focuses on high performance numerical linear algebra, tensor computations, and parallel algorithms.Homepage
Light-Weight Performance Analysis for Next-Generation HPC Systems
Abstract: Building efficient and scalable performance analysis and optimizing tools, for large-scale systems, is increasingly important both for the developers of parallel applications and the designers of next-generation HPC systems. However, conventional performance tools suffer from significant time/space overhead due to the ever-increasing problem size and system scale. On the other hand, the cost of source code analysis is independent of the problem size and system scale, making it very appealing for large-scale performance analysis. Inspired by this observation, we have designed a series of light-weight performance tools for HPC systems, such as memory access monitoring, performance variance detection, and communication compression. In this talk, I will share our expreience on building these tools through combining static analysis and runtime analysis and also point out the main challenges in this direction.
 Bio: Jidong Zhai is a Tenured Associate Professor in the Computer Science Department of Tsinghua University. He is a recipient of Siebel Scholar, CCF outstanding doctoral dissertation Award, IEEE TPDS Award for Editorial Excellence, and NSFC Young Career Award. He was a Visiting Professor of Stanford University (2015-2016) and a Visiting Scholar of MSRA (Microsoft Research Asia) in 2013. His research interests include parallel computing, performance evaluation, compiler optimization, and heterogeneous computing. He has published more than 50 papers in prestigious refereed conferences and top journals including SC, PPOPP, ASPLOS, ICS, ATC, MICRO, NSDI, IEEE TPDS, and IEEE TC. His research received a Best Paper Finalist at SC14. He is the advisor of Tsinghua Student Cluster Team. The team led by him has achieved 9 international champions in student supercomputing challenges at SC, ISC, and ASC. In 2015 and 2018, the team led by him swept all three champions at SC, ISC, and ASC. He was a program co-chair of NPC 2018 and a program co-chair of ICPP PASA 2015 workshop. He served or is now serving TPC member of SC, ICS, PPOPP, IPDPS, ICPP, NAS, LCPC, and Euro-Par. He is the general secretary of ACM SIGHPC China. He is currently on the editorial boards of IEEE Transactions on Parallel and Distributed Systems (TPDS), IEEE Transactions on Cloud Computing (TCC), and Journal of Parallel and Distributed Computing.
Bio: Jidong Zhai is a Tenured Associate Professor in the Computer Science Department of Tsinghua University. He is a recipient of Siebel Scholar, CCF outstanding doctoral dissertation Award, IEEE TPDS Award for Editorial Excellence, and NSFC Young Career Award. He was a Visiting Professor of Stanford University (2015-2016) and a Visiting Scholar of MSRA (Microsoft Research Asia) in 2013. His research interests include parallel computing, performance evaluation, compiler optimization, and heterogeneous computing. He has published more than 50 papers in prestigious refereed conferences and top journals including SC, PPOPP, ASPLOS, ICS, ATC, MICRO, NSDI, IEEE TPDS, and IEEE TC. His research received a Best Paper Finalist at SC14. He is the advisor of Tsinghua Student Cluster Team. The team led by him has achieved 9 international champions in student supercomputing challenges at SC, ISC, and ASC. In 2015 and 2018, the team led by him swept all three champions at SC, ISC, and ASC. He was a program co-chair of NPC 2018 and a program co-chair of ICPP PASA 2015 workshop. He served or is now serving TPC member of SC, ICS, PPOPP, IPDPS, ICPP, NAS, LCPC, and Euro-Par. He is the general secretary of ACM SIGHPC China. He is currently on the editorial boards of IEEE Transactions on Parallel and Distributed Systems (TPDS), IEEE Transactions on Cloud Computing (TCC), and Journal of Parallel and Distributed Computing.Homepage
Decomposing MPI Collectives for Exploiting Multi-lane Communication
Abstract: Many modern, high-performance systems increase the cumulated node-bandwidth by offering more than a single communication network and/or by having multiple connections to the network, such that a single processor-core cannot by itself saturate the off-node bandwidth. Efficient algorithms and implementations for collective operations as found in, e.g., MPI, must be explicitly designed for exploiting such multi-lane capabilities. We are interested in gauging to which extent this might be the case.
In the talk, I will illustrate how we systematically decompose the MPI collectives into similar operations that can execute concurrently on and exploit multiple network lanes. Our decomposition is applicable to all standard, regular MPI collectives, and our implementations' performance can be readily compared to the native collectives of any given MPI library. Contrary to expectation, our full-lane, performance guideline implementations in many cases show surprising performance improvements with different MPI libraries on different systems, indicating severe problems with native MPI library implementations. In many cases, our full-lane implementations are large factors faster than the corresponding library MPI collectives. The results indicate considerable room for improvement of the MPI collectives in current MPI libraries including a more efficient use of multi-lane capabilities.
 Bio: Jesper Larsson Träff is professor for Parallel Computing at TU Wien (Vienna University of Technology) since 2011. From 2010 to 2011 he was guest professor for Scientific Computing at the University of Vienna. From 1998 until 2010 he was working at the NEC Laboratories Europe in Sankt Augustin, Germany on efficient implementations of MPI for NEC vector supercomputers; this work led to a doctorate (Dr. Scient.) from the University of Copenhagen in 2009. From 1995 to 1998 he spent four years as PostDoc/Research Associate in the Algorithms Group of the Max-Planck Institute for Computer Science in Saarbrücken, and the Efficient Algorithms Group at the Technical University of Munich. He received an M.Sc. in computer science in 1989, and, after two interim years at the industrial research center ECRC in Munich, a Ph.D. in 1995, both from the University of Copenhagen.
Bio: Jesper Larsson Träff is professor for Parallel Computing at TU Wien (Vienna University of Technology) since 2011. From 2010 to 2011 he was guest professor for Scientific Computing at the University of Vienna. From 1998 until 2010 he was working at the NEC Laboratories Europe in Sankt Augustin, Germany on efficient implementations of MPI for NEC vector supercomputers; this work led to a doctorate (Dr. Scient.) from the University of Copenhagen in 2009. From 1995 to 1998 he spent four years as PostDoc/Research Associate in the Algorithms Group of the Max-Planck Institute for Computer Science in Saarbrücken, and the Efficient Algorithms Group at the Technical University of Munich. He received an M.Sc. in computer science in 1989, and, after two interim years at the industrial research center ECRC in Munich, a Ph.D. in 1995, both from the University of Copenhagen.Homepage
Large Graph Processing on Heterogeneous Architectures: Systems, Applications and Beyond
Abstract: Graphs are de facto data structures for many data processing applications, and their volume is ever growing. Many graph processing tasks are computation intensive and/or memory intensive. Therefore, we have witnessed a significant amount of effort in accelerating graph processing tasks with heterogeneous architectures like GPUs, FPGAs and even ASICs. In this talk, we will first review the literatures of large graph processing systems on heterogeneous architectures. Next, we present our research efforts, and demonstrate the significant performance impact of hardware-software co-design on designing high performance graph computation systems and applications. Finally, we outline the research agenda on challenges and opportunities in the system and application development of future graph processing.
 Bio: Dr. Bingsheng He is currently an Associate Professor and Vice-Dean (Research) at School of Computing, National University of Singapore. Before that, he was a faculty member in Nanyang Technological University, Singapore (2010-2016), and held a research position in the System Research group of Microsoft Research Asia (2008-2010), where his major research was building high performance cloud computing systems for Microsoft. He got the Bachelor degree in Shanghai Jiao Tong University (1999-2003), and the Ph.D. degree in Hong Kong University of Science & Technology (2003-2008). His current research interests include cloud computing, database systems and high performance computing. His papers are published in prestigious international journals (such as ACM TODS and IEEE TKDE/TPDS/TC) and proceedings (such as ACM SIGMOD, VLDB/PVLDB, ACM/IEEE SuperComputing, ACM HPDC, and ACM SoCC). He has been awarded with the IBM Ph.D. fellowship (2007-2008) and with NVIDIA Academic Partnership (2010-2011). Since 2010, he has (co-)chaired a number of international conferences and workshops, including IEEE CloudCom 2014/2015, BigData Congress 2018 and ICDCS 2020. He has served in editor board of international journals, including IEEE Transactions on Cloud Computing (IEEE TCC), IEEE Transactions on Parallel and Distributed Systems (IEEE TPDS), IEEE Transactions on Knowledge and Data Engineering (TKDE), Springer Journal of Distributed and Parallel Databases (DAPD) and ACM Computing Surveys (CSUR). He has got editorial excellence awards for his service in IEEE TCC and IEEE TPDS in 2019.
Bio: Dr. Bingsheng He is currently an Associate Professor and Vice-Dean (Research) at School of Computing, National University of Singapore. Before that, he was a faculty member in Nanyang Technological University, Singapore (2010-2016), and held a research position in the System Research group of Microsoft Research Asia (2008-2010), where his major research was building high performance cloud computing systems for Microsoft. He got the Bachelor degree in Shanghai Jiao Tong University (1999-2003), and the Ph.D. degree in Hong Kong University of Science & Technology (2003-2008). His current research interests include cloud computing, database systems and high performance computing. His papers are published in prestigious international journals (such as ACM TODS and IEEE TKDE/TPDS/TC) and proceedings (such as ACM SIGMOD, VLDB/PVLDB, ACM/IEEE SuperComputing, ACM HPDC, and ACM SoCC). He has been awarded with the IBM Ph.D. fellowship (2007-2008) and with NVIDIA Academic Partnership (2010-2011). Since 2010, he has (co-)chaired a number of international conferences and workshops, including IEEE CloudCom 2014/2015, BigData Congress 2018 and ICDCS 2020. He has served in editor board of international journals, including IEEE Transactions on Cloud Computing (IEEE TCC), IEEE Transactions on Parallel and Distributed Systems (IEEE TPDS), IEEE Transactions on Knowledge and Data Engineering (TKDE), Springer Journal of Distributed and Parallel Databases (DAPD) and ACM Computing Surveys (CSUR). He has got editorial excellence awards for his service in IEEE TCC and IEEE TPDS in 2019.Homepage
Enabling Rapid COVID-19 Small Molecule Drug Design Through Scalable Deep Learning of Generative Models
Abstract: We improved the quality and reduced the time to produce machine-learned models for use in small molecule antiviral design. Our globally asynchronous multi-level parallel training approach strong scales to all of Sierra with up to 97.7% efficiency. We trained a novel, character-based Wasserstein autoencoder that produces a higher quality model trained on 1.613 billion compounds in 23 minutes while the previous state-of-the-art takes a day on 1 million compounds. Reducing training time from a day to minutes shifts the model creation bottleneck from computer job turnaround time to human innovation time. Our implementation achieves 318 PFLOPS for 17.1% of half-precision peak. We will incorporate this model into our molecular design loop, enabling the generation of more diverse compounds: searching for novel, candidate antiviral drugs improves and reduces the time to synthesize compounds to be tested in the lab.
 Bio: Brian Van Essen is the informatics group leader and a computer scientist at the Center for Applied Scientific Computing at Lawrence Livermore National Laboratory (LLNL). He is pursuing research in large-scale deep learning for scientific domains and training deep neural networks using high-performance computing systems. He is the project leader for the Livermore Big Artificial Neural Network open-source deep learning toolkit, and the LLNL lead for the ECP ExaLearn and CANDLE projects. Additionally, he co-leads an effort to map scientific machine learning applications to neural network accelerator co-processors as well as neuromorphic architectures. He joined LLNL in 2010 after earning his Ph.D. and M.S. in computer science and engineering at the University of Washington. He also has an M.S and B.S. in electrical and computer engineering from Carnegie Mellon University.
Bio: Brian Van Essen is the informatics group leader and a computer scientist at the Center for Applied Scientific Computing at Lawrence Livermore National Laboratory (LLNL). He is pursuing research in large-scale deep learning for scientific domains and training deep neural networks using high-performance computing systems. He is the project leader for the Livermore Big Artificial Neural Network open-source deep learning toolkit, and the LLNL lead for the ECP ExaLearn and CANDLE projects. Additionally, he co-leads an effort to map scientific machine learning applications to neural network accelerator co-processors as well as neuromorphic architectures. He joined LLNL in 2010 after earning his Ph.D. and M.S. in computer science and engineering at the University of Washington. He also has an M.S and B.S. in electrical and computer engineering from Carnegie Mellon University.Homepage
Optimizing CESM-HR on Sunway TaihuLight and An Unprecedented Set of Multi-Century Simulations
Abstract: CESM is one of the very first and most complex scientific codes that gets migrated onto Sunway TaihuLight. Being a community code involving hundreds of different dynamic, physics, and chemistry processes, CESM brings severe challenges for the many-core architecture and the parrallel scale of Sunway TaihuLight. This talk summarizes our continuous effort on enabling efficient run of CESM on Sunway, starting from refactoring of CAM in 2015, redesigning of CAM in 2016 and 2017, and a collaborative effort starting in 2018 to enable highly efficient simulations of the high-resolution (25 km atmosphere and 10 km ocean) Community Earth System Model (CESM-HR) on Sunway Taihu-Light. The refactoring and optimizing efforts have improved the simulation speed of CESM-HR from 1 SYPD (simulation years per day) to 5 SYPD (with output disabled). Using CESM-HR, We manage to provide an unprecedented set of high-resolution climate simulations, consisting of a 500-year pre-industrial control simulation and a 250-year historical and future climate simulation from 1850 to 2100. Overall, high-resolution simulations show significant improvements in representing global mean temperature changes, seasonal cycle of sea-surface temperature and mixed layer depth, extreme events and in relationships between extreme events and climate modes.
 Bio: Haohuan Fu is a professor in the Ministry of Education Key Laboratory for Earth System Modeling, and Department of Earth System Science in Tsinghua University, where he leads the research group of High Performance Geo-Computing (HPGC). He is also the deputy director of the National Supercomputing Center in Wuxi, leading the research and development division. Fu has a PhD in computing from Imperial College London. His research work focuses on providing both the most efficient simulation platforms and the most intelligent data management and analysis platforms for geoscience applications, leading to two consecutive winning of the ACM Gordon Bell Prizes (nonhydrostatic atmospheric dynamic solver in 2016, and nonlinear earthquake simulation in 2017).
Bio: Haohuan Fu is a professor in the Ministry of Education Key Laboratory for Earth System Modeling, and Department of Earth System Science in Tsinghua University, where he leads the research group of High Performance Geo-Computing (HPGC). He is also the deputy director of the National Supercomputing Center in Wuxi, leading the research and development division. Fu has a PhD in computing from Imperial College London. His research work focuses on providing both the most efficient simulation platforms and the most intelligent data management and analysis platforms for geoscience applications, leading to two consecutive winning of the ACM Gordon Bell Prizes (nonhydrostatic atmospheric dynamic solver in 2016, and nonlinear earthquake simulation in 2017).Evaluating modern programming models using the Parallel Research Kernels
Abstract: The Parallel Research Kernels were developed to support empirical studies of programming models in a variety of contexts without the porting effort required by proxy or mini-applications. I will describe the project and why it has been a useful tool in a variety of contexts and present some of our findings related to modern C++ parallelism for CPU and GPU architectures.
 Bio: Jeff Hammond is a Principal Engineer at Intel where he works on a wide range of high-performance computing topics, including parallel programming models, system architecture and open-source software. Previously, Jeff worked at the Argonne Leadership Computing Facility where he worked on Blue Gene and built things with MPI. Jeff received his PhD in Physical Chemistry from the University of Chicago for research performed in collaboration with the NWChem team at Pacific Northwest National Laboratory.
Bio: Jeff Hammond is a Principal Engineer at Intel where he works on a wide range of high-performance computing topics, including parallel programming models, system architecture and open-source software. Previously, Jeff worked at the Argonne Leadership Computing Facility where he worked on Blue Gene and built things with MPI. Jeff received his PhD in Physical Chemistry from the University of Chicago for research performed in collaboration with the NWChem team at Pacific Northwest National Laboratory.Homepage
High-Performance Sparse Tensor Operations in HiParTI Library
Abstract: This talk will present the recent development of HiParTI, a Hierarchical Parallel Tensor Infrastructure. I will emphasize on the element-wise sparse tensor contractions, commonly shown in quantum chemistry, physics, and others. We introduce three optimization techniques by using multi-dimensional, efficient hashtable representation for the accumulator and larger input tensor, and all-stage parallelization. Evaluating with 15 datasets, we obtain 28 - 576x speedup over the traditional sparse tensor contraction. With our proposed algorithm- and memory heterogeneity-aware data management, extra performance improvement is achieved on the heterogeneous memory with DRAM and Intel Optane DC Persistent Memory Module (PMM) over a state-of-the-art solutions.
 Bio: Jiajia Li is a research scientist in High Performance Computing group at Pacific Northwest National Laboratory (PNNL). She has received her Ph.D. degree from Georgia Institute of Technology in 2018. Her current research emphasizes on optimizing tensor methods especially for sparse data from diverse applications by utilizing various parallel architectures. She is an awardee of Best Student Paper Award at SC'18, Best Paper Finalist at PPoPP'19, and "A Rising Star in Computational and Data Sciences". She has served on the technical program committee of conferences/journals, such as PPoPP, SC, ICS, IPDPS, ICPP, LCTES, Cluster, ICDCS, TPDS, etc. In the past, she had received a Ph.D. degree from Institute of Computing Technology at Chinese Academy of Sciences, China and a B.S. degree in Computational Mathematics from Dalian University of Technology, China.
Bio: Jiajia Li is a research scientist in High Performance Computing group at Pacific Northwest National Laboratory (PNNL). She has received her Ph.D. degree from Georgia Institute of Technology in 2018. Her current research emphasizes on optimizing tensor methods especially for sparse data from diverse applications by utilizing various parallel architectures. She is an awardee of Best Student Paper Award at SC'18, Best Paper Finalist at PPoPP'19, and "A Rising Star in Computational and Data Sciences". She has served on the technical program committee of conferences/journals, such as PPoPP, SC, ICS, IPDPS, ICPP, LCTES, Cluster, ICDCS, TPDS, etc. In the past, she had received a Ph.D. degree from Institute of Computing Technology at Chinese Academy of Sciences, China and a B.S. degree in Computational Mathematics from Dalian University of Technology, China.Homepage
HPHPC: High Productivity High Performance Computing with Legion and Legate
Abstract: This talk will describe the co-design and implementation of Legion and Legate, two programming systems that synergistically combine to provide to high productivity high performance computing ecosystem. In the first part of the talk, we'll introduce Legion, a task-based runtime system for supercomputers with a strong data model that enables a sophisticated dependence analysis. The second part of the talk will cover Legate, a framework for constructing drop-in replacements for popular Python libraries such as NumPy and Pandas on top of Legion. We'll show how using Legate and Legion together allows users to run unmodified Python programs at scale on hundreds of GPUs simply by changing a few import statements. We'll also discuss how the Legate framework makes it possible to compose such libraries even in distributed settings.
Homepage
Performance Engineering for Sparse Matrix-Vector Multiplication: Some new ideas for old problems
Abstract: The sparse matrix-vector multiplication (SpMV) kernel is a key performance component of numerous algorithms in computational science. Despite the kernel's apparent simplicity, the sparse and potentially irregular data access patterns of SpMV and its intrinsically low computational intensity haven been challenging the development of high-performance implementations over decades. Still these developments are rarely guided by appropriate performance models.
This talk will address the basic problem of understanding (i.e., modelling) and improving the computational intensity of SpMV kernels with a focus on symmetric matrices. Using a recursive algebraic coloring (RACE) of the underlying undirected graph, a node-level parallel symmetric SpMV implementation is developed which increases the computational intensity and the performance for a large general set of matrices by a factor of up to 2x. The same idea is then applied to accelerate the computation sparse matrix powers via cache blocking.
 Bio: Gerhard Wellein is a Professor for High Performance Computing at the Department for Computer Science at the University of Erlangen-Nuremberg and holds a PhD in theoretical physics from the University of Bayreuth. Since 2001 he heads the Erlangen National Center for High Performance Computing, he is the deputy speaker of the Bavarian HPC network KONWIHR and he is member of the scientific steering committee of the Gauss-Centre for Supercomputing (GCS).
Bio: Gerhard Wellein is a Professor for High Performance Computing at the Department for Computer Science at the University of Erlangen-Nuremberg and holds a PhD in theoretical physics from the University of Bayreuth. Since 2001 he heads the Erlangen National Center for High Performance Computing, he is the deputy speaker of the Bavarian HPC network KONWIHR and he is member of the scientific steering committee of the Gauss-Centre for Supercomputing (GCS).Gerhard Wellein has more than twenty years of experience in teaching HPC techniques to students and scientists from computational science and engineering, is an external trainer in the Partnership for Advanced Computing in Europe (PRACE) and received the "2011 Informatics Europe Curriculum Best Practices Award" (together with Jan Treibig and Georg Hager) for outstanding teaching contributions. His research interests focus on performance modelling and performance engineering, architecture-specific code optimization, novel parallelization approaches and hardware-efficient building blocks for sparse linear algebra and stencil solvers. He has been conducting and leading numerous HPC projects including the German Japanese project "Equipping Sparse Solvers for Exascale" (ESSEX) within the DFG priority program SPPEXA ("Software for Exascale Computing").
Homepage
Cloud-Scale Inference on FPGAs at Microsoft Bing
Abstract: Microsoft's Project Catapult began nearly a decade ago, leading to the widespread deployment of FPGAs in Microsoft's data centers for application and network acceleration. Project Brainwave began five years later, applying those FPGAs to accelerate DNN inference for Bing and later other Microsoft cloud services. FPGA flexibility has enabled the Brainwave architecture to evolve rapidly, keeping pace with rapid developments in the DNN model space. The low cost of updating FPGA-based designs also enables greater risk taking, facilitating innovations such as our Microsoft Floating Point (MSFP) data format. FPGAs with hardened support for MSFP will provide a new level of performance for Brainwave. These AI-optimized FPGAs also introduce a new point in the hardware spectrum between general-purpose devices and domain-specific accelerators. Going forward, a key challenge for accelerator architects will be finding the right balance between hardware specialization, hardware configurability, and software programmability.
 Bio: Steven K. Reinhardt is a Partner Hardware Engineering Manager in the Bing Platform Engineering group. His team leads the development and production deployment of the Brainwave FPGA-based DNN inference accelerator in support of Bing and Office 365. Prior to joining Microsoft, Steve was a Senior Fellow at AMD Research, where he led research on heterogeneous systems and high-performance networking. Before that, he was an Associate Professor in the EECS department at the University of Michigan. Steve has published over 50 refereed conference and journal articles. He was also a primary architect and developer of M5 (now gem5), a widely used open-source full-system architecture simulator. Steve received a Ph.D. in Computer Sciences from the University of Wisconsin-Madison, and is an IEEE Fellow and an ACM Distinguished Scientist.
Bio: Steven K. Reinhardt is a Partner Hardware Engineering Manager in the Bing Platform Engineering group. His team leads the development and production deployment of the Brainwave FPGA-based DNN inference accelerator in support of Bing and Office 365. Prior to joining Microsoft, Steve was a Senior Fellow at AMD Research, where he led research on heterogeneous systems and high-performance networking. Before that, he was an Associate Professor in the EECS department at the University of Michigan. Steve has published over 50 refereed conference and journal articles. He was also a primary architect and developer of M5 (now gem5), a widely used open-source full-system architecture simulator. Steve received a Ph.D. in Computer Sciences from the University of Wisconsin-Madison, and is an IEEE Fellow and an ACM Distinguished Scientist.Homepage
Inspecting Irregular Computation Patterns to Generate Fast Code
Abstract: Sparse matrix methods are at the heart of many scientific computations and data analytics codes. Sparse matrix kernels often dominate the overall execution time of many simulations. Further, the indirection from indexing and looping over the nonzero elements of a sparse data structure often limits the optimization of such codes. In this talk, I will introduce Sympiler, a domain-specific code generator that transforms computation patterns in sparse matrix methods for high-performance. Specifically, I will show how decoupling symbolic analysis from numerical manipulation will enable the automatic optimization of sparse codes. I will also demonstrate the application of symbolic analysis in accelerating quadratic program solvers.
 Bio: Maryam Mehri Dehnavi is an Assistant Professor in the Computer Science department at the University of Toronto and is the Canada Research Chair in parallel and distributed computing. Her research focuses on high-performance computing and domain-specific compiler design. Previously, she was an Assistant Professor at Rutgers University and a postdoctoral researcher at MIT. She received her Ph.D. from McGill University in 2013. Some of her recognitions include the Canada Research Chair award, the Ontario Early Researcher award, and the ACM SRC grand finale prize.
Bio: Maryam Mehri Dehnavi is an Assistant Professor in the Computer Science department at the University of Toronto and is the Canada Research Chair in parallel and distributed computing. Her research focuses on high-performance computing and domain-specific compiler design. Previously, she was an Assistant Professor at Rutgers University and a postdoctoral researcher at MIT. She received her Ph.D. from McGill University in 2013. Some of her recognitions include the Canada Research Chair award, the Ontario Early Researcher award, and the ACM SRC grand finale prize.Homepage
Transferable Deep Learning Surrogates for Solving PDEs
Abstract: Partial differential equations (PDEs) are ubiquitous in science and engineering to model physical phenomena. Notable PDEs are the Laplace and Navier-Stokes equations with numerous applications in fluid dynamics, electrostatics, and steady-state heat transfer. Solving such PDEs relies on numerical methods such as finite element, finite difference, and finite volume. While these methods are extremely powerful, they are also computationally expensive. Despite widespread efforts to improve the performance and scalability of solving these systems of PDEs, several problems remain intractable.
In this talk, we'll explore the potential of deep learning (DL)-based surrogates to both augment and replace numerical simulations. In the first part of the talk, we'll present two frameworks -- CFDNet and SURFNet, that couple simulations with a convolutional neural network to accelerate the convergence of the overall scheme without relaxing the convergence constraints of the physics solver. The second part of the talk will introduce another novel framework that leverages DL to build a transferable deep neural network surrogate that solves PDEs in unseen domains with arbitrary boundary conditions. We'll show that a DL model trained only once can be used forever without re-training to solve PDEs in large and complex domains with unseen sizes, shapes, and boundary conditions. Compared with the state-of-the-art physics-informed neural networks for solving PDEs, we demonstrate 1-3 orders of magnitude speedups while achieving comparable or better accuracy.
 Bio: Aparna Chandramowlishwaran is an Associate Professor at the University of California, Irvine, in the Department of Electrical Engineering and Computer Science. She received her Ph.D. in Computational Science and Engineering from Georgia Tech in 2013 and was a research scientist at MIT prior to joining UCI as an Assistant Professor in 2015. Her research lab, HPC Forge, aims at advancing computational science using high-performance computing and machine learning. She currently serves as the associate editor of the ACM Transactions on Parallel Computing.
Bio: Aparna Chandramowlishwaran is an Associate Professor at the University of California, Irvine, in the Department of Electrical Engineering and Computer Science. She received her Ph.D. in Computational Science and Engineering from Georgia Tech in 2013 and was a research scientist at MIT prior to joining UCI as an Assistant Professor in 2015. Her research lab, HPC Forge, aims at advancing computational science using high-performance computing and machine learning. She currently serves as the associate editor of the ACM Transactions on Parallel Computing.Homepage
Exploring Tools & Techniques for the Frontier Exascale System: Challenges vs Opportunities
Abstract: PIConGPU, an extremely scalable, heterogeneous, fully relativistic particle-in-cell (PIC) C++ code provides a modern simulation framework for laser-plasma physics and laser-matter interactions suitable for production-quality runs on large scale systems. This plasma physics application is fueled by alpaka abstraction library and incorporates openPMD-API enabling I/O libraries such as ADIOS2. Among many supercomputing systems, PIConGPU has been running on ORNL's Titan, Summit and is expected to run on the Exascale system, Frontier, that is being built as we speak. This talk will discuss some of the challenges, opportunities and potential solutions with respect to maintaining a performant portable code while migrating the same to Frontier.
 Bio: Sunita Chandrasekaran is an Assistant Professor with the Dept. of Computer and Information Sciences at the University of Delaware, USA. Her research interests span High Performance Computing, interdisciplinary science, machine learning and data science. Chandrasekaran has organized and served in the TPC of several conferences and workshops including SC, ISC, IPDPS, IEEE Cluster, CCGrid and WACCPD. She is currently an associated and subject area editor for IEEE TPDS, Elsevier's PARCO, FGCS and JPDC. She is a recipient of the 2016 IEEE-CS TCHPC Award for Excellence for Early Career Researchers in HPC. She received her Ph.D. in 2012 on Tools and Algorithms for High-Level Algorithm Mapping to FPGAs from the School of Computer Science and Engineering, Nanyang Technological University, Singapore.
Bio: Sunita Chandrasekaran is an Assistant Professor with the Dept. of Computer and Information Sciences at the University of Delaware, USA. Her research interests span High Performance Computing, interdisciplinary science, machine learning and data science. Chandrasekaran has organized and served in the TPC of several conferences and workshops including SC, ISC, IPDPS, IEEE Cluster, CCGrid and WACCPD. She is currently an associated and subject area editor for IEEE TPDS, Elsevier's PARCO, FGCS and JPDC. She is a recipient of the 2016 IEEE-CS TCHPC Award for Excellence for Early Career Researchers in HPC. She received her Ph.D. in 2012 on Tools and Algorithms for High-Level Algorithm Mapping to FPGAs from the School of Computer Science and Engineering, Nanyang Technological University, Singapore.Homepage
High Performance Computing: Beyond Moore's Law
Abstract: Supercomputer performance now exceeds that of the earliest computers by thirteen orders of magnitude, yet science still needs more than they provide. But with Dennard scaling and Moore's Law ending even as AI and HPC demand continued growth. Demand engenders supply, and ways to prolong the growth in supercomputing performance are at hand or on the horizon. Architectural specialization has returned, after a loss of system diversity in the Moore's law era; it provides a significant boost for computational science. And at the hardware level, the development by Cerebras of a viable wafer-scale compute platform has important ramifications. Other long-term possibilities, notably quantum computing, may eventually play a role.
Why wafer-scale? Real achieved performance in supercomputers (as opposed to the peak speed) is limited by the bandwidth and latency barriers --- memory and communication walls --- that impose delay when off-processor-chip data is needed, and it is needed all the time. By changing the scale of the chip by two orders of magnitude, we can pack a small, powerful, mini-supercomputer on one piece of silicon, and eliminate much of the off-chip traffic for applications that can fit in the available memory. The elimination of most off-chip communication also cuts the power per unit performance, a key parameter when total system power is capped, as it usually is.
Cerebras overcame technical problems concerning yield, packaging, cooling, and delivery of electrical power in order to make wafer-scale computing viable. The Cerebras second generation wafer has over 800,000 identical processing elements architected with features that support sparsity and power-efficient performance. For ML, algorithmic innovations such as conditional computations and model and data sparsity promise significant savings in memory and computation while preserving model capacity. Flexible hardware rather than dense matrix multiply is required to best exploit these algorithmic innovations. We will discuss the aspects of the architecture that meet that requirement.
 Bio: Rob Schreiber is a Distinguished Engineer at Cerebras Systems, Inc., where he works on architecture and programming of highly parallel systems for AI and science. Before Cerebras he taught at Stanford and RPI and worked at NASA, at startups, and at HP. Schreiber's research spans sequential and parallel algorithms for matrix computation, compiler optimization for parallel languages, and high performance computer design. With Moler and Gilbert, he developed the sparse matrix extension of Matlab. He created the NAS CG parallel benchmark. He was a designer of the High Performance Fortran language. Rob led the development at HP of a system for synthesis of custom hardware accelerators. He has help pioneer the exploitation of photonic signaling in processors and networks. He is an ACM Fellow, a SIAM Fellow, and was awarded, in 2012, the Career Prize from the SIAM Activity Group in Supercomputing.
Bio: Rob Schreiber is a Distinguished Engineer at Cerebras Systems, Inc., where he works on architecture and programming of highly parallel systems for AI and science. Before Cerebras he taught at Stanford and RPI and worked at NASA, at startups, and at HP. Schreiber's research spans sequential and parallel algorithms for matrix computation, compiler optimization for parallel languages, and high performance computer design. With Moler and Gilbert, he developed the sparse matrix extension of Matlab. He created the NAS CG parallel benchmark. He was a designer of the High Performance Fortran language. Rob led the development at HP of a system for synthesis of custom hardware accelerators. He has help pioneer the exploitation of photonic signaling in processors and networks. He is an ACM Fellow, a SIAM Fellow, and was awarded, in 2012, the Career Prize from the SIAM Activity Group in Supercomputing.
 Bio: Natalia Vasilieva is Director of Product, Machine Learning at Cerebras Systems, where she leads market, application, and algorithm analysis for ML use cases. She was a Senior Research Manager at HP Labs, where she led the Software and AI group, worked on performance characterization and modelling of deep learning workloads, fast Monte Carlo simulations, and systems software, programming paradigms, algorithms and applications for The HP memory-driven computing project. She was an associate professor at Saint Petersburg State University and a lecturer at the Saint Petersburg Computer Science Center, and holds a PhD in mathematics, computer science, and information technology from Saint Petersburg State University.
Bio: Natalia Vasilieva is Director of Product, Machine Learning at Cerebras Systems, where she leads market, application, and algorithm analysis for ML use cases. She was a Senior Research Manager at HP Labs, where she led the Software and AI group, worked on performance characterization and modelling of deep learning workloads, fast Monte Carlo simulations, and systems software, programming paradigms, algorithms and applications for The HP memory-driven computing project. She was an associate professor at Saint Petersburg State University and a lecturer at the Saint Petersburg Computer Science Center, and holds a PhD in mathematics, computer science, and information technology from Saint Petersburg State University.Homepage
Heterogeneous System Architectures: A Strategy to Use Diverse Components
Abstract: Current system architectures rely on a simple approach: one compute node design that is used across the entire system. This approach only supports heterogeneity at the node level. Compute nodes may involve a variety of devices but the system is otherwise homogeneous. This design simplifies scheduling applications and provides consistent expectations for the hardware that a job can exploit but often results in poor utilization of components. The wide range of emerging devices for AI and other domains necessitates a more heterogeneous system architecture that varies the compute node (or volume) types within a single job.
Lawrence Livermore National Laboratory (LLNL) is currently exploring such heterogeneous system architectures. These explorations include the use of novel hardware to accelerate AI models within larger applications and initial software solutions to overcome the challenges posed by heterogeneous system architectures. This talk will present a sampling of the novel software solutions that enable the heterogeneous system architecture as well as the systems that LLNL has currently deployed.
 Bio: As Chief Technology Officer (CTO) for Livermore Computing (LC) at Lawrence Livermore National Laboratory (LLNL), Bronis R. de Supinski formulates LLNL's large-scale computing strategy and oversees its implementation. He frequently interacts with supercomputing leaders and oversees many collaborations with industry and academia. Previously, Bronis led several research projects in LLNL's Center for Applied Scientific Computing. He earned his Ph.D. in Computer Science from the University of Virginia in 1998 and he joined LLNL in July 1998. In addition to his work with LLNL, Bronis is also a Professor of Exascale Computing at Queen's University of Belfast and an Adjunct Associate Professor in the Department of Computer Science and Engineering at Texas A&M University. Throughout his career, Bronis has won several awards, including the prestigious Gordon Bell Prize in 2005 and 2006, as well as two R&D 100s, including one for his leadership in the development of a novel scalable debugging tool.
Bio: As Chief Technology Officer (CTO) for Livermore Computing (LC) at Lawrence Livermore National Laboratory (LLNL), Bronis R. de Supinski formulates LLNL's large-scale computing strategy and oversees its implementation. He frequently interacts with supercomputing leaders and oversees many collaborations with industry and academia. Previously, Bronis led several research projects in LLNL's Center for Applied Scientific Computing. He earned his Ph.D. in Computer Science from the University of Virginia in 1998 and he joined LLNL in July 1998. In addition to his work with LLNL, Bronis is also a Professor of Exascale Computing at Queen's University of Belfast and an Adjunct Associate Professor in the Department of Computer Science and Engineering at Texas A&M University. Throughout his career, Bronis has won several awards, including the prestigious Gordon Bell Prize in 2005 and 2006, as well as two R&D 100s, including one for his leadership in the development of a novel scalable debugging tool.Homepage
TinyML and Efficient Deep Learning
Abstract: Today's AI is too big. Deep neural networks demand extraordinary levels of data and computation, and therefore power, for training and inference. This severely limits the practical deployment of AI in edge devices. We aim to improve the efficiency of neural network design. First, I'll present MCUNet that brings deep learning to IoT devices. MCUNet is a framework that jointly designs the efficient neural architecture (TinyNAS) and the light-weight inference engine (TinyEngine), enabling ImageNet-scale inference on micro-controllers that have only 1MB of Flash. Next I will introduce Once-for-All Network, an efficient neural architecture search approach, that can elastically grow and shrink the model capacity according to the target hardware resource and latency constraints. From inference to training, I'll present TinyTL that enables tiny transfer learning on-device, reducing the memory footprint by 7-13x. Finally, I will describe data-efficient GAN training techniques that can generate photo-realistic images using only 100 images, which used to require tens of thousands of images. We hope such TinyML techniques can make AI greener, faster, more efficient and more sustainable.
 Bio: Song Han is an assistant professor at MIT's EECS. He received his PhD degree from Stanford University. His research focuses on efficient deep learning computing. He proposed "deep compression" technique that can reduce neural network size by an order of magnitude without losing accuracy, and the hardware implementation "efficient inference engine" that first exploited pruning and weight sparsity in deep learning accelerators. His team's work on hardware-aware neural architecture search that bring deep learning to IoT devices was highlighted by MIT News, Wired, Qualcomm News, VentureBeat, IEEE Spectrum, integrated in PyTorch and AutoGluon, and received many low-power computer vision contest awards in flagship AI conferences (CVPR'19, ICCV'19 and NeurIPS'19). Song received Best Paper awards at ICLR'16 and FPGA'17, Amazon Machine Learning Research Award, SONY Faculty Award, Facebook Faculty Award, NVIDIA Academic Partnership Award. Song was named "35 Innovators Under 35" by MIT Technology Review for his contribution on "deep compression" technique that "lets powerful artificial intelligence (AI) programs run more efficiently on low-power mobile devices." Song received the NSF CAREER Award for "efficient algorithms and hardware for accelerated machine learning" and the IEEE "AIs 10 to Watch: The Future of AI" award.
Bio: Song Han is an assistant professor at MIT's EECS. He received his PhD degree from Stanford University. His research focuses on efficient deep learning computing. He proposed "deep compression" technique that can reduce neural network size by an order of magnitude without losing accuracy, and the hardware implementation "efficient inference engine" that first exploited pruning and weight sparsity in deep learning accelerators. His team's work on hardware-aware neural architecture search that bring deep learning to IoT devices was highlighted by MIT News, Wired, Qualcomm News, VentureBeat, IEEE Spectrum, integrated in PyTorch and AutoGluon, and received many low-power computer vision contest awards in flagship AI conferences (CVPR'19, ICCV'19 and NeurIPS'19). Song received Best Paper awards at ICLR'16 and FPGA'17, Amazon Machine Learning Research Award, SONY Faculty Award, Facebook Faculty Award, NVIDIA Academic Partnership Award. Song was named "35 Innovators Under 35" by MIT Technology Review for his contribution on "deep compression" technique that "lets powerful artificial intelligence (AI) programs run more efficiently on low-power mobile devices." Song received the NSF CAREER Award for "efficient algorithms and hardware for accelerated machine learning" and the IEEE "AIs 10 to Watch: The Future of AI" award.Homepage
Optimization of Data Movement for Convolutional Neural Networks
Abstract: Convolutional Neural Networks (CNNs) are central to Deep Learning. The optimization of CNNs has therefore received significant attention. Minimizing data movement is critical to performance optimization. This talk will address the minimization of data movement for CNNs in two scenarios. In the first part of the talk, the optimization of tile loop permutations and tile size selection will be discussed for executing CNNs on multicore CPUs. Most efforts on optimization of tiling for CNNs have either used heuristics or limited search over the huge design space. We show that a comprehensive design space exploration is feasible via analytical modeling. In the second part of the talk, communication minimization for executing CNNs on distributed systems will be discussed.
 Bio: Sadayappan is a Professor in the School of Computing at the University of Utah, with a joint appointment at Pacific Northwest National Laboratory. His primary research interests center around performance optimization and compiler/runtime systems for high-performance computing, with a special emphasis on optimization of tensor computations. Sadayappan is an IEEE Fellow.
Bio: Sadayappan is a Professor in the School of Computing at the University of Utah, with a joint appointment at Pacific Northwest National Laboratory. His primary research interests center around performance optimization and compiler/runtime systems for high-performance computing, with a special emphasis on optimization of tensor computations. Sadayappan is an IEEE Fellow.Homepage
Research with AIEngine and MLIR
Abstract: The Xilinx Versal devices include an array of AIEngine Vector-VLIW processor cores suitable for Machine Learning and DSP processing tasks. This talk will provide an overview of AIEngine-based devices and discuss how they are programmed. The talk will also present recent work to build open source tools for these devices based on MLIR to support a wide variety of high-level programming models.
 Bio: Stephen Neuendorffer is a Distinguished Engineer in the Xilinx Research Labs working on various aspects of system design for FPGAs. Previously, he was product architect of Xilinx Vivado HLS and co-authored a widely used textbook on HLS design for FPGAs. He received B.S. degrees in Electrical Engineering and Computer Science from the University of Maryland, College Park in 1998. He graduated with University Honors, Departmental Honors in Electrical Engineering, and was named the Outstanding Graduate in the Department of Computer Science. He received the Ph.D. degree from the University of California, Berkeley, in 2003, after being one of the key architects of Ptolemy II.
Bio: Stephen Neuendorffer is a Distinguished Engineer in the Xilinx Research Labs working on various aspects of system design for FPGAs. Previously, he was product architect of Xilinx Vivado HLS and co-authored a widely used textbook on HLS design for FPGAs. He received B.S. degrees in Electrical Engineering and Computer Science from the University of Maryland, College Park in 1998. He graduated with University Honors, Departmental Honors in Electrical Engineering, and was named the Outstanding Graduate in the Department of Computer Science. He received the Ph.D. degree from the University of California, Berkeley, in 2003, after being one of the key architects of Ptolemy II.Homepage
Towards Next-Generation Numerical Methods with Physics-Informed Neural Networks
Abstract: Physics-Informed Neural Networks (PINNs) have recently emerged as a powerful tool for solving scientific computing problems. PINNs can be effectively used for developing surrogate models, completing data assimilation and uncertainty quantification tasks, and solving ill-defined problems, e.g., problems without boundary conditions or a closure equation. An additional application of PINNs is a central topic for scientific computing: the development of numerical solvers of Partial Differential Equations (PDE). While the accuracy and performance of PINNs for solving PDEs directly are still relatively low compared to traditional numerical solvers, combining traditional methods and PINNs opens up the possibility of designing new hybrid numerical methods. This talk introduces how PINNs work, emphasizing the relation between PINN components and main ideas with classical numerical methods, such as Finite Element Methods, Krylov solvers, and quasi-MonteCarlo techniques. I present PINNs' features that make them amenable to use in combination with traditional solvers. I then outline opportunities for developing a new class of numerical methods combining classical and neural network solvers, providing results from initial experiments.
 Bio: I was born in Parma, Italy, in 1976. I studied in Torino, Italy, and Urbana-Champaign, Illinois, obtaining an MS and Ph.D. degree in Nuclear Engineering. Since 2012, I work at KTH Royal Institute of Technology, Sweden. I am now an associate professor. My research interest focuses on programming models and emerging computing paradigms.
Homepage
Bio: I was born in Parma, Italy, in 1976. I studied in Torino, Italy, and Urbana-Champaign, Illinois, obtaining an MS and Ph.D. degree in Nuclear Engineering. Since 2012, I work at KTH Royal Institute of Technology, Sweden. I am now an associate professor. My research interest focuses on programming models and emerging computing paradigms.
Homepage
Parallel Sparse Matrix Algorithms for Data Analysis and Machine Learning
Abstract: In addition to the traditional theory and experimental pillars of science, we are witnessing the emergence of three additional pillars, which are simulation, data analysis, and machine learning. All three recent pillars of science rely on computing but in different ways. Matrices, and sparse matrices in particular, play an outsized role in all three computing related pillars of science, which will be the topic of my talk.
I will first highlight some of the emerging use cases of sparse matrices in data analysis and machine learning. These include graph computations, graph representation learning, and computational biology. The rest of my talk will focus on new parallel algorithms for such modern computations on sparse matrices. These include the use of "masking" for filtering out undesired output entries in sparse-times-sparse and dense-times-dense matrix multiplication, new distributed-memory algorithms for sparse matrix times tall-skinny dense matrix multiplication, combinations of these algorithms, and subroutines of them.
 Bio: Aydın Buluç is a Staff Scientist and Principal Investigator at the Lawrence Berkeley National Laboratory (LBNL) and an Adjunct Assistant Professor of EECS at UC Berkeley. His research interests include parallel computing, combinatorial scientific computing, high performance graph analysis and machine learning, sparse matrix computations, and computational biology. Previously, he was a Luis W. Alvarez postdoctoral fellow at LBNL and a visiting scientist at the Simons Institute for the Theory of Computing. He received his PhD in Computer Science from the University of California, Santa Barbara in 2010 and his BS in Computer Science and Engineering from Sabanci University, Turkey in 2005. Dr. Buluç is a recipient of the DOE Early Career Award in 2013 and the IEEE TCSC Award for Excellence for Early Career Researchers in 2015. He was a founding associate editor of the ACM Transactions on Parallel Computing.
Bio: Aydın Buluç is a Staff Scientist and Principal Investigator at the Lawrence Berkeley National Laboratory (LBNL) and an Adjunct Assistant Professor of EECS at UC Berkeley. His research interests include parallel computing, combinatorial scientific computing, high performance graph analysis and machine learning, sparse matrix computations, and computational biology. Previously, he was a Luis W. Alvarez postdoctoral fellow at LBNL and a visiting scientist at the Simons Institute for the Theory of Computing. He received his PhD in Computer Science from the University of California, Santa Barbara in 2010 and his BS in Computer Science and Engineering from Sabanci University, Turkey in 2005. Dr. Buluç is a recipient of the DOE Early Career Award in 2013 and the IEEE TCSC Award for Excellence for Early Career Researchers in 2015. He was a founding associate editor of the ACM Transactions on Parallel Computing.Homepage
Building Digital Twins of the Earth for NVIDIA's Earth-2 Initiative
Abstract: NVIDIA is committed to helping address climate change. Recently our CEO announced the Earth-2 initiative, which aims to build digital twins of the Earth and a dedicated supercomputer, E-2, to power them. Two central goals of this initiative are to predict the disastrous impacts of climate change well in advance and to help develop strategies to mitigate and adapt to change.
Here we present our work on an AI weather forecast surrogate trained on ECMWF's ERA5 reanalysis dataset. The model, called FourCastNet, employs a patch-based Vision-Transformer with a Fourier Neural Operator mixer. FourCastNet produces short to medium range weather predictions of about two dozen physical fields at 25-km resolution that exceed the quality of all related deep learning-based techniques to date. FourCastNet is capable of accurately forecasting fast timescale variables such as the surface wind speed, precipitation, and atmospheric water vapor with important implications for wind energy resource planning, predicting extreme weather events such as tropical cyclones and atmospheric rivers, as well as extreme precipitation. We compare the forecast skill of FourCastNet with archived operational IFS model forecasts and find that the forecast skill of our purely data-driven model is remarkably close to that of the IFS model for forecast lead times of up to 8 days. Furthermore, it can produce a 10-day forecast in a fraction of a second on a single GPU.
The enormous speed and high accuracy of FourCastNet provides at least three major advantages over traditional forecasts: (i) real-time user interactivity and analysis; (ii) the potential for large forecast ensembles; and (iii) the ability to combine fast surrogates to form new coupled systems. Large ensembles can capture rare but highly impactful extreme weather events and better quantify the uncertainty of such events by providing more accurate statistics. The figure below shows results from FourCastNet in NVIDIA's interactive Omniverse environment. On the left we show atmospheric rivers making landfall in California in Feb, 2017. On the right is a forecast of hurricane Matthew from Sept 2016. By plugging AI surrogates into Omniverse, users can generate, visualize, and explore potential weather outcomes interactively.
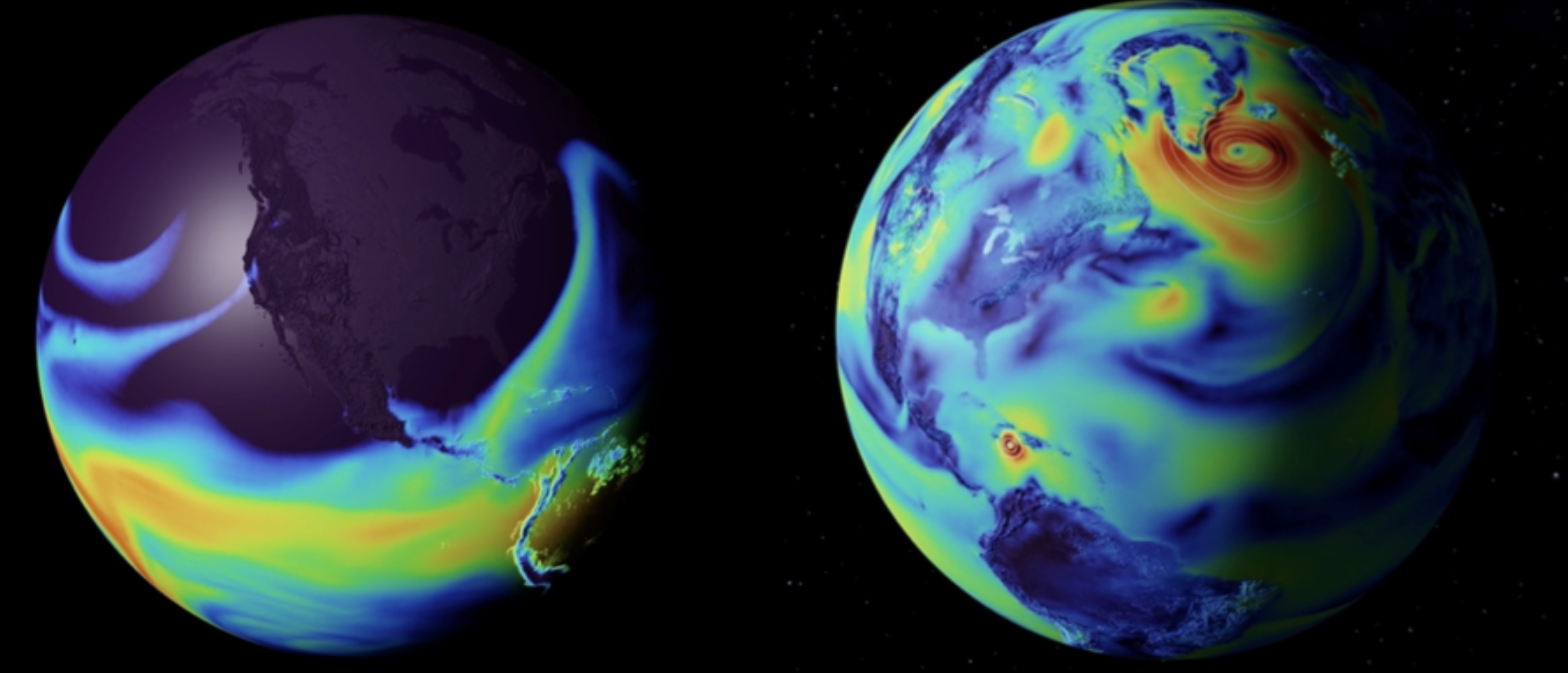
 Bio: Karthik Kashinath is a senior machine learning scientist and technologist at NVIDIA. He leads various ML initiatives for Earth System Science and CFD applications, including for NVIDIA's Earth-2 initiative aiming to build digital twins of the Earth. Before joining NVIDIA in August 2021, he was at NERSC, Lawrence Berkeley Lab, where he led various climate informatics and machine learning projects at the Big Data Center. He received his Bachelors from the Indian Institute of Technology - Madras, Masters from Stanford University, and PhD from the University of Cambridge. His background is in engineering and applied physics. His research uses the power of machine learning to accelerate scientific discovery in the complex chaotic systems of turbulence, weather, and climate science. A particular focus area is physics-informed machine learning to develop physically consistent, trustworthy, and robust machine learning models. When he is not in front of the computer he is hiking up mountains, swimming in lakes, or cooking up a storm.
Bio: Karthik Kashinath is a senior machine learning scientist and technologist at NVIDIA. He leads various ML initiatives for Earth System Science and CFD applications, including for NVIDIA's Earth-2 initiative aiming to build digital twins of the Earth. Before joining NVIDIA in August 2021, he was at NERSC, Lawrence Berkeley Lab, where he led various climate informatics and machine learning projects at the Big Data Center. He received his Bachelors from the Indian Institute of Technology - Madras, Masters from Stanford University, and PhD from the University of Cambridge. His background is in engineering and applied physics. His research uses the power of machine learning to accelerate scientific discovery in the complex chaotic systems of turbulence, weather, and climate science. A particular focus area is physics-informed machine learning to develop physically consistent, trustworthy, and robust machine learning models. When he is not in front of the computer he is hiking up mountains, swimming in lakes, or cooking up a storm.Language and Compiler Research for Heterogeneous Emerging Computing Systems
Abstract: Programming heterogeneous computing systems is still a daunting task that will become even more challenging with the advent of emerging, non Von-Neumann computer architectures. The so-called golden age of computer architecture thus must be accompanied by a, hopefully, golden age of research in compilers and programming languages. This talk discusses research along two fronts, namely, (1) on domain specific languages (DSLs) to hide complexity from non-expert programmers while passing richer information to compilers, and (2) on understanding the fundamental changes in emerging computing paradigms and their consequences for compilers. Concretely, we will talk about DSLs for physics simulations, compute-in-memory with emerging technologies, and current efforts in unifying intermediate representations with the MLIR compiler framework.
 Bio: Jeronimo Castrillon is a professor in the Department of Computer Science at the TU Dresden, where he is also affiliated with the Center for Advancing Electronics Dresden (CfAED). He is the head of the Chair for Compiler Construction, with research focus on methodologies, languages, tools and algorithms for programming complex computing systems. He received the Electronics Engineering degree from the Pontificia Bolivariana University in Colombia in 2004, his masters degree from the ALaRI Institute in Switzerland in 2006 and his Ph.D. degree (Dr.-Ing.) with honors from the RWTH Aachen University in Germany in 2013. In 2014, Prof. Castrillon co-founded Silexica GmbH/Inc, a company that provides programming tools for embedded multicore architectures, now with Xilinx/AMD.
Bio: Jeronimo Castrillon is a professor in the Department of Computer Science at the TU Dresden, where he is also affiliated with the Center for Advancing Electronics Dresden (CfAED). He is the head of the Chair for Compiler Construction, with research focus on methodologies, languages, tools and algorithms for programming complex computing systems. He received the Electronics Engineering degree from the Pontificia Bolivariana University in Colombia in 2004, his masters degree from the ALaRI Institute in Switzerland in 2006 and his Ph.D. degree (Dr.-Ing.) with honors from the RWTH Aachen University in Germany in 2013. In 2014, Prof. Castrillon co-founded Silexica GmbH/Inc, a company that provides programming tools for embedded multicore architectures, now with Xilinx/AMD.Homepage
Challenges of Scaling Deep Learning on HPC Systems
Abstract: Machine learning, and training deep learning in specific, are becoming one of the main workloads running on HPC systems. More so, the scientific computing community is increasingly adopting modern deep learning approaches to their workflows. When HPC practitioners attempt to scale a typical HPC workload, they are mostly challenged by a particular bottleneck. Scaling deep learning, on the other hand, can be challenged by different bottlenecks: memory capacity, communication, I/O, compute etc. In this talk we give an overview of the bottlenecks in scaling deep learning, and highlight efforts in addressing some of those bottlenecks: memory capacity and I/O.
 Bio: Mohamed Wahib is a team leader of the "High Performance Artificial Intelligence Systems Research Team" at RIKEN Center for Computational Science (R-CCS), Kobe, Japan. Prior to that he worked as is a senior scientist at AIST/TokyoTech Open Innovation Laboratory, Tokyo, Japan. He received his Ph.D. in Computer Science in 2012 from Hokkaido University, Japan. His research interests revolve around the central topic of high-performance programming systems, in the context of HPC and AI. He is actively working on several projects including high-level frameworks for programming traditional scientific applications, as well as high-performance AI.
Bio: Mohamed Wahib is a team leader of the "High Performance Artificial Intelligence Systems Research Team" at RIKEN Center for Computational Science (R-CCS), Kobe, Japan. Prior to that he worked as is a senior scientist at AIST/TokyoTech Open Innovation Laboratory, Tokyo, Japan. He received his Ph.D. in Computer Science in 2012 from Hokkaido University, Japan. His research interests revolve around the central topic of high-performance programming systems, in the context of HPC and AI. He is actively working on several projects including high-level frameworks for programming traditional scientific applications, as well as high-performance AI.Homepage
Co-Optimization of Computation and Data Layout to Optimize Data Movement
Abstract: Code generation and optimization for the diversity of current and future architectures must focus on reducing data movement to achieve high performance. How data is laid out in memory, and representations that compress data (e.g., reduced floating point precision) have a profound impact on data movement. Moreover, the cost of data movement in a program is architecture-specific, and consequently, optimizing data layout and data representation must be performed by a compiler once the target architecture is known. With this context in mind, this talk will provide examples of data layout and data representation optimizations, and call for integrating these data properties into code generation and optimization systems.
 Bio: Mary Hall is a Professor and Director of the School of Computing at University of Utah. She received a PhD in Computer Science from Rice University. Her research focus brings together compiler optimizations targeting current and future high-performance architectures on real-world applications. Hall's prior work has developed compiler techniques for exploiting parallelism and locality on a diversity of architectures: automatic parallelization for SMPs, superword-level parallelism for multimedia extensions, processing-in-memory architectures, FPGAs and more recently many-core CPUs and GPUs. Professor Hall is an IEEE Fellow, an ACM Distinguished Scientist and a member of the Computing Research Association Board of Directors. She actively participates in mentoring and outreach programs to encourage the participation of women and other groups underrepresented in computer science.
Bio: Mary Hall is a Professor and Director of the School of Computing at University of Utah. She received a PhD in Computer Science from Rice University. Her research focus brings together compiler optimizations targeting current and future high-performance architectures on real-world applications. Hall's prior work has developed compiler techniques for exploiting parallelism and locality on a diversity of architectures: automatic parallelization for SMPs, superword-level parallelism for multimedia extensions, processing-in-memory architectures, FPGAs and more recently many-core CPUs and GPUs. Professor Hall is an IEEE Fellow, an ACM Distinguished Scientist and a member of the Computing Research Association Board of Directors. She actively participates in mentoring and outreach programs to encourage the participation of women and other groups underrepresented in computer science.Homepage
Automating Distributed Heterogeneous Computing for Domain Experts
Abstract: Multiple simultaneous disruptions are currently under way in both hardware and software, as we consider the implications for future HPC systems. In hardware, "extreme heterogeneity" has become critical to sustaining cost and performance improvements after Moore's Law, but poses significant productivity challenges for developers. In software, the rise of large-scale AI and data analytics applications is being driven by domain experts from diverse backgrounds who demand the programmability that they have come to expect from high-level languages like Python. While current foundations for programming models, compilers, runtime systems, and debuggers have served us well for many decades, we now see signs of their limitations in the face of these disruptions. This talk makes a case for new approaches to enable productivity and programmability of future HPC systems for domain experts, and discusses recent approaches being explored in the Habanero Extreme Scale Software Research Laboratory. Preliminary results will be shared for the new compiler and runtime techniques being explored in our laboratory, including how we propose to respond to the challenge of automating distributed heterogeneous computing for Python-level domain experts.
 Bio: Vivek Sarkar is Chair of the School of Computer Science and the Stephen Fleming Chair for Telecommunications in the College of Computing at Georgia Institute of Technology. He conducts research in multiple aspects of programmability and productivity in parallel computing, including programming languages, compilers, runtime systems, and debuggers for parallel, heterogeneous, and high-performance computer systems.
Bio: Vivek Sarkar is Chair of the School of Computer Science and the Stephen Fleming Chair for Telecommunications in the College of Computing at Georgia Institute of Technology. He conducts research in multiple aspects of programmability and productivity in parallel computing, including programming languages, compilers, runtime systems, and debuggers for parallel, heterogeneous, and high-performance computer systems.Sarkar started his career in IBM Research after obtaining his Ph.D. from Stanford University, supervised by John Hennessy. His research projects at IBM include the PTRAN automatic parallelization system led by Fran Allen, the ASTI optimizer for IBM's XL Fortran product compilers, the open-source Jikes Research Virtual Machine for the Java language, and the X10 programming language developed in the DARPA HPCS program. He was a member of the IBM Academy of Technology during 1995-2007, and Senior Manager of the Programming Technologies Department at IBM Research during 2000-2007. After moving to academia, Sarkar has mentored over 30 Ph.D. students and postdoctoral researchers in the Habanero Extreme Scale Software Research Laboratory, first at Rice University since 2007, and now at Georgia Tech since 2017. Researchers in his lab have developed the Habanero-C/C++ and Habanero-Java programming systems for parallel, heterogeneous, and distributed platforms. While at Rice, Sarkar was the E.D. Butcher Chair in Engineering, served as Chair of the Department of Computer Science, created a new sophomore-level course on the fundamentals of parallel programming, as well as a three-course Coursera specialization on parallel, concurrent, and distributed programming.
Sarkar is an ACM Fellow and an IEEE Fellow. He has been serving as a member of the US Department of Energy's Advanced Scientific Computing Advisory Committee (ASCAC) since 2009, and is currently co-chair of the recently created CRA-Industry committee (after serving on the CRA Board for seven years). Sarkar is also the recipient of the 2020 ACM-IEEE CS Ken Kennedy Award.
Homepage
Self-Adjusting Networks
Abstract: The bandwidth and latency requirements of modern datacenter applications have led researchers to propose various datacenter topology designs using static, dynamic demand-oblivious (rotor), and/or dynamic demand-aware switches. However, given the diverse nature of datacenter traffic, there is little consensus about how these designs would fare against each other. In this talk, I will present the vision of self-adjusting networks: networks which are optimized towards, and "match", the traffic workload they serve. We will discuss information-theoretic metrics to quantify the structure in communication traffic as well as the achievable performance in datacenter networks matching their demands, present network design principles accordingly, and identify open research challenges. I will also show how the notions of self-adjusting networks and demand-aware graphs relate to classic optimization problems in theoretical computer science.
 Bio: Stefan Schmid is a Full Professor at the Technical University of Berlin, Germany, working part-time for the Fraunhofer Institute for Secure Information Technology (SIT). He is also a Principle Investigator of the Weizenbaum Institute for the Networked Society in Berlin. He obtained his diploma (MSc) in Computer Science at ETH Zurich in Switzerland (minor: micro/macro economics, internship: CERN) and did his PhD in the Distributed Computing Group led by Prof. Roger Wattenhofer, also at ETH Zurich. As a postdoc, he worked with Prof. Christian Scheideler at the Chair for Efficient Algorithms at the Technical University of Munich and at the Chair for Theory of Distributed Systems at the University of Paderborn, in Germany. From 2009 to 2015, Stefan Schmid was a senior research scientist at the Telekom Innovation Laboratories (T-Labs) and at TU Berlin in Germany (Internet Network Architectures group headed by Prof. Anja Feldmann). In 2013/14, he was an INP Visiting Professor at CNRS (LAAS), Toulouse, France, and in 2014, a Visiting Professor at Université catholique de Louvain (UCL), Louvain-la-Neuve, Belgium. From 2015 to 2018, Stefan Schmid was a (tenured) Associate Professor in the Distributed, Embedded and Intelligent Systems group at Aalborg University, Denmark, and from 2018 to 2021, a Full Professor at the Faculty of Computer Science at the University of Vienna, Austria. In 2022, Stefan Schmid was a Fellow at the Israel Institute for Advanced Studies (IIAS) in Jerusalem, Israel.
Bio: Stefan Schmid is a Full Professor at the Technical University of Berlin, Germany, working part-time for the Fraunhofer Institute for Secure Information Technology (SIT). He is also a Principle Investigator of the Weizenbaum Institute for the Networked Society in Berlin. He obtained his diploma (MSc) in Computer Science at ETH Zurich in Switzerland (minor: micro/macro economics, internship: CERN) and did his PhD in the Distributed Computing Group led by Prof. Roger Wattenhofer, also at ETH Zurich. As a postdoc, he worked with Prof. Christian Scheideler at the Chair for Efficient Algorithms at the Technical University of Munich and at the Chair for Theory of Distributed Systems at the University of Paderborn, in Germany. From 2009 to 2015, Stefan Schmid was a senior research scientist at the Telekom Innovation Laboratories (T-Labs) and at TU Berlin in Germany (Internet Network Architectures group headed by Prof. Anja Feldmann). In 2013/14, he was an INP Visiting Professor at CNRS (LAAS), Toulouse, France, and in 2014, a Visiting Professor at Université catholique de Louvain (UCL), Louvain-la-Neuve, Belgium. From 2015 to 2018, Stefan Schmid was a (tenured) Associate Professor in the Distributed, Embedded and Intelligent Systems group at Aalborg University, Denmark, and from 2018 to 2021, a Full Professor at the Faculty of Computer Science at the University of Vienna, Austria. In 2022, Stefan Schmid was a Fellow at the Israel Institute for Advanced Studies (IIAS) in Jerusalem, Israel.Since 2021, he is a Council and Board member of the European Association of Theoretical Computer Science (EATCS) and also serves as the Editor-in-Chief of the Bulletin of the EATCS. Since 2019 Stefan Schmid is an Editor of IEEE/ACM Transactions on Networking (ToN). From 2015 to 2021, he was the Editor of the Distributed Computing Column of the Bulletin of the EATCS, and from 2016 to 2019, an Associate Editor of IEEE Transactions on Network and Service Management (TNSM). Stefan Schmid received the IEEE Communications Society ITC Early Career Award 2016 and acquired several major grants including an ERC Consolidator Grant, various other EU grants (e.g., STREP and IP projects) and national grants (e.g., three FWF projects), a German-Israeli GIF grant, a Villum Fonden grant, a WWTF grant, and various German grants (e.g., from BSI and BMBF). In 2015, he co-founded the startup company Stacktile supported by Germany's EXIST program, and in 2020, he helped establish the Vienna Cybersecurity and Privacy Research Center (ViSP) for which he also served in the executive board. Stefan Schmid's research interests revolve around the fundamental and algorithmic problems of networked and distributed systems.
Homepage
Next-generation Networks for Machine Learning
Abstract: The ever-growing demand for more accurate machine learning models has resulted in a steady increase in dataset and model sizes of deep neural networks (DNNs). Although hardware accelerators have provided a significant amount of speed-up, today's DNN models can still take days and even weeks to train mainly because conventional datacenter networks are becoming a bottleneck for distributed DNN training workloads. In this talk, I will discuss two techniques to accelerate DNN training workloads. First, I will present a novel optical fabric that co-optimizes the network topology and parallelization strategy for DNN clusters. Second, I will argue that fair-sharing, the holy grail of congestion control algorithms for decades, is not necessarily a desirable property in DNN training clusters and propose a scheduling technique that carefully places jobs on network links to avoid bandwidth sharing.
 Bio: Manya Ghobadi is an associate professor in the EECS department at MIT. Her research spans different areas in computer networks, focusing on optical reconfigurable networks, networks for machine learning, and high-performance cloud infrastructure. Her work has been recognized by the Sloan Fellowship in Computer Science, NSF CAREER award, Optica Simmons Memorial Speakership award, best paper award at the Machine Learning Systems (MLSys) conference, as well as the best dataset, and best paper awards at the ACM Internet Measurement Conference (IMC). Manya received her Ph.D. from the University of Toronto and spent a few years at Microsoft Research and Google prior to joining MIT.
Bio: Manya Ghobadi is an associate professor in the EECS department at MIT. Her research spans different areas in computer networks, focusing on optical reconfigurable networks, networks for machine learning, and high-performance cloud infrastructure. Her work has been recognized by the Sloan Fellowship in Computer Science, NSF CAREER award, Optica Simmons Memorial Speakership award, best paper award at the Machine Learning Systems (MLSys) conference, as well as the best dataset, and best paper awards at the ACM Internet Measurement Conference (IMC). Manya received her Ph.D. from the University of Toronto and spent a few years at Microsoft Research and Google prior to joining MIT.Homepage
Heterogeneous Serverless Computing
Abstract: The high performance computing is evolving rapidly, shaped by the confluence of three trends: a) traditional simulation and modeling workloads are converging with massive data analytic and AI/ML workflows; b) the efficiency of special purpose heterogeneous hardware is increasing; and c) the demand for flexible delivery models that blend traditional on-premises deployments with cloud-like as-a-service models continues to grow. Heterogeneity is driven by the end of Moore's Law, growth of data, and by the emergence of broad AI adoption that is well-suited for special-purpose hardware. To date, serverless computing abstracts the complexity of the underlying infrastructure by leveraging homogeneity and is motivated by simplified DevOps experience for new composable and scalable applications. Delivering the efficiency of heterogeneity, the productivity of serverless, and the granularity of Functions-as-a-Service demands a new architecture.
The Heterogeneous Serverless Computing (HSC) aims to enable development and delivery of HPC, HPDA, and AI (H2A) workloads with the ease and efficiency of the Cloud and with higher scale and more fluidity than supercomputers. HSC is a software-hardware co-designed infrastructure supporting H2A workflow execution economically and securely at fine granularity using Functions as a Service (FaaS). HSC targets the changeover evolution to H2A workflows with flexible consumption models, the edge-to-exascale deployment, and embraces a more maintainable, scalable, and re-usable development model. We focus on innovative uses of accelerators, such as in SmartNICs and Fabric Attached Memories, to improve performance of H2A applications and efficiency of hardware, but without compromising ease of development.
 Bio: Dejan Milojicic is a distinguished technologist at Hewlett Packard Labs, Milpitas, CA. He leads research on Future Architectures and is the Principal Investigator of the Heterogeneous Serverless Computing that spans all Hewlett Packard Labs. Earlier he has led the software of the Dot Product Engine, an in-memory AI accelerator. In his lengthy HP(E) career, he contributed to numerous research efforts spanning software, distributed computing, systems management, and HPC. Dejan led large industry-government-academia collaborations, such as Open Cirrus for the HPC in Cloud program and New Operating System for The Machine program. Dejan has written over 200 papers, 2 books and 79 patents. Dejan is an IEEE Fellow, ACM Distinguished Engineer, and HKN and USENIX member. Dejan was on 8 PhD thesis committees, and he mentored over 50 interns. He founded and taught Cloud Management class at San Jose State University.
Bio: Dejan Milojicic is a distinguished technologist at Hewlett Packard Labs, Milpitas, CA. He leads research on Future Architectures and is the Principal Investigator of the Heterogeneous Serverless Computing that spans all Hewlett Packard Labs. Earlier he has led the software of the Dot Product Engine, an in-memory AI accelerator. In his lengthy HP(E) career, he contributed to numerous research efforts spanning software, distributed computing, systems management, and HPC. Dejan led large industry-government-academia collaborations, such as Open Cirrus for the HPC in Cloud program and New Operating System for The Machine program. Dejan has written over 200 papers, 2 books and 79 patents. Dejan is an IEEE Fellow, ACM Distinguished Engineer, and HKN and USENIX member. Dejan was on 8 PhD thesis committees, and he mentored over 50 interns. He founded and taught Cloud Management class at San Jose State University.Dejan was president of the IEEE Computer Society, IEEE presidential candidate, editor-in-chief of IEEE Computing Now and IEEE Distributed Systems Online and he has served and continues to serve on many editorial boards, technical program committees and steering committees. Previously, Dejan worked in the OSF Research Institute, Cambridge, MA and Institute "Mihajlo Pupin", Belgrade, Serbia. He contributed to novel systems software and parallel and distributed systems that were deployed throughout Europe. Dejan received his Ph.D. from the University of Kaiserslautern, Germany; and his MSc/BSc from Belgrade University, Serbia.
Homepage
AI Engine Architecture: Data Movement, Synchronization, Reconfiguration & Application Mapping
Abstract: AI Engine (AIE) is an array of vector processors developed by AMD/Xilinx. AIE is part of both the Xilinx Versal 7nm family of devices and next-gen AMD APU devices. This architecture is composed of a 2D array of tiles, where each compute tile includes a VLIW SIMD vector processor, scratchpad memory, data movement engines and streaming interconnect. Target applications include machine learning inference in datacentre, automotive and edge, as well as wireless (5G) acceleration. In this talk, David will present an overview of the architecture and then go into details on data movement, synchronization, reconfiguration, and application mapping onto hardware.
 Bio: David is a computer architect with AMD, working on defining the AI Engine (AIE) architecture. He has an undergraduate degree in Computational Physics from TCD and a PhD in High-Performance Heterogeneous Computing (UCD). In 2014 he joined the Xilinx Research Labs in Dublin and since then he has been working on the AIE architecture. In 2018 he moved from the Research Labs to the Central Products Group to continue working on the AIE project and is now part of AMD since the acquisition of Xilinx. Currently David is a Principal Member Technical Staff - Computer Architecture and is leading a team delivering next-generation AIE Architecture Specification, simulation, and validation.
Bio: David is a computer architect with AMD, working on defining the AI Engine (AIE) architecture. He has an undergraduate degree in Computational Physics from TCD and a PhD in High-Performance Heterogeneous Computing (UCD). In 2014 he joined the Xilinx Research Labs in Dublin and since then he has been working on the AIE architecture. In 2018 he moved from the Research Labs to the Central Products Group to continue working on the AIE project and is now part of AMD since the acquisition of Xilinx. Currently David is a Principal Member Technical Staff - Computer Architecture and is leading a team delivering next-generation AIE Architecture Specification, simulation, and validation.Homepage
Innovating the Next Discontinuity
Abstract: A growing number of classical HPC applications - modeling and simulation applications - are bottlenecked due to insufficient memory bandwidth. At the same time, AI applications, which are forming an increasingly important part of HPC, and compute in general, are often bottlenecked because of insufficient communication (node to node) bandwidth. In addition, the ability to leverage efficient accelerator cycles for both types of applications is key towards continuing the exponential growth for post-exascale computing. In this talk I will describe the key trends identified above, and discuss the research we are undertaking to design the hardware and software architecture for HPC and AI applications to obtain the next level of exponential increase in performance. I will suggest a path forward based on leveraging tightly integrating memory and compute, called Memory Couple Compute, and describe the interesting design space that needs to be considered to make this architecture a reality. This capability has the potential to be the next discontinuity in HPC and AI.
 Bio: Dr. Robert W. Wisniewski is a Senior Vice President, Chief Architect of HPC, and the Head of Samsung's SAIT Systems Architecture Lab. He is an ACM Distinguished Scientist and IEEE Senior Member. The System Architecture Lab is innovating technology to overcome the memory and communication walls for HPC and AI applications. He has published over 80 papers in the area of high performance computing, computer systems, and system performance, has filed over 60 patents with 46 issued, has an h-index of 41 with over 7100 citations, and has given over 78 external invited presentations. Prior to joining Samsung, he was an Intel Fellow and CTO and Chief Architect for High Performance Computing at Intel. He was the technical lead and PI for Aurora, the supercomputer to be delivered to Argonne National Laboratory that will achieve greater than an exaflop of computation. He was also the lead architect for Intel's cohesive and comprehensive software stack that was used to seed OpenHPC, and served on the OpenHPC governance board as chairman. Before Intel, he was the chief software architect for Blue Gene Research and manager of the Blue Gene and Exascale Research Software Team at the IBM T.J. Watson Research Facility, where he was an IBM Master Inventor and led the software effort on Blue Gene/Q, which received the National Medal of Technology and Innovation, was the most powerful computer in the world in June 2012, and occupied 4 of the top 10 positions on the Top 500 list.
Bio: Dr. Robert W. Wisniewski is a Senior Vice President, Chief Architect of HPC, and the Head of Samsung's SAIT Systems Architecture Lab. He is an ACM Distinguished Scientist and IEEE Senior Member. The System Architecture Lab is innovating technology to overcome the memory and communication walls for HPC and AI applications. He has published over 80 papers in the area of high performance computing, computer systems, and system performance, has filed over 60 patents with 46 issued, has an h-index of 41 with over 7100 citations, and has given over 78 external invited presentations. Prior to joining Samsung, he was an Intel Fellow and CTO and Chief Architect for High Performance Computing at Intel. He was the technical lead and PI for Aurora, the supercomputer to be delivered to Argonne National Laboratory that will achieve greater than an exaflop of computation. He was also the lead architect for Intel's cohesive and comprehensive software stack that was used to seed OpenHPC, and served on the OpenHPC governance board as chairman. Before Intel, he was the chief software architect for Blue Gene Research and manager of the Blue Gene and Exascale Research Software Team at the IBM T.J. Watson Research Facility, where he was an IBM Master Inventor and led the software effort on Blue Gene/Q, which received the National Medal of Technology and Innovation, was the most powerful computer in the world in June 2012, and occupied 4 of the top 10 positions on the Top 500 list.Homepage
Democratizing Deep Learning with DeepHyper
Abstract: Scientific data sets are diverse and often require data-set-specific deep neural network (DNN) models. Nevertheless, designing high-performing DNN architecture for a given data set is an expert-driven, time-consuming, trial-and-error manual task. To that end, we have developed DeepHyper [1], a software package that uses scalable neural architecture and hyperparameter search to automate the design and development of DNN models for scientific and engineering applications. In this talk, we will present our recent work on an automated approach for generating an ensemble of DNNs with DeepHyper at scale and using them for estimating data (aleatoric) and model (epistemic) uncertainties for a wide range of scientific applications.
[1] DeepHyper
 Bio: Prasanna Balaprakash is a computer scientist with a joint appointment in the Mathematics and Computer Science Division and the Leadership Computing Facility at Argonne National Laboratory. His research work spans the areas of artificial intelligence, machine learning, optimization, and high-performance computing. He is a recipient of the U.S. Department of Energy 2018 Early Career Award. Prior to Argonne, he worked as a Chief Technology Officer at Mentis Sprl, a machine learning startup in Brussels, Belgium. He received his PhD from CoDE-IRIDIA, Université Libre de Bruxelles, Brussels, Belgium, where he was a recipient of European Commission’s Marie Curie and Belgian F.R.S-FNRS Aspirant fellowships.
Bio: Prasanna Balaprakash is a computer scientist with a joint appointment in the Mathematics and Computer Science Division and the Leadership Computing Facility at Argonne National Laboratory. His research work spans the areas of artificial intelligence, machine learning, optimization, and high-performance computing. He is a recipient of the U.S. Department of Energy 2018 Early Career Award. Prior to Argonne, he worked as a Chief Technology Officer at Mentis Sprl, a machine learning startup in Brussels, Belgium. He received his PhD from CoDE-IRIDIA, Université Libre de Bruxelles, Brussels, Belgium, where he was a recipient of European Commission’s Marie Curie and Belgian F.R.S-FNRS Aspirant fellowships.Homepage
Follow the Data: Memory-Centric Designs for Modern Datacenters
Abstract: Memory has passed compute as the most critical determiner of system performance, as well as the largest component of cost. However, decisions about memory architecture are often left as an afterthought or decided by "rules of thumb" or "zeitgeist" instead of the quantitative/analytical approaches common in computer architecture.
In this talk, data-driven approaches for setting direction in memory architectures will be explored through the lens of two different system-level memory problems: Exascale supercomputing and Cloud memory disaggregation.
 Bio: Dr. Daniel Ernst is currently a Principal Architect in Microsoft's Azure Hardware Architecture team, which is responsible for long-range technology pathfinding for future Azure Cloud systems. Within AHA, Dan leads the team responsible for future memory systems. This team investigates future architecture directions for Azure and serves as the primary architecture contact point in technical relationships with compute, memory, and device partners, as well as the primary driver of Microsoft’s memory standards activity.
Prior to joining Microsoft, Dan spent 10 years at Cray/HPE, most recently as a Distinguished Technologist in the HPC Advanced Technology team. While at Cray, Dan led multiple customer-visible collaborative pathfinding investigations into future HPC architectures and was part of the team that architected the Department of Energy’s Frontier and El Capitan Exascale systems.
Dan has served as part of multiple industry standards bodies throughout his career, including JEDEC, the CXL and CCIX consortia, and as a founding Board of Directors member of the Gen-Z Consortium.
Dan received his Ph.D. in Computer Science and Engineering from the University of Michigan, where he studied high-performance, low-power, and fault-tolerant microarchitectures. He also holds an MSE from Michigan and a BS in Computer Engineering from Iowa State University.
Bio: Dr. Daniel Ernst is currently a Principal Architect in Microsoft's Azure Hardware Architecture team, which is responsible for long-range technology pathfinding for future Azure Cloud systems. Within AHA, Dan leads the team responsible for future memory systems. This team investigates future architecture directions for Azure and serves as the primary architecture contact point in technical relationships with compute, memory, and device partners, as well as the primary driver of Microsoft’s memory standards activity.
Prior to joining Microsoft, Dan spent 10 years at Cray/HPE, most recently as a Distinguished Technologist in the HPC Advanced Technology team. While at Cray, Dan led multiple customer-visible collaborative pathfinding investigations into future HPC architectures and was part of the team that architected the Department of Energy’s Frontier and El Capitan Exascale systems.
Dan has served as part of multiple industry standards bodies throughout his career, including JEDEC, the CXL and CCIX consortia, and as a founding Board of Directors member of the Gen-Z Consortium.
Dan received his Ph.D. in Computer Science and Engineering from the University of Michigan, where he studied high-performance, low-power, and fault-tolerant microarchitectures. He also holds an MSE from Michigan and a BS in Computer Engineering from Iowa State University.
Homepage
HPC and AI/ML: A Synergistic Relationship
Abstract: The rapid increase in memory capacity and computational power of modern architectures, especially accelerators, in large data centers and supercomputers has led to a frenzy in training extremely large deep neural networks. However, efficient use of large parallel resources for extreme-scale deep learning requires scalable algorithms coupled with high-performing implementations on such machines. In this talk, I will first present AxoNN, a parallel deep learning framework that exploits asynchrony and message-driven execution to optimize work scheduling and communication, which are often critical bottlenecks in achieving high performance. I will also discuss how neural network properties can be exploited for different systems-focused optimizations. On the other hand, recent advances in machine learning approaches are driving scientific discovery across many disciplines, including computer systems and high performance computing. AI/ML can be used to explore the vast quantities of system monitoring data being collected on HPC systems. I will also present a few examples of using data-driven ML models for performance modeling, forecasting and code generation to highlight how the fields of HPC and AI/ML are coming together, and can help each other.
 Bio: Abhinav Bhatele is an associate professor in the department of computer science, and director of the Parallel Software and Systems Group at the University of Maryland, College Park. His research interests are broadly in systems and networks, with a focus on parallel computing and large-scale data analytics. He has published research in parallel programming models and runtimes, network design and simulation, applications of machine learning to parallel systems, parallel deep learning, and on analyzing/visualizing, modeling and optimizing the performance of parallel software and systems. Abhinav has received best paper awards at Euro-Par 2009, IPDPS 2013 and IPDPS 2016. He was selected as a recipient of the IEEE TCSC Young Achievers in Scalable Computing award in 2014, the LLNL Early and Mid-Career Recognition award in 2018, and the NSF CAREER award in 2021.
Abhinav received a B.Tech. degree in Computer Science and Engineering from I.I.T. Kanpur, India in May 2005, and M.S. and Ph.D. degrees in Computer Science from the University of Illinois at Urbana-Champaign in 2007 and 2010 respectively. He was a post-doc and later computer scientist in the Center for Applied Scientific Computing at Lawrence Livermore National Laboratory from 2011-2019. Abhinav is an associate editor of the IEEE Transactions on Parallel and Distributed Systems (TPDS). He is one of the General Chairs of IEEE Cluster 2022, and Research Papers Chair of ISC 2023.
Bio: Abhinav Bhatele is an associate professor in the department of computer science, and director of the Parallel Software and Systems Group at the University of Maryland, College Park. His research interests are broadly in systems and networks, with a focus on parallel computing and large-scale data analytics. He has published research in parallel programming models and runtimes, network design and simulation, applications of machine learning to parallel systems, parallel deep learning, and on analyzing/visualizing, modeling and optimizing the performance of parallel software and systems. Abhinav has received best paper awards at Euro-Par 2009, IPDPS 2013 and IPDPS 2016. He was selected as a recipient of the IEEE TCSC Young Achievers in Scalable Computing award in 2014, the LLNL Early and Mid-Career Recognition award in 2018, and the NSF CAREER award in 2021.
Abhinav received a B.Tech. degree in Computer Science and Engineering from I.I.T. Kanpur, India in May 2005, and M.S. and Ph.D. degrees in Computer Science from the University of Illinois at Urbana-Champaign in 2007 and 2010 respectively. He was a post-doc and later computer scientist in the Center for Applied Scientific Computing at Lawrence Livermore National Laboratory from 2011-2019. Abhinav is an associate editor of the IEEE Transactions on Parallel and Distributed Systems (TPDS). He is one of the General Chairs of IEEE Cluster 2022, and Research Papers Chair of ISC 2023.
Homepage
A chiplet based generative inference architecture with block floating point datatypes
Abstract: The advent of large transformer based language models (BERT, GPT3, ChatGPT, Lamda, Switch) for Natural Language Processing (NLP) and their growing explosive use across Generative AI business and consumer applications has made it imperative for AI accelerated computing solutions to provide an order of magnitude improvements in efficiency. We will discuss a modular, chiplet based spatial CGRA-like architecture optimized for generative inference with a generalized framework for the successful implementation of deep RL-based mappers in compilers for spatial and temporal architectures. We’ll present results for weight and activation quantization in block floating point formats, building on GPTQ and SmoothQuant, and their support in PyTorch. To reduce KV cache size and bandwidth, we’ll present an extension to EL-attention.
 Bio: Sudeep Bhoja is the co-founder and CTO of d-Matrix focused on Generative AI inference accelerators using in-memory computing, chiplets and scale out interconnects. Previously he was Chief Technology Officer, Datacenter Business Unit at Inphi/Marvell. He brings with him more than 20 years of experience in defining and architecting groundbreaking products in the semiconductor industry. Prior to Inphi, he was Technical Director in the Infrastructure and Networking Group at Broadcom. He was also Chief Architect of a startup, Big Bear Networks, a mixed-signal networking IC & optical transceiver company. Sudeep also held R&D positions at Lucent Technologies and Texas Instruments working on Digital Signal Processors. He is the named inventor of over 40 pending and approved patents.
Bio: Sudeep Bhoja is the co-founder and CTO of d-Matrix focused on Generative AI inference accelerators using in-memory computing, chiplets and scale out interconnects. Previously he was Chief Technology Officer, Datacenter Business Unit at Inphi/Marvell. He brings with him more than 20 years of experience in defining and architecting groundbreaking products in the semiconductor industry. Prior to Inphi, he was Technical Director in the Infrastructure and Networking Group at Broadcom. He was also Chief Architect of a startup, Big Bear Networks, a mixed-signal networking IC & optical transceiver company. Sudeep also held R&D positions at Lucent Technologies and Texas Instruments working on Digital Signal Processors. He is the named inventor of over 40 pending and approved patents.
Homepage
Realizing Petabit/s IO and sub-pJ/bit System-wide Communication with Silicon Photonics
Abstract: High-performance systems are increasingly bottlenecked by the energy and communications costs of interconnecting numerous compute and memory resources. Integrated silicon photonics offer the opportunity of embedding optical connectivity that directly delivers high off-chip communication bandwidth densities with low power consumption. Our recent work has shown how integrated silicon photonics with comb-driven dense wavelength-division multiplexing can scale to realize Pb/s chip escape bandwidths with sub-picojoule/bit energy consumption. Beyond alleviating the bandwidth/energy bottlenecks, embedded photonics can enable new architectures that leverage the distance independence of optical transmission with flexible connectivity tailored to accelerate distributed ML applications.
 Bio: Keren Bergman is the Charles Batchelor Professor of Electrical Engineering at Columbia University where she also serves as the Faculty Director of the Columbia Nano Initiative. Prof. Bergman received the B.S. from Bucknell University in 1988, and the M.S. in 1991 and Ph.D. in 1994 from M.I.T. all in Electrical Engineering. At Columbia, Bergman leads the Lightwave Research Laboratory encompassing multiple cross-disciplinary programs at the intersection of computing and photonics. Bergman serves on the Leadership Council of the American Institute of Manufacturing (AIM) Photonics leading projects that support the institute’s silicon photonics manufacturing capabilities and Datacom applications. She is the recipient of the IEEE Photonics Engineering Award and is a Fellow of Optica and IEEE.
Bio: Keren Bergman is the Charles Batchelor Professor of Electrical Engineering at Columbia University where she also serves as the Faculty Director of the Columbia Nano Initiative. Prof. Bergman received the B.S. from Bucknell University in 1988, and the M.S. in 1991 and Ph.D. in 1994 from M.I.T. all in Electrical Engineering. At Columbia, Bergman leads the Lightwave Research Laboratory encompassing multiple cross-disciplinary programs at the intersection of computing and photonics. Bergman serves on the Leadership Council of the American Institute of Manufacturing (AIM) Photonics leading projects that support the institute’s silicon photonics manufacturing capabilities and Datacom applications. She is the recipient of the IEEE Photonics Engineering Award and is a Fellow of Optica and IEEE.
Homepage
HPVM: Performance, Programmability and Retargetability for Heterogeneous Parallel Systems
Abstract: Heterogeneous parallel systems are becoming increasingly prevalent in today's mobile devices and low-energy edge computing products, like smart cameras, mobile robots, AR/VR headsets, and others. These heterogeneous systems deliver orders-of-magnitude power-performance benefits compared with multicore CPUs, but are notoriously difficult to program, even for computing experts. Moreover, the diverse and fast-evolving instruction sets for both CPUs with complex vector, matrix and tensor architectures and for specialized accelerators are difficult to target from retargetable compiler systems like LLVM and GCC. The broad goal of the Heterogeneous Parallel Virtual Machine (HPVM) project is to enable both expert and non-expert application developers to be able to program heterogeneous parallel systems while achieving good performance and remaining no more difficulut to program than traditional parallel systems. HPVM is a highly retargetable compiler infrastructure that can compile different parallel languages to a wide range of hardware targets, including diverse CPUs, GPUs, FPGAs, fixed-function accelerators, and programmable machine learning accelerators. In this talk, I will describe two broad aspects of the HPVM project. The first is on enabling ``hardware-agnostic programming'' (a term we will explain more carefully) with good performance on diverse heterogeneous hardware targets, by using a combination of compiler optimizations, autotuning and design space exploration. The second is on automatically generating highly retargetable, yet very high performance, code generators for vector and matrix architectures. Given the vendor-defined pseudocode specification of one or more target ISAs, we automatically generate AutoLLVM IR, which consists of (formally defined) language-independent and target-independent LLVM IR instructions to support those ISAs. A Halide language compiler implemented fully automatically using AutoLLVM for both x86+AVX-512 and HVX, given only a formal semantics of the Halide front-end IR, is able to outperform a mature, well-tuned production compiler for Halide on both X86 and HVX across a wide range of benchmarks.
 Bio: Vikram Adve received his B.Tech degree in Electrical Engineering from IIT Bombay and his MS and PhD degrees in Computer Science from the University of Wisconsin-Madision. At present, he is the Donald B. Gillies Professor of Computer Science at the University of Illinois at Urbana-Champaign and a Professor of Electrical and Computer Engineering. Adve’s research interests lie in developing and using compiler techniques to improve the performance, programmability and energy-efficiency of computer systems. Adve’s current research focuses mainly on compiler and system support for heterogeneous edge computing. Adve and his Ph.D. student, Chris Lattner, co-designed the LLVM Compiler Infrastructure, which is widely used in industry today, including most mobile and desktop apps for Apple devices, and is also a popular system for compiler research. Adve, Lattner and Evan Cheng received the ACM Software System Award in 2012 for co-developing LLVM. One of Adve’s Ph.D. students, Robert Bocchino, won the 2010 ACM SIGPLAN Outstanding Dissertation Award and another student, John Criswell, won Honorable Mentions for both the 2014 ACM SIGOPS Dennis M. Ritchie Doctoral Dissertation Award and the 2014 ACM Doctoral Dissertation Award. Adve is a Fellow of the ACM and was named a University Scholar at the University of Illinois in 2015. He served as Interim Head of the Computer Science Department at Illinois from 2017 to 2019. Adve is a Co-founder and Co-Director of the Center for Digital Agriculture at Illinois, and leads AIFARMS, a national AI Institute that is developing and using novel AI techniques to address important challenges faced by world agriculture. Adve’s research in CDA and AIFARMS focuses on enabling high-performance and energy-efficient machine learning at the edge for agricultural applications.
Bio: Vikram Adve received his B.Tech degree in Electrical Engineering from IIT Bombay and his MS and PhD degrees in Computer Science from the University of Wisconsin-Madision. At present, he is the Donald B. Gillies Professor of Computer Science at the University of Illinois at Urbana-Champaign and a Professor of Electrical and Computer Engineering. Adve’s research interests lie in developing and using compiler techniques to improve the performance, programmability and energy-efficiency of computer systems. Adve’s current research focuses mainly on compiler and system support for heterogeneous edge computing. Adve and his Ph.D. student, Chris Lattner, co-designed the LLVM Compiler Infrastructure, which is widely used in industry today, including most mobile and desktop apps for Apple devices, and is also a popular system for compiler research. Adve, Lattner and Evan Cheng received the ACM Software System Award in 2012 for co-developing LLVM. One of Adve’s Ph.D. students, Robert Bocchino, won the 2010 ACM SIGPLAN Outstanding Dissertation Award and another student, John Criswell, won Honorable Mentions for both the 2014 ACM SIGOPS Dennis M. Ritchie Doctoral Dissertation Award and the 2014 ACM Doctoral Dissertation Award. Adve is a Fellow of the ACM and was named a University Scholar at the University of Illinois in 2015. He served as Interim Head of the Computer Science Department at Illinois from 2017 to 2019. Adve is a Co-founder and Co-Director of the Center for Digital Agriculture at Illinois, and leads AIFARMS, a national AI Institute that is developing and using novel AI techniques to address important challenges faced by world agriculture. Adve’s research in CDA and AIFARMS focuses on enabling high-performance and energy-efficient machine learning at the edge for agricultural applications.Homepage
Behind the Pixels: Challenges of Scaling and Optimizing Infrastructure for Animation Workloads
Abstract: Making an animated feature film is no small feat. At Walt Disney Animation Studios, hundreds of artists and engineers collaborate together for years to tell stories that delight audiences around the world. Each year, films grow in complexity as artists push the boundaries of what had been impossible just the year before. In this talk I will discuss some of the challenges we’re working on in our datacenter as we continue to try to make the impossible possible. First, I will look at challenges related to storage, like how to identify and squash the workloads on our renderfarm that consistently generate the NFS metadata operations that account for 95% of the activity on our file server. Next, I will talk about challenges on our renderfarm as we seek to improve the utilization of every CPU core and gigabyte of DRAM in the facility. This includes weighing the pros and cons of hyperconverged filesystems and disaggregated memory. Lastly, I will talk about where storage meets the renderfarm and discuss challenges around making data available to artists at their desktops while also simultaneously making that same data available to a remote renderfarm in the public cloud; all while allowing either side to make modifications at any time.
 Bio: Kevin Constantine joined Walt Disney Animation Studios in 2004, and is currently a Principal Systems Engineer responsible for designing and building Disney Animation's renderfarm, high-performance storage, and Coda queueing system. He has made contributions to such films as "Frozen", "Moana", "Encanto", and most recently "Strange World". Kevin is currently focused on constructing and optimizing geo-distributed render infrastructure.
Bio: Kevin Constantine joined Walt Disney Animation Studios in 2004, and is currently a Principal Systems Engineer responsible for designing and building Disney Animation's renderfarm, high-performance storage, and Coda queueing system. He has made contributions to such films as "Frozen", "Moana", "Encanto", and most recently "Strange World". Kevin is currently focused on constructing and optimizing geo-distributed render infrastructure.Homepage
Evaluating Large-Scale Learning Systems
Abstract: To deploy machine learning models in practice it is critical to have a way to reliably evaluate their effectiveness. Unfortunately, the scale and complexity of modern machine learning systems makes it difficult to provide faithful evaluations and gauge performance across potential deployment scenarios. In this talk I discuss our work addressing challenges in large-scale ML evaluation. First, I explore the problem of evaluating models trained in federated networks of devices, where issues of device subsampling, heterogeneity, and privacy can introduce noise in the evaluation process and make it challenging to provide reliable evaluations. Second, I present ReLM, a system for validating and querying large language models (LLMs). Although LLMs have been touted for their ability to generate natural-sounding text, there is a growing need to evaluate the behavior of LLMs in light of issues such as data memorization, bias, and inappropriate language. ReLM poses LLM validation queries as regular expressions to enable faster and more effective LLM evaluation.
 Bio: Virginia Smith is an assistant professor in the Machine Learning Department at Carnegie Mellon University. Her research spans machine learning, optimization, and distributed systems. Virginia’s current work addresses challenges related to optimization, privacy, and robustness in distributed settings to enable trustworthy federated learning at scale. Virginia’s work has been recognized by an NSF CAREER Award, MIT TR35 Innovator Award, Intel Rising Star Award, and faculty awards from Google, Apple, and Meta. Prior to CMU, Virginia was a postdoc at Stanford University and received a Ph.D. in Computer Science from UC Berkeley.
Bio: Virginia Smith is an assistant professor in the Machine Learning Department at Carnegie Mellon University. Her research spans machine learning, optimization, and distributed systems. Virginia’s current work addresses challenges related to optimization, privacy, and robustness in distributed settings to enable trustworthy federated learning at scale. Virginia’s work has been recognized by an NSF CAREER Award, MIT TR35 Innovator Award, Intel Rising Star Award, and faculty awards from Google, Apple, and Meta. Prior to CMU, Virginia was a postdoc at Stanford University and received a Ph.D. in Computer Science from UC Berkeley.Homepage
Heterogeneous multi-core systems for efficient EdgeML
Abstract: Embedded ML applications are characterized by increasingly diverse workloads, forming a rich mixture of signal processing, GeMM and conv kernels, attention layers, and even graph processing. Accelerator efficiency suffers from supporting this wide variety of kernels. Heterogeneous multicore systems can offer a solution but come with their own challenges, such as: 1.) How to find the most optimal combination of cores?; 2.) How to efficiently map workloads across cores?; 3.) How to share data between these cores? This talk will report on a heterogeneous multi-core system for embedded neural network processing taped out at KULeuven MICAS. Moreover, it will give an outlook on work in progress towards further expanding this system for covering more workloads and more heterogeneous cores.
 Bio:Marian Verhelst is a full professor at the MICAS laboratories of KU Leuven and a research director at imec. Her research focuses on embedded machine learning, hardware accelerators, HW-algorithm co-design and low-power edge processing. She received a PhD from KU Leuven in 2008, and worked as a research scientist at Intel Labs, Hillsboro OR from 2008 till 2010. Marian is a member of the board of directors of tinyML and active in the TPC’s of DATE, ISSCC, VLSI and ESSCIRC and was the chair of tinyML2021 and TPC co-chair of AICAS2020. Marian is an IEEE SSCS Distinguished Lecturer, was a member of the Young Academy of Belgium, an associate editor for TVLSI, TCAS-II and JSSC and a member of the STEM advisory committee to the Flemish Government. Marian received the laureate prize of the Royal Academy of Belgium in 2016, the 2021 Intel Outstanding Researcher Award, the André Mischke YAE Prize for Science and Policy in 2021, and two ERC grants.
Bio:Marian Verhelst is a full professor at the MICAS laboratories of KU Leuven and a research director at imec. Her research focuses on embedded machine learning, hardware accelerators, HW-algorithm co-design and low-power edge processing. She received a PhD from KU Leuven in 2008, and worked as a research scientist at Intel Labs, Hillsboro OR from 2008 till 2010. Marian is a member of the board of directors of tinyML and active in the TPC’s of DATE, ISSCC, VLSI and ESSCIRC and was the chair of tinyML2021 and TPC co-chair of AICAS2020. Marian is an IEEE SSCS Distinguished Lecturer, was a member of the Young Academy of Belgium, an associate editor for TVLSI, TCAS-II and JSSC and a member of the STEM advisory committee to the Flemish Government. Marian received the laureate prize of the Royal Academy of Belgium in 2016, the 2021 Intel Outstanding Researcher Award, the André Mischke YAE Prize for Science and Policy in 2021, and two ERC grants.Homepage
Scalable Graph Machine Learning
Abstract: Recently, Graph Neural Networks (GNNs) have been used in many applications leading to improved accuracy and fast approximate solutions. Training as well as Inference in these networks is computationally demanding. Challenges include access to irregular data, large scale sparse as well as dense matrix computations, limited data reuse and heterogeneity in the various stages of the computation. This talk will review our recent work in the Data Science Lab (dslab.usc.edu) and FPGA/Parallel Computing Lab (fpga.usc.edu) at USC leading up to current trends in accelerators for data science. For graph embedding, we develop GraphSAINT, a novel computationally efficient technique using graph sampling and demonstrate scalable performance. We develop graph processing over partitions (GPOP) methodology to handle large scale graphs on parallel platforms. On a current FPGA device, we demonstrate up to 100X and 30X speed up for full graph GNN computations compared with state-of-the-art implementations on CPU and GPU respectively. We also demonstrate specific accelerators for two widely used GNN models: GraphSAGE and GraphSAINT. We conclude by identifying opportunities and challenges in exploiting emerging heterogeneous architectures towards a general framework for GNN acceleration.
 Bio: Viktor K. Prasanna is Charles Lee Powell Chair in Engineering in the Ming Hsieh Department of Electrical and Computer Engineering and Professor of Computer Science at the University of Southern California. He is the director of the Center for Energy Informatics at USC and leads the FPGA (fpga.usc.edu) and Data Science Labs (dslab.usc.edu). His research interests include parallel and distributed computing, accelerator design, reconfigurable architectures and algorithms and high performance computing. He serves as the Editor-in-Chief of the Journal of Parallel and Distributed Computing. Prasanna was the founding Chair of the IEEE Computer Society Technical Committee on Parallel Processing. He is the Steering Chair of the IEEE International Parallel and Distributed Processing Symposium. He is a Fellow of the IEEE, the ACM and the American Association for Advancement of Science (AAAS). He is a recipient of 2009 Outstanding Engineering Alumnus Award from the Pennsylvania State University and a 2019 Distinguished Alumnus Award from the Indian Institute of Science. He received the 2015 W. Wallace McDowell award from the IEEE Computer Society for his contributions to reconfigurable computing. He is an elected member of Academia Europaea.
Bio: Viktor K. Prasanna is Charles Lee Powell Chair in Engineering in the Ming Hsieh Department of Electrical and Computer Engineering and Professor of Computer Science at the University of Southern California. He is the director of the Center for Energy Informatics at USC and leads the FPGA (fpga.usc.edu) and Data Science Labs (dslab.usc.edu). His research interests include parallel and distributed computing, accelerator design, reconfigurable architectures and algorithms and high performance computing. He serves as the Editor-in-Chief of the Journal of Parallel and Distributed Computing. Prasanna was the founding Chair of the IEEE Computer Society Technical Committee on Parallel Processing. He is the Steering Chair of the IEEE International Parallel and Distributed Processing Symposium. He is a Fellow of the IEEE, the ACM and the American Association for Advancement of Science (AAAS). He is a recipient of 2009 Outstanding Engineering Alumnus Award from the Pennsylvania State University and a 2019 Distinguished Alumnus Award from the Indian Institute of Science. He received the 2015 W. Wallace McDowell award from the IEEE Computer Society for his contributions to reconfigurable computing. He is an elected member of Academia Europaea.Homepage
Can I Cook a 5 o'clock Compiler Cake and Eat It at 2?
Abstract: In high-performance computing words: can we build a compiler that will eventually save a lot of performance engineering effort while immediately delivering competitive results? Here, competitiveness refers to achieving near hardware peak-performance for important applications. The question is particularly hot in a domain-specific setting, where the building blocks for constructing an effective optimizing compiler may be inadequate, too generic, or too low-level. It is widely understood that compiler construction has failed to deliver early afternoon sweets. I personally feel bad about it, but until recently it remained an academic exercise to challenge the status quo. Maybe it is now time to reconsider this assumption: ML-enhanced compilers become the norm rather than the exception. New compiler frameworks reconcile optimizations for the common case with application-specific performance. Domain-specific code generators play an essential role in the implementation of dense and sparse numerical libraries. But even with the help of domain-specific compilers, peak performance can only be achieved at the expense of a dramatic loss of programmability. Are we ever going to find a way out of this programmability/performance dilemma? What about the velocity and agility of compiler engineers? Can we make ML-based heuristics scalable enough to compile billions of lines of code? Can we do so while enabling massive code reuse across domains, languages and hardware? We will review these questions, based on recent successes and half-successes in academia and industry. We will also form an invitation to tackle these challenges in future research and software development.
 Bio:Albert Cohen is a research scientist at Google. An alumnus of École Normale Supérieure de Lyon and the University of Versailles, he has been a research scientist at Inria, a visiting scholar at the University of Illinois, an invited professor at Philips Research, and a visiting scientist at Facebook Artificial Intelligence Research. Albert works on parallelizing, optimizing and machine learning compilers, and on dataflow and synchronous programming languages, with applications to high-performance computing, artificial intelligence and reactive control.
Bio:Albert Cohen is a research scientist at Google. An alumnus of École Normale Supérieure de Lyon and the University of Versailles, he has been a research scientist at Inria, a visiting scholar at the University of Illinois, an invited professor at Philips Research, and a visiting scientist at Facebook Artificial Intelligence Research. Albert works on parallelizing, optimizing and machine learning compilers, and on dataflow and synchronous programming languages, with applications to high-performance computing, artificial intelligence and reactive control.Homepage
Capturing Computation with Algorithmic Alignment
Abstract: What makes a neural network better, or worse, at fitting certain tasks? This question is arguably at the heart of neural network architecture design, and it is remarkably hard to answer rigorously. Over the past few years, there have been a plethora of attempts, using various facets of advanced mathematics, to answer this question under various assumptions. One of the most successful directions -- algorithmic alignment -- assumes that the target function, and a mechanism for computing it, are completely well-defined and known (i.e. the target is to learn to execute an algorithm). In this setting, fitting a task is equated to capturing the computations of an algorithm, inviting analyses from diverse branches of mathematics and computer science. I will present some of my personal favourite works in algorithmic alignment, along with their implications for building intelligent systems of the future.
 Bio: Petar is a Staff Research Scientist at Google DeepMind, an Affiliated Lecturer at the University of Cambridge, and an Associate of Clare Hall, Cambridge. He holds a PhD in Computer Science from the University of Cambridge (Trinity College), obtained under the supervision of Pietro Liò. His research concerns geometric deep learning—devising neural network architectures that respect the invariances and symmetries in data (a topic he’s co-written a proto-book about). For his contributions, he is recognized as an ELLIS Scholar in the Geometric Deep Learning Program. Particularly, he focuses on graph representation learning and its applications in algorithmic reasoning (featured in VentureBeat). He is the first author of Graph Attention Networks—a popular convolutional layer for graphs—and Deep Graph Infomax—a popular self-supervised learning pipeline for graphs (featured in ZDNet). His research has been used in substantially improving travel-time predictions in Google Maps (featured in CNBC, Endgadget, VentureBeat, CNET, the Verge, and ZDNet), and guiding the intuition of mathematicians towards new top-tier theorems and conjectures (featured in Nature, Science, Quanta Magazine, New Scientist, The Independent, Sky News, The Sunday Times, la Repubblica, and The Conversation).
Bio: Petar is a Staff Research Scientist at Google DeepMind, an Affiliated Lecturer at the University of Cambridge, and an Associate of Clare Hall, Cambridge. He holds a PhD in Computer Science from the University of Cambridge (Trinity College), obtained under the supervision of Pietro Liò. His research concerns geometric deep learning—devising neural network architectures that respect the invariances and symmetries in data (a topic he’s co-written a proto-book about). For his contributions, he is recognized as an ELLIS Scholar in the Geometric Deep Learning Program. Particularly, he focuses on graph representation learning and its applications in algorithmic reasoning (featured in VentureBeat). He is the first author of Graph Attention Networks—a popular convolutional layer for graphs—and Deep Graph Infomax—a popular self-supervised learning pipeline for graphs (featured in ZDNet). His research has been used in substantially improving travel-time predictions in Google Maps (featured in CNBC, Endgadget, VentureBeat, CNET, the Verge, and ZDNet), and guiding the intuition of mathematicians towards new top-tier theorems and conjectures (featured in Nature, Science, Quanta Magazine, New Scientist, The Independent, Sky News, The Sunday Times, la Repubblica, and The Conversation).Homepage
The digital revolution of Earth system modelling
Abstract: This talk will outline three revolutions that happened in Earth system modelling in the past decades. The quiet revolution has leveraged better observations and more compute power to allow for constant improvements of prediction quality of the last decades, the digital revolution has enabled us to perform km-scale simulations on modern supercomputers that further increase the quality of our models, and the machine learning revolution has now shown that machine learned weather models are often competitive with conventional weather models for many forecast scores while being easier, smaller and cheaper. This talk will summarize the past developments, explain current challenges and opportunities, and outline how the future of Earth system modelling will look like.
 Bio: Peter is the Head of the Earth System Modelling Section at the European Centre for Medium Range Weather Forecasts (ECMWF) developing one of the world’s leading global weather forecast model. Before, he was AI and Machine Learning Coordinator at ECMWF and University Research Fellowship of the Royal Society performing research towards the use of machine learning, high-performance computing, and reduced numerical precision in weather and climate simulations. Peter is coordinator of the MAELSTROM EuroHPC-Joint Undertaking project that is implementing a software/hardware co-design cycle to optimise performance and quality of machine learning applications in the area of weather and climate science.
Bio: Peter is the Head of the Earth System Modelling Section at the European Centre for Medium Range Weather Forecasts (ECMWF) developing one of the world’s leading global weather forecast model. Before, he was AI and Machine Learning Coordinator at ECMWF and University Research Fellowship of the Royal Society performing research towards the use of machine learning, high-performance computing, and reduced numerical precision in weather and climate simulations. Peter is coordinator of the MAELSTROM EuroHPC-Joint Undertaking project that is implementing a software/hardware co-design cycle to optimise performance and quality of machine learning applications in the area of weather and climate science.Homepage
Improving Cloud Security with Hardware Memory Capabilities
Abstract: More and more data-intensive applications, e.g., micro-service architectures and machine learning workloads, move from on-premise deployments to the cloud. Traditional cloud security mechanisms focus on strict isolation, but applications also require the efficient yet secure sharing of data between components and services. In this talk, I will explore how we can use a new hardware security feature, memory capabilities, to design a cloud stack that bridges the tension between isolation and sharing. Memory capabilities constrain memory accesses, and they can be used to provide a VM-like isolation mechanism, cVMs, that can share data more efficiently than containers. They can also increase memory efficiency by safely de-duplicating application components. I will discuss our experience in building a cloud stack with memory capabilities on the CHERI architecture, as implemented by Arm’s Morello hardware.
 Bio: Peter Pietzuch is a Professor of Distributed Systems at Imperial College London, where he leads the Large-scale Data & Systems (LSDS) group. He is also a Co-Director for Imperial's I-X initiative in AI, data and digital. His research work focuses on the design and engineering of scalable, reliable and secure data-intensive software systems, with a particular interest in performance, data management and security issues. The LSDS group consists of four faculty members, with recent publications at diverse top-tier conferences, including USENIX OSDI, ACM SOSP, USENIX ATC, ACM EuroSys, ACM ASPLOS, USENIX NSDI, ACM SIGMOD, VLDB, IEEE ICDE, ACM SoCC, ACM CCS, and ACM/USENIX Middleware. Until recently, he has served as the Director of Research in the Department of Computing, and the Chair of the ACM SIGOPS European Chapter (EuroSys). He was a PC Chair for the ACM Symposium on Cloud Computing (SoCC 2023) and the IEEE International Conference on Distributed Computing Systems (ICDCS 2018). Before joining Imperial College London, he was a post-doctoral Fellow at Harvard University. He holds PhD and MA degrees from the University of Cambridge.
Bio: Peter Pietzuch is a Professor of Distributed Systems at Imperial College London, where he leads the Large-scale Data & Systems (LSDS) group. He is also a Co-Director for Imperial's I-X initiative in AI, data and digital. His research work focuses on the design and engineering of scalable, reliable and secure data-intensive software systems, with a particular interest in performance, data management and security issues. The LSDS group consists of four faculty members, with recent publications at diverse top-tier conferences, including USENIX OSDI, ACM SOSP, USENIX ATC, ACM EuroSys, ACM ASPLOS, USENIX NSDI, ACM SIGMOD, VLDB, IEEE ICDE, ACM SoCC, ACM CCS, and ACM/USENIX Middleware. Until recently, he has served as the Director of Research in the Department of Computing, and the Chair of the ACM SIGOPS European Chapter (EuroSys). He was a PC Chair for the ACM Symposium on Cloud Computing (SoCC 2023) and the IEEE International Conference on Distributed Computing Systems (ICDCS 2018). Before joining Imperial College London, he was a post-doctoral Fellow at Harvard University. He holds PhD and MA degrees from the University of Cambridge.Homepage
Programming Groq LPUs without IEEE Floating Point
Abstract: The IEEE standard has been a great advance in the early days of software. In these early days, the speed of software development was imperative. The Intel x86 instruction set became a standard as well as IEEE Floating point. Today, we have the first commodity computing application, the LLM, and others are rapidly following. In the commodity economy, efficiency and cost become the utmost imperative. As we are giving up on the x86 instruction set, we have to also consider custom number representations for each variable in our programs, opening the world of Physics and Computer Science to a new dimension in computing (as predicted in my talk at ETH in 2000). In this talk I will cover how to find the (locally) optimal range and precision for each variable, and how to optimally utilize custom precision arithmetic units in modern leading compute chips such as the Groq LPU.
 Bio: Oskar Mencer got a PhD in Computer Engineering from Stanford University in 2000, interviewed unsuccessfully at ETH for an Assistant Professor position, joined Bell Labs 1127, then became EPSRC Advanced Fellow at Imperial, started Maxeler Technologies, and later got major investments among others from JP Morgan and CME Group. Maxeler was recently acquired by Groq, the leading AI inference company in California. Oskar remains CEO of Maxeler, a Groq Company and now lives on Palm Jumeirah in Dubai.
Bio: Oskar Mencer got a PhD in Computer Engineering from Stanford University in 2000, interviewed unsuccessfully at ETH for an Assistant Professor position, joined Bell Labs 1127, then became EPSRC Advanced Fellow at Imperial, started Maxeler Technologies, and later got major investments among others from JP Morgan and CME Group. Maxeler was recently acquired by Groq, the leading AI inference company in California. Oskar remains CEO of Maxeler, a Groq Company and now lives on Palm Jumeirah in Dubai.Homepage
Hardware-aware Algorithms for Language Modeling
Abstract: Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. In the first half, we describe recent advances in FlashAttention, including optimizations for Hopper GPUs. exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0× with FP16 reaching up to 850 TFLOPs/s (86% utilization), and with FP8 reaching 1.3 PFLOPs/s. In the second half, we focus on subquadratic-time architectures such structured state space models (SSMs). We identify that a key weakness of such models is their inability to perform content-based reasoning, and propose a selection mechanism to address this shortcoming. Though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks. The resulting architecture (Mamba and Mamba-2) matches or exceeds the performance of strong modern Transformers on language modeling, validated at 3B scales on both pretraining and downstream evaluation, while enjoying 5x higher inference throughput and linear scaling in sequence length.
 Bio: Tri Dao is an Assistant Professor at Princeton University and chief scientist of Together AI. He completed his PhD in Computer Science at Stanford. He works at the intersection of machine learning and systems, and his research interests include sequence models with long-range memory and structured matrices for compact deep learning models. His work has received the COLM 2024 Outstanding paper award and ICML 2022 Outstanding paper runner-up award.
Bio: Tri Dao is an Assistant Professor at Princeton University and chief scientist of Together AI. He completed his PhD in Computer Science at Stanford. He works at the intersection of machine learning and systems, and his research interests include sequence models with long-range memory and structured matrices for compact deep learning models. His work has received the COLM 2024 Outstanding paper award and ICML 2022 Outstanding paper runner-up award.Homepage
Neural Network Quantization with Brevitas
Abstract: This talk will cover Brevitas, a PyTorch-based neural network quantization tool. Brevitas can cover a wide range of datatypes (including integer, floating-point and OCP-compliant MX formats), quantization configurations and algorithms, giving experienced users the possibility to tune all the aspects of the quantization process. On top of this, Brevitas is written in a modular, extensible way enabling researchers to implement novel quantization ideas, like accumulator-aware quantization (A2Q) - a cutting-edge quantization technique which improves inference performance while maintaining high task accuracy.
 Bio: Nicholas J. Fraser received the PhD degree at The University of Sydney, Australia in 2020. Currently, he is a Research Scientist at AMD Research and Advanced Development (RAD), Dublin, Ireland. His main research interests include: training of reduced precision neural networks, software / hardware co-design of neural network topologies / accelerators, and audio signal processing.
Bio: Nicholas J. Fraser received the PhD degree at The University of Sydney, Australia in 2020. Currently, he is a Research Scientist at AMD Research and Advanced Development (RAD), Dublin, Ireland. His main research interests include: training of reduced precision neural networks, software / hardware co-design of neural network topologies / accelerators, and audio signal processing.Homepage
Deep learning can beat numerical weather prediction! What's next?
Abstract: The past two years have witnessed an enormous evolution of machine learning models for weather prediction. What has been almost unthinkable a few years ago is now routinely confirmed: large-scale deep learning models trained on many years of reanalysis data can make more accurate predictions with longer lead times than classical numerical models. Recent developments also show the potential to use these models for ensemble forecasting and data assimilation. This talk will present the current state-of-the-art and point out where ongoing developments are heading and where limitations of AI models for weather and climate are observed.
 Bio: Prof Schultz is an internationally recognized leading researcher in the fields of air quality, weather and climate science. Since 2018 he has been focusing on the development of advanced machine learning models to improve weather and air pollution forecasting after he spent almost 3 decades analyzing atmospheric data and developing coupled Earth system models. Schultz graduated at the University of Heidelberg, Germany, and obtained his PhD from the University of Wuppertal. He worked as postdoctoral researcher at Harvard University, became group leader at the Max-Planck-Institute for Meteorology in Hamburg, and then came to Forschungszentrum Jülich, where he has since been leading research teams of up to 20 people at the Institute for Energy and Climate Research, and, since 2017, the Jülich Supercomputing Centre. Schultz is a co-chair of the international Tropospheric Ozone Assessment Report, key contributor to the atmospheric dynamics foundation model AtmoRep, and co-organisator of the annual international workshop on “Large-scale deep learning for the Earth System” in Bonn. He has also been active of chairing activities in the World Meteorological Organisation and the European Destination Earth initiative. Schultz holds a professorship on “Computational Earth System Science” at the University of Cologne.
Bio: Prof Schultz is an internationally recognized leading researcher in the fields of air quality, weather and climate science. Since 2018 he has been focusing on the development of advanced machine learning models to improve weather and air pollution forecasting after he spent almost 3 decades analyzing atmospheric data and developing coupled Earth system models. Schultz graduated at the University of Heidelberg, Germany, and obtained his PhD from the University of Wuppertal. He worked as postdoctoral researcher at Harvard University, became group leader at the Max-Planck-Institute for Meteorology in Hamburg, and then came to Forschungszentrum Jülich, where he has since been leading research teams of up to 20 people at the Institute for Energy and Climate Research, and, since 2017, the Jülich Supercomputing Centre. Schultz is a co-chair of the international Tropospheric Ozone Assessment Report, key contributor to the atmospheric dynamics foundation model AtmoRep, and co-organisator of the annual international workshop on “Large-scale deep learning for the Earth System” in Bonn. He has also been active of chairing activities in the World Meteorological Organisation and the European Destination Earth initiative. Schultz holds a professorship on “Computational Earth System Science” at the University of Cologne.Homepage
The evolution of accelerator-centric GPU services - past, present, future.
Abstract: GPUs have come a long way, evolving from gaming processors to the main driving force behind modern AI systems. However, from a system design perspective, they remain co-processors: they cannot operate independently of the host CPU, which is necessary to invoke kernels, manage GPU memory, perform data transfers, and interact with I/O devices. Thus, beyond the complexity of optimizing individual kernels, GPU-accelerated application development faces fundamental challenges in integrating GPU computations into complex data and control flows involving networking and storage. Since 2013, my students in the Accelerated Computing Systems Group (https://acsl.group) have been exploring an alternative, accelerator-centric system design in which a GPU runs specially crafted OS layers that allow GPU kernels to access files, storage devices, SmartNICs, and network services, without CPU involvement in the data and/or control path. We have demonstrated how such an approach simplifies the programming burden and achieves high performance. In this talk, I will survey the key ideas of the accelerator-centric design, discuss the main takeaways, and explore future trends.
 Bio: Mark Silberstein is a professor in the Electrical and Computer Engineering Department at the Technion - Israel Institute of Technology. His research interests span a broad range of topics in computer systems, including OS, networking, computer architecture, and systems security. His projects have been published in top systems venues, with some winning awards and others being adopted by the industry. He regularly serves on the program committees of leading systems conferences, including as a program co-chair of Eurosys '24 and ASPLOS '26.
Bio: Mark Silberstein is a professor in the Electrical and Computer Engineering Department at the Technion - Israel Institute of Technology. His research interests span a broad range of topics in computer systems, including OS, networking, computer architecture, and systems security. His projects have been published in top systems venues, with some winning awards and others being adopted by the industry. He regularly serves on the program committees of leading systems conferences, including as a program co-chair of Eurosys '24 and ASPLOS '26. Homepage
Broadcast, Reduction and beyond with Block Schedules and Circulant Graphs
Abstract: We present a round-optimal algorithm for broadcasting n indivisible blocks of data over p processors communicating in a regular, logarithmic degree circulant graph pattern. This broadcast algorithm immediately leads to partly new, likewise round-optimal algorithms for the reduction to root, all-to-all broadcast (allgatherv) and irregular and regular reduce-scatter operations. The broadcast algorithm relies on block schedules with certain properties which we indicate can be computed optimally in O(log p) operations per processor without communication. The communication pattern and algorithms are attractive for implementing most of the standard, dense collective operations of MPI.
 Bio: Jesper Larsson Träff is professor for Parallel Computing at TU Wien (Vienna University of Technology) since 2011. From 2010 to 2011 he was guest professor for Scientific Computing at the University of Vienna. From 1998 until 2010 he was working at the NEC Laboratories Europe in Sankt Augustin, Germany on efficient implementations of MPI for NEC vector supercomputers; this work led to a doctorate (Dr. Scient.; Habilitation) from the University of Copenhagen in 2009. From 1995 to 1998 he spent four years as PostDoc/Research Associate in the Algorithms Group of the Max-Planck Institute for Computer Science in Saarbrücken, and the Efficient Algorithms Group at the Technical University of Munich. He received an M.Sc. in computer science in 1989, and, after two interim years at the industrial research center ECRC in Munich, a Ph.D. in 1995, both from the University of Copenhagen.
Bio: Jesper Larsson Träff is professor for Parallel Computing at TU Wien (Vienna University of Technology) since 2011. From 2010 to 2011 he was guest professor for Scientific Computing at the University of Vienna. From 1998 until 2010 he was working at the NEC Laboratories Europe in Sankt Augustin, Germany on efficient implementations of MPI for NEC vector supercomputers; this work led to a doctorate (Dr. Scient.; Habilitation) from the University of Copenhagen in 2009. From 1995 to 1998 he spent four years as PostDoc/Research Associate in the Algorithms Group of the Max-Planck Institute for Computer Science in Saarbrücken, and the Efficient Algorithms Group at the Technical University of Munich. He received an M.Sc. in computer science in 1989, and, after two interim years at the industrial research center ECRC in Munich, a Ph.D. in 1995, both from the University of Copenhagen.Homepage
Merging and MoErging for compositional generalization
Abstract: Multitask training has been shown to enable generalization to new tasks through the composition of "skills" learned from different tasks. Model merging, which combines the parameters of individual-task models, has recently emerged as an effective paradigm for creating multitask models. After discussing some different perspectives and approaches on model merging, I will present our recent work that aims to directly measure whether merging provides meaningful compositional generalization. In short, it doesn't. Motivated by this shortcoming, I will present some of our recent work on MoErging, which instead keeps individual-task models separate and instead learns to route between them.
 Bio: Colin Raffel is an associate professor at the University of Toronto, an associate research director at the Vector Institute, and a faculty researcher at Hugging Face.
Bio: Colin Raffel is an associate professor at the University of Toronto, an associate research director at the Vector Institute, and a faculty researcher at Hugging Face.Homepage
Measurement and Analysis of Application Performance on GPU-accelerated Systems at Exascale
Abstract: As part of the US DOE's Exascale Computing Project, Rice University began extending its HPCToolkit performance tools to support instruction-level measurement and analysis of applications executing on GPU-accelerated exascale supercomputers. Hardware support for instruction-level performance measurement in AMD, Intel, and NVIDIA GPUs was developed at the urging of the HPCToolkit project team. HPCToolkit employs PC sampling or binary instrumentation to perform instruction-level measurements of GPU computations. When measuring a GPU-accelerated application, HPCToolkit employs a novel wait-free data structure to communicate performance measurements between tool threads and application threads. To help attribute performance information in detail, HPCToolkit performs parallel analysis of large CPU and GPU binaries involved in the execution of an exascale application to rapidly recover mappings between machine instructions and source code. To analyze terabytes of performance measurements gathered during executions at exascale, HPCToolkit employs distributed-memory parallelism, multithreading, sparse data structures, and out-of-core streaming analysis algorithms. To support interactive exploration of profiles up to terabytes in size, HPCToolkit's hpcviewer GUI uses out-of-core methods to visualize performance data. These strategies have enabled HPCToolkit to efficiently measure, analyze and explore terabytes of performance data for executions using as many as 64K MPI ranks and 64K GPU tiles on ORNL's Frontier supercomputer. This talk will describe key aspects of HPCToolkit, successes analyzing applications, and some challenges ahead.
 Bio: John Mellor-Crummey is a Professor of Computer Science at Rice University in Houston, TX, USA. His principal research focus at present is tools for measurement and analysis of application performance. His past work includes scalable synchronization algorithms for shared-memory multiprocessors, compilers and runtime systems for parallel computing, techniques for execution replay of parallel programs, tools for dynamic data race detection, and techniques for network performance analysis and optimization. Mellor-Crummey co-led development of the OMPT tools interface for OpenMP 5. He is a co-recipient of the 2006 Dijkstra Prize in Distributed Computing, co-recipient of a 2024 Honor Award from the US Secretary of Energy, and a Fellow of the ACM.
Bio: John Mellor-Crummey is a Professor of Computer Science at Rice University in Houston, TX, USA. His principal research focus at present is tools for measurement and analysis of application performance. His past work includes scalable synchronization algorithms for shared-memory multiprocessors, compilers and runtime systems for parallel computing, techniques for execution replay of parallel programs, tools for dynamic data race detection, and techniques for network performance analysis and optimization. Mellor-Crummey co-led development of the OMPT tools interface for OpenMP 5. He is a co-recipient of the 2006 Dijkstra Prize in Distributed Computing, co-recipient of a 2024 Honor Award from the US Secretary of Energy, and a Fellow of the ACM.Homepage
Data Selection - Data Challenges when Training Generative Models
Abstract: This talk explores how strategic data selection can improve the efficiency of training generative AI models. I will cover approaches for both pre-training and fine-tuning that achieve comparable performance to full training while using only a fraction of the data. During the talk I will cover key filtering techniques and data selection methods for efficient pre-training as well as the connection between data selection and optimal transport for optimized fine-tuning. I will conclude with promising future directions for adaptive data selection research.
 Bio: Theo Rekatsinas is the VP of Machine Learning at Axelera AI. before that he was a tech lead at Apple working on on-device intelligence and a senior manager in the Apple Knowledge Graph (KG) team responsible for the KG construction and Graph Machine learning teams. Theo co-founded Inductiv (acquired by Apple), a company that developed Generative AI solutions for identifying and correcting errors in data. Theo was also a Professor of Computer Science at ETH Zürich and the University of Wisconsin-Madison. Theo's research focuses on scalable machine learning over billion-scale relational and graph-structured data. His research focused on exploring the fundamental connections between data preparation, data integration, and knowledge management with statistical machine learning and probabilistic inference.
Bio: Theo Rekatsinas is the VP of Machine Learning at Axelera AI. before that he was a tech lead at Apple working on on-device intelligence and a senior manager in the Apple Knowledge Graph (KG) team responsible for the KG construction and Graph Machine learning teams. Theo co-founded Inductiv (acquired by Apple), a company that developed Generative AI solutions for identifying and correcting errors in data. Theo was also a Professor of Computer Science at ETH Zürich and the University of Wisconsin-Madison. Theo's research focuses on scalable machine learning over billion-scale relational and graph-structured data. His research focused on exploring the fundamental connections between data preparation, data integration, and knowledge management with statistical machine learning and probabilistic inference.Homepage