|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










DARE: High-Performance State Machine Replication on RDMA Networks
Motivation
Replicated state machines (RSMs) prevent global outages and can hide server failures while ensuring strong consistency of the overall system. RSMs are often at the core of global-scale services (e.g., in Google’s Spanner or Yahoo!’s Zookeeper). However, typical RSM request rates are orders of magnitude lower than the request rates of the overall systems. Thus, highly scalable systems typically utilize RSMs only for management tasks and improve overall performance by relaxing request ordering which implicitly shifts the burden of consistency management to the application l ayer. Yet, many services, such as airline reservation systems, require a consistent view of the complete distributed database at very high request rates.
To ensure strong consistency, RSMs usually rely on a distinguished server, the leader, to order incoming requests. Moreover, before answering a request, the leader must replicate the enclosed state machine update on the remote servers; thus, efficient replication is critical for high performance. Existing TCP or UDP-based RSMs perform these remote updates through messages; thus, the CPUs of the remote servers are unnecessarily involved into the replication process. A more fitting approach is to use remote direct memory access (RDMA): RDMA allows the leader to directly access the memory of the remote servers without involving their CPUs. The benefit of bypassing the remote CPUs is twofold: (1) the synchronization between the leader and the remote servers is reduced; and (2) while the leader handles requests, the remote servers can perform other operations, such as tacking checkpoints.
DARE basics
The internal state of each server consists of four main data structures depicted in Figure 2: (1) the client SM; (2) the log; (3) the configuration; and (4) the control data. The SM is an opaque object that can be updated by the server through RSM operations received from clients. For consistency, servers apply the RSM operations in the same order; this is achieved by first appending the operations to the log.

The internal state and interface of a DARE server
The log is a circular buffer composed of entries that have sequential indexes; each entry contains the term in which it was created. Log entries store RSM operations that need to be applied to the SM. The log is described by four dynamic pointers, which follow each other clockwise in a circle:
- head points to the first entry in the log;
- apply points to the first entry that is not applied to the SM;
- commit points to the first not-committed log entry;
- tail points to the end of the log.
The configuration data structure is a high level description of the group of servers used for group reconfiguration, while the control data consists of a set of arrays used internally by DARE.
Leader Election
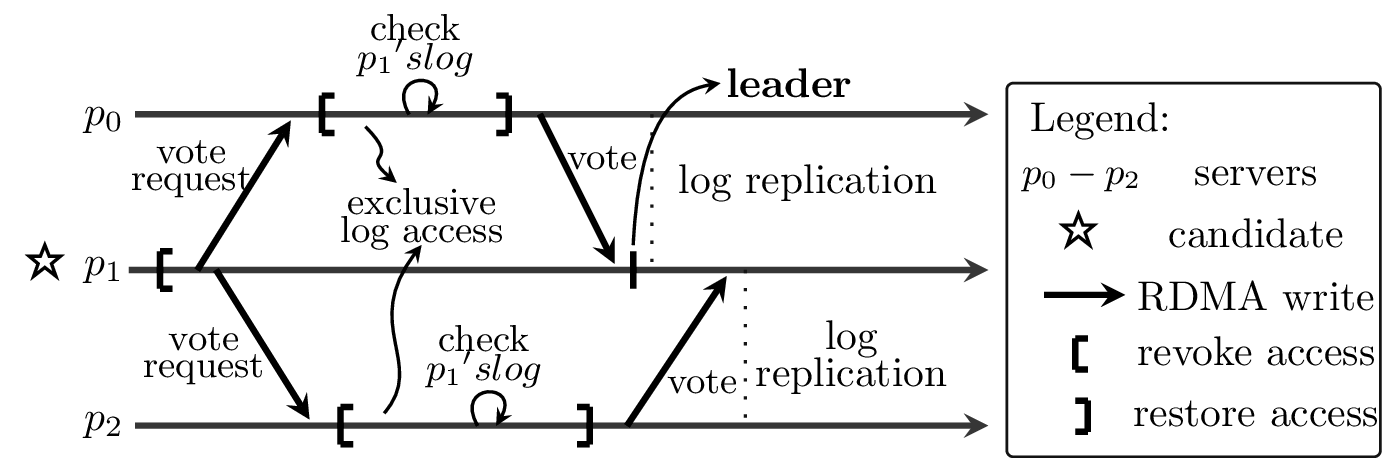
The voting mechanism during leader election.
DARE adopts a traditional leader election protocol to RDMA semantics: A server sends vote requests and it waits for votes from at least ⌊P/2⌋ (out of P) servers, before it becomes the leader. Although our approach is similar to a message-passing one, it requires special care when managing the log accesses. In particular, by using RDMA semantics, the leader bypasses the remote CPUs when accessing their logs; as a result, the servers are unaware of any updates of their logs. This hinders the ability of a server to participate in elections. Thus, DARE uses QP state transitions to allow servers to manage the remote access to their own memory.
Log Replication
The core of the DARE protocol is log replication—the leader replicates RSM operations on the other servers with the intention to commit them. Note that an RSM operation is committed when it resides in the logs of at least a majority of the servers. In DARE, log replication is performed entirely through RDMA: The leader writes its own log entries into the logs of the remote servers. Yet, after a new leader is elected, the logs can contain not-committed entries. These entries may differ from the ones stored at the same position in the leader’s log. Before a newly elected leader can replicate log entries, it must first remove all the remote not-committed entries. Therefore, we split the log replication protocol into two phases: (1) log adjustment; and (2) direct log update. The below figure shows the RDMA accesses performed by the leader in both phases.
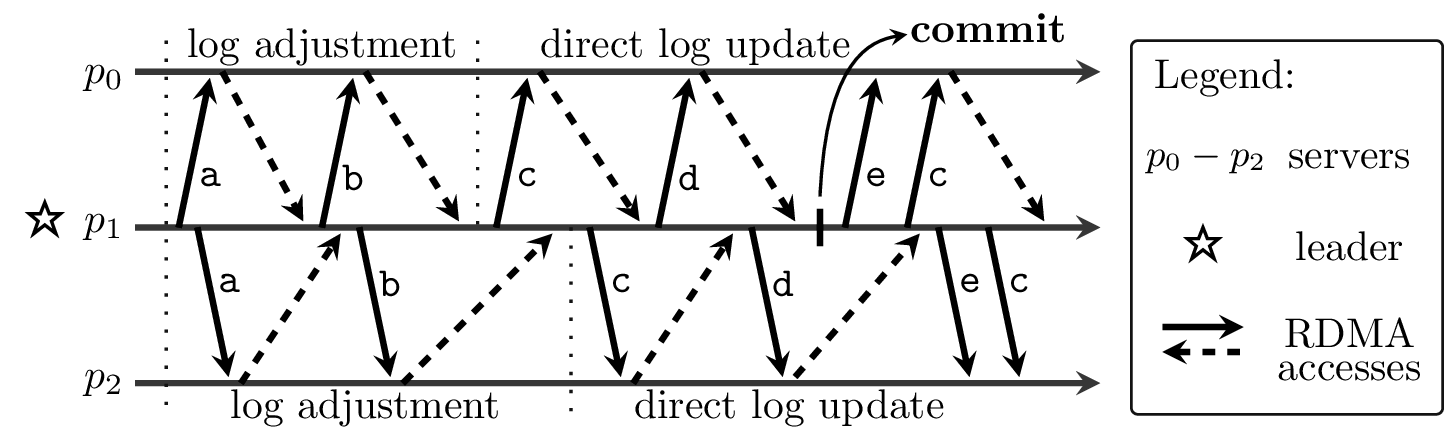
The RDMA accesses during log replication: (a)read the remote not-committed entries; (b) write the remote tail pointer; (c) write the remote log; (d) write the remote tail pointer; and (e) write the remote commit pointer.
Reliability
Our design exploits the concept of memory reliability through raw replication. In particular, the leader uses raw replication implicitly during log replication, when it creates q=⌈(P+1)/2⌉ replicas for each committed log entry. Thus, DARE’s reliability is given by the probability that no more than q-1 servers experience a memory failure (we consider the failures probabilities of both NIC and network to be negligible).
We propose a model that considers the components as part of non-repairable populations: Having experienced a failure, the same component can rejoin the system; yet, it is treated as a new individual of the population. The below figure plots the reliability as a function of the group size. Of particular interest is the decrease in reliability when the group size increases from an even to an odd value. This is expected since the group has one more server, but the number of replicas remains unchanged. Also, the figure compares the reliability of our in-memory approach with the one achieved by stable storage.
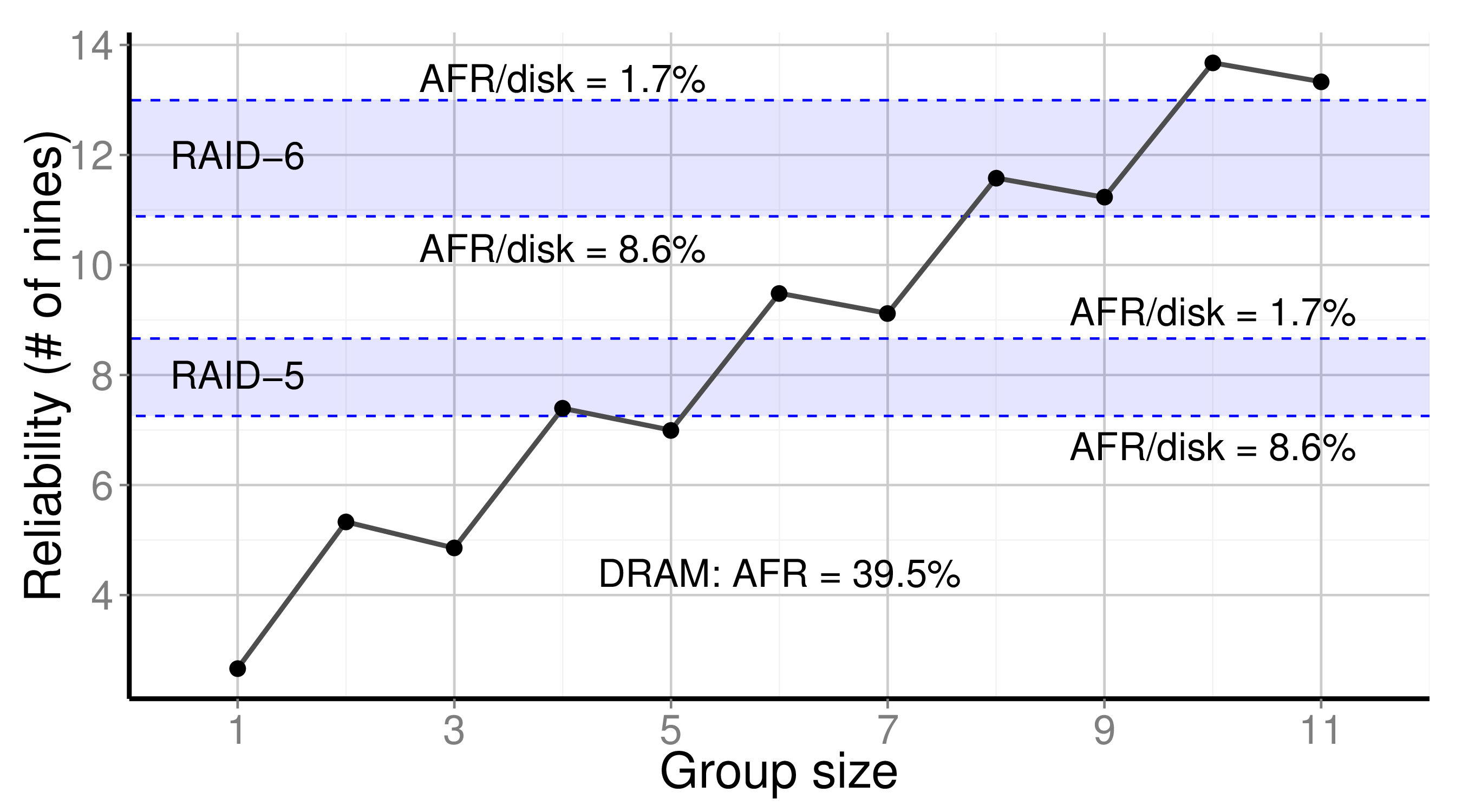
DARE’s reliability over a period of 24 hours.
Performance Evaluation
We evaluate the performance of DARE in a practical setting. We use a 12-node InfiniBand cluster; each node has an Intel E5-2609 CPU clocked at 2.40GHz. The cluster is connected with a single switch using a single Mellanox QDR NIC (MT27500) at each node. Moreover, the nodes are running Linux, kernel version 3.12.18. DARE is implemented in C and relies on two libraries: libibverbs, an implementation of the RDMA verbs for InfiniBand; and libev, a highperformance event loop. Each server runs an instance of DARE; yet, each server is single-threaded. Finally, to compile the code, we used gcc version 4.8.2. For the source code see the Download Section.
We consider a key-value store (KVS) as the client SM: Clients access data through 64-byte keys. Moreover, since clients send requests through UD, the size of a request is limited by the network’s MTU (i.e., 4096 bytes). From our evaluation, of particular interests are the effects of a dynamic group membership on DARE’s performance and the comparison of DARE's performance with other protocols and implementations, such as ZooKeeper.
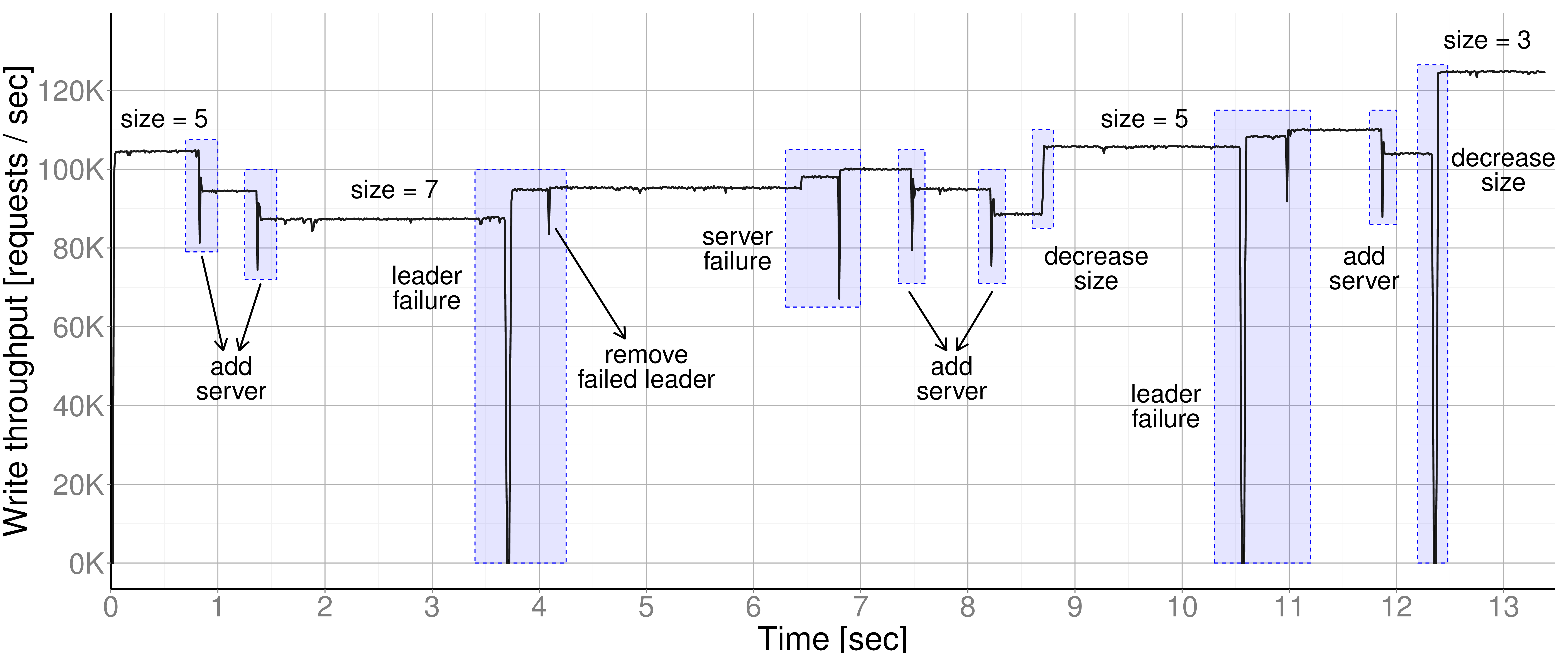
DARE’s write throughput during group reconfiguration.
The above figure shows the write throughput (for 64-byte requests) during a series of group reconfiguration scenarios.
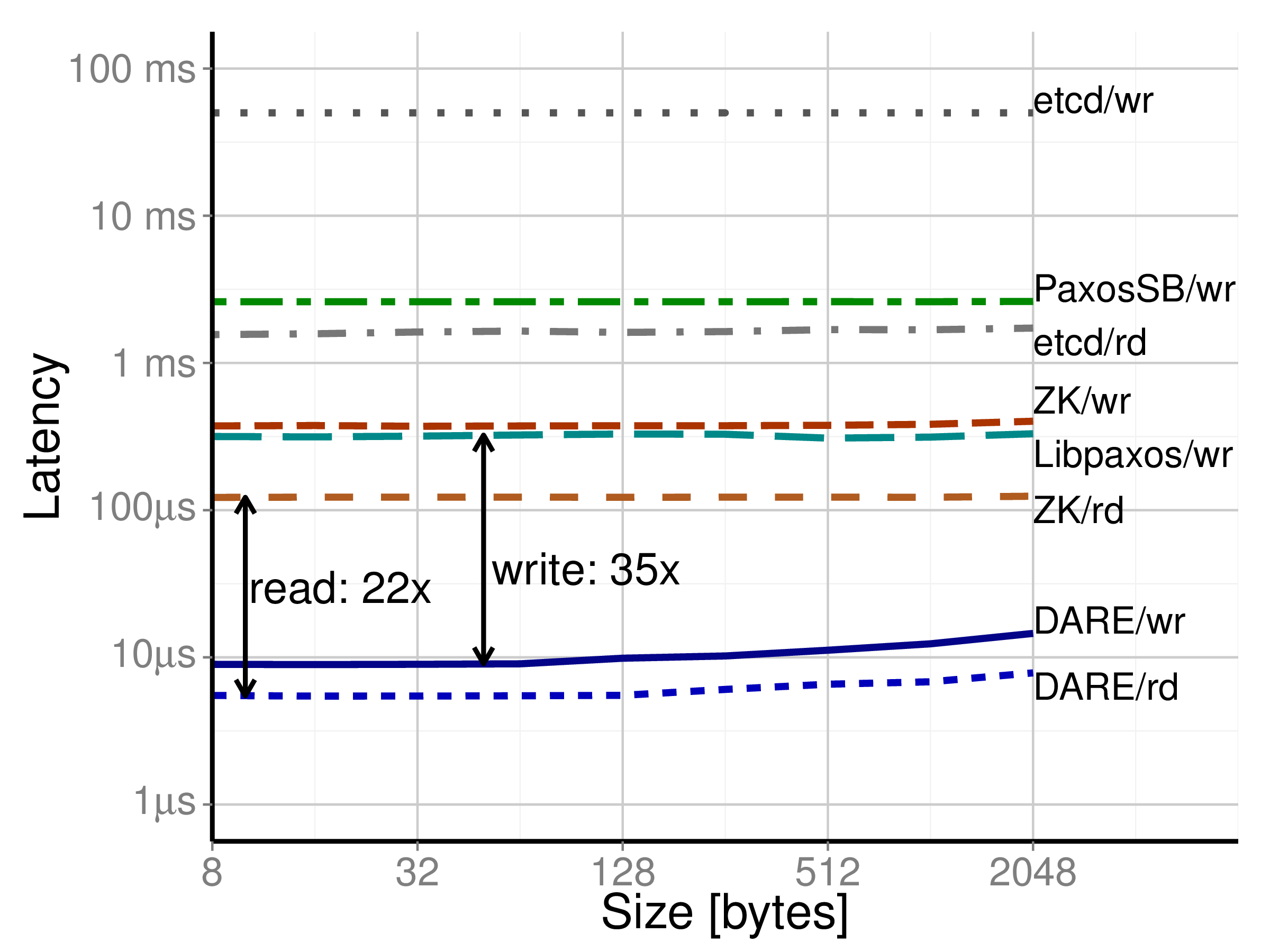
DARE and other RSM protocols: write (/wr) and read (/rd) latency.
To compare DARE with other protocols and implementations, we measure the latency of four applications: ZooKeeper (ZK), a service for coordinating processes of distributed applications; etcd, a key-value store that uses Raft for reliability; and PaxosSB and Libpaxos3, both implementations of the Paxos protocol, providing support only for writes.
For each application, we implemented a benchmark that measures the request latency in a similar manner as for DARE—a single client sends requests of varying size to a group of five servers. All applications use TCP/IP for communication; to allow a fair comparison, we utilize TCP/IP over InfiniBand (“IP over IB”). Also, for the applications that rely on stable storage, we utilize a RamDisk (an in-memory filesystem) as storage location. The above figure shows the request latency of the four applications on our system. Also, the figure compares our protocol against all four applications. The latency of DARE is at least 22 times lower for read accesses and 35 times lower for write accesses.
Extended Technical Report
A more detailed discussion on both the safety and the liveness of DARE can be found in the extended technical report (TR). Also, the TR contains the details of DARE's reliability estimation.
Download
Our implementation of DARE can be downloaded at one of the following links.
| Version | Date | Changes |
| dare-0.2.tgz - (0.6 mb) | June 14, 2016 | Version 0.2 |
| dare-0.1.tgz - (0.6 mb) | October 18, 2014 | First release |
Acknowledgments
DARE is funded as part of the ARRID project by Microsoft Research as part of the Swiss Joint Research Centre.
References
| [1] M. Poke, T. Hoefler: | ||
DARE: High-Performance State Machine Replication on RDMA Networks
In Proceedings of the 24th International Symposium on High-Performance Parallel and Distributed Computing (HPDC'15), presented in Portland, OR, USA, pages 107--118, ACM, ISBN: 978-1-4503-3550-8, Jun. 2015, (acceptance rate: 16% (19/116)) 

| ||