|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










Hardware Transactions for Graph Processing
The key idea in a single sentence
Hardware transactional memory does not only offer programmability but can also
accelerate graph processing on both shared- and distributed memory machines.
(This work is described in more detail in the paper "Accelerating Irregular
Computations with Hardware Transactional Memory and Active Messages").
Key motivation
Graph processing is a very important part of today's HPC and Big Data computations. Two challenges related to these workloads are: (1) fine-grained nature that makes efficient and simple synchronization difficult to design, and (2) large datasets that require distributed storage. We tackle these challenges with hardware transactional memory (HTM) that has recently been deployed in hardware by various vendors (Intel, IBM, Azul, Sun). We show (1) how to use HTM's programmability but also ensure performance higher than any other synchronization mechanism, and (2) how to use HTM in a distributed-memory environment.
Summary of work
Our work consists of three parts.
- Showing that transactions can offer fast synchronization for graph algorithms on single shared-memory domains: Here, we conduct performance modeling and analysis to illustrate that hardware transactions enable programmability and ensure highest performance in various scenarios and for various architectures. We also identify cases where transactions come with inherent overheads and are always outperformed by atomic operations.
- Showing how to execute HTM on distributed-memory systems: HTM natively works only on shared-memory systems. We next describe schemes that enable running transactions that may modify vertices that are located on a remote shared-memory domain or span more than one domain (e.g., on multiple compute nodes).
- Proposing unified and simple developing of graph algorithms:
Developing a graph algorithm that directly uses shared- and distributed-memory
transactions would be challenging. Here, we incorporate the active messaging
abstraction to simplify programming (an active message is a message that, when
received, it executes some selected code handler in the memory of the destination process).
The user develops an algorithm using
active message passing but the runtime system ensures that a message handler is
executed as a hardware transaction. We call the resulting mechanism
Atomic Active Messages (AAM).
AAM packages the fact that a transaction can be local (e.g., if all the vertices inside
the transaction are on the same shared-memory domain) or not (e.g., if the required vertices
are located on more than a single shared-memory domain).
In benchmarks, we consider the following parameters and aspects:- Types of architecture: a commodity server (Haswell), a small HPC cluster (Haswell), and a supercomputer (BlueGene/Q (BGQ)).
- Types of HTM: Restricted Transactional Memory (RTM, Haswell), Hardware Lock Elision (HLE, Haswell), the Long Running Mode HTM (BlueGene/Q), the Short Running Mode HTM (BlueGene/Q).
- Scalability: various counts of threads and processes.
- Amount of contention inside transactions.
- Families of graphs: various densities and degree distributions.
Key findings and discoveries
- HTM can outperform atomic operations: The most important conclusion is that hardware transactions do not only offer programmability but they can also ensure high performance for graph processing. We achieve this by coarsening: a transaction processes more than one vertex to amortize the commit/abort overhead. Other findings include:
- Choice between HTM and atomics depends on the algorithm: In some algorithms (e.g., Breadth-First Search), transactions offer the best performance. In others (e.g., PageRank), atomic operations come with better speedups because transactions come with inherent overheads. In the paper, we discover a hierarchy of graph algorithms that enables categorizing the algorithms into one of these two classes. This facilitates design choices on which synchronization mechanism to select.
- HTM in L2 may be a better choice than HTM in L1: Our benchmarks indicate that implementing HTM in the bigger L2 cache (BlueGeneG/Q) with higher associativity enables higher speedups (over the baseline that uses atomic operations) than in the smaller L1 cache (Haswell). On the other hand, L1 comes with lower latency and thus higher absolute performance. We believe our analysis and data can be used by architects and engineers to develop a more efficient HTM that would offer even higher speedups for irregular data analytics.
- HTM can be used in distributed settings: HTM can be applied in the distributed setting. Our method is to transfer transactions in messages or, if necessary, relocate the data required by a transaction to one shared-memory domain, execute the transaction, and then optionally send the relocated data back.
Scheme 1: Coarsening of vertices inside transactions
In coarsening, some transactions (see the figure below) process more than one vertex to amortize the commit/abort overhead.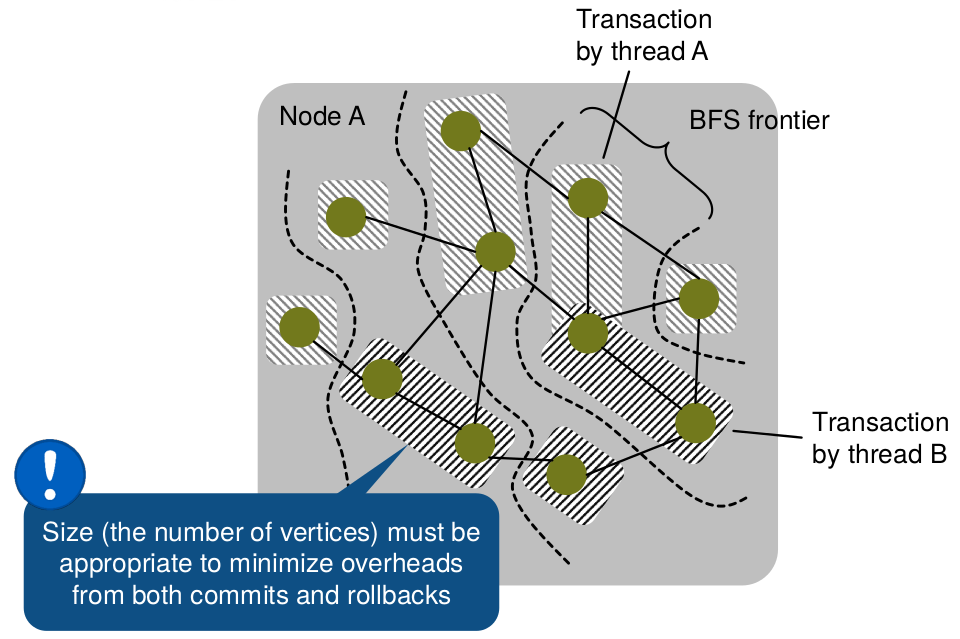
Coarsening of vertices inside transactions during a BFS graph traversal.
Scheme 2: Executing remote transactions
In some cases, a transaction might be initiated at Node A, but its targeted vertices could be located elsewhere. In such a case, we transfer this transaction in an active message to its destination node: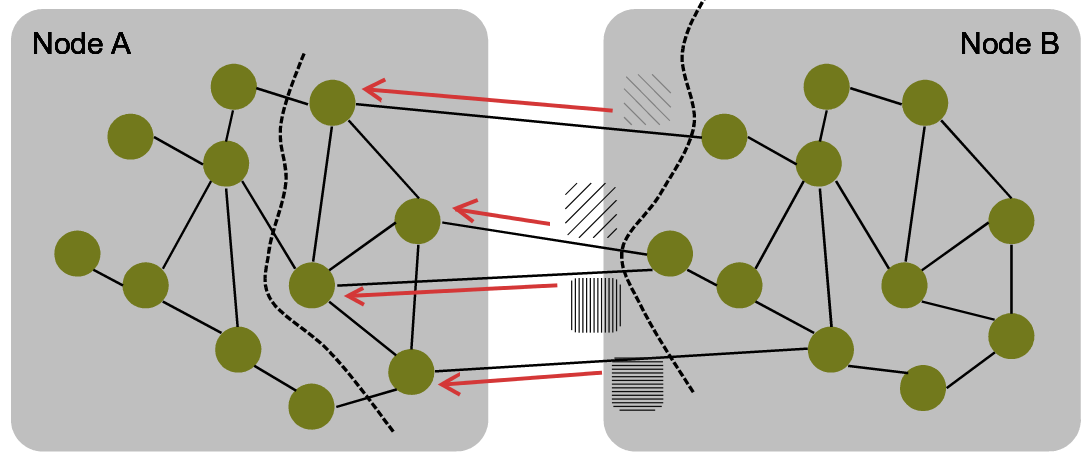
Four transactions must be sent to Node B to process remote vertices.
If there are multiple such transactions, they are coalesced in one message to save bandwidth:
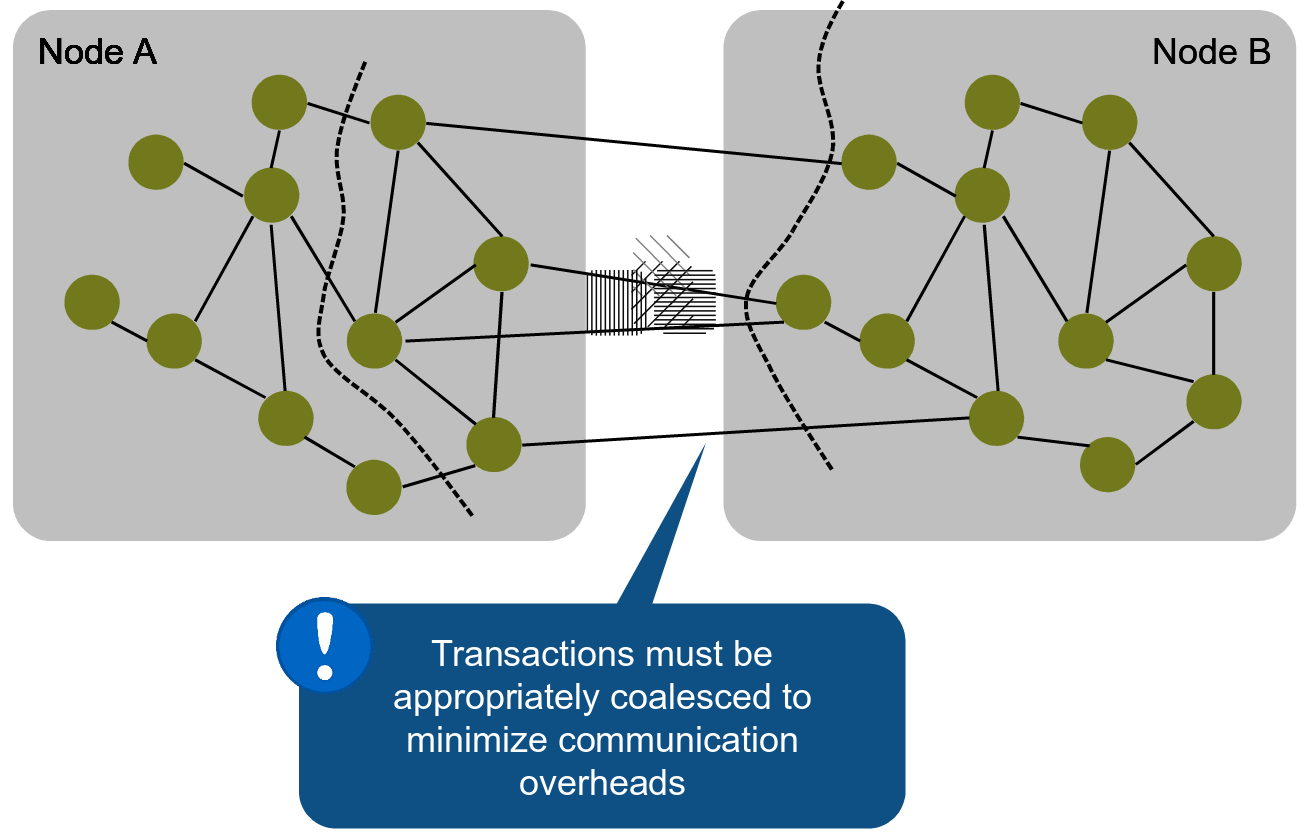
Four transactions are coalesced to save bandwidth.
Scheme 3: Executing distributed transactions
Below, we illustrate a scenario when a transaction is distributed. Natively, no existing HTM system can execute such a transaction.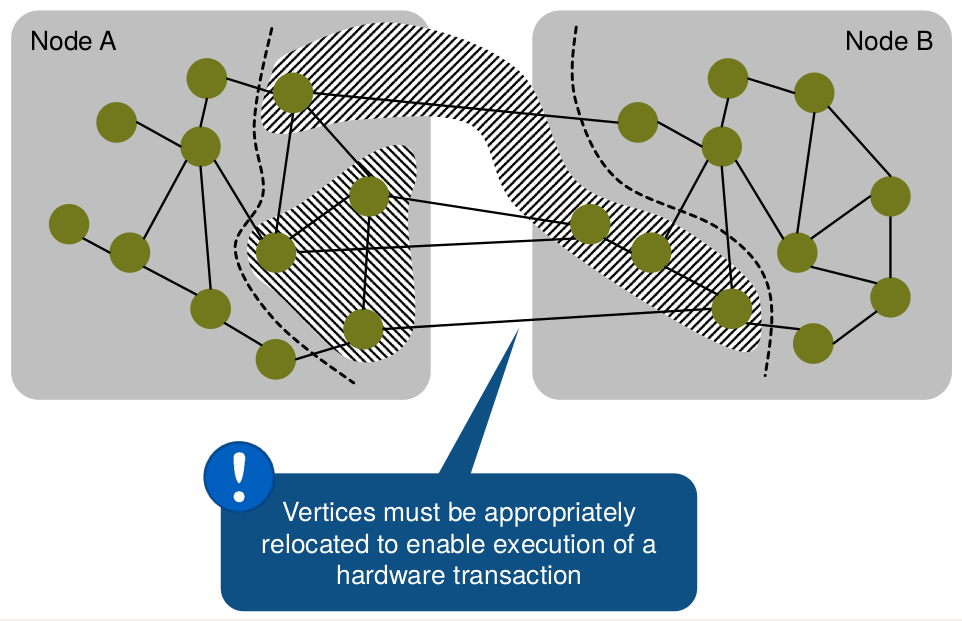
A distributed transaction before relocation. The transaction is rearranged by relocating some of the vertices so that a native HTM system can be incorporated.
Performance model
We use a performance model to support the claim that coarsening vertices
can amortize the overhead of committing/aborting transactions.
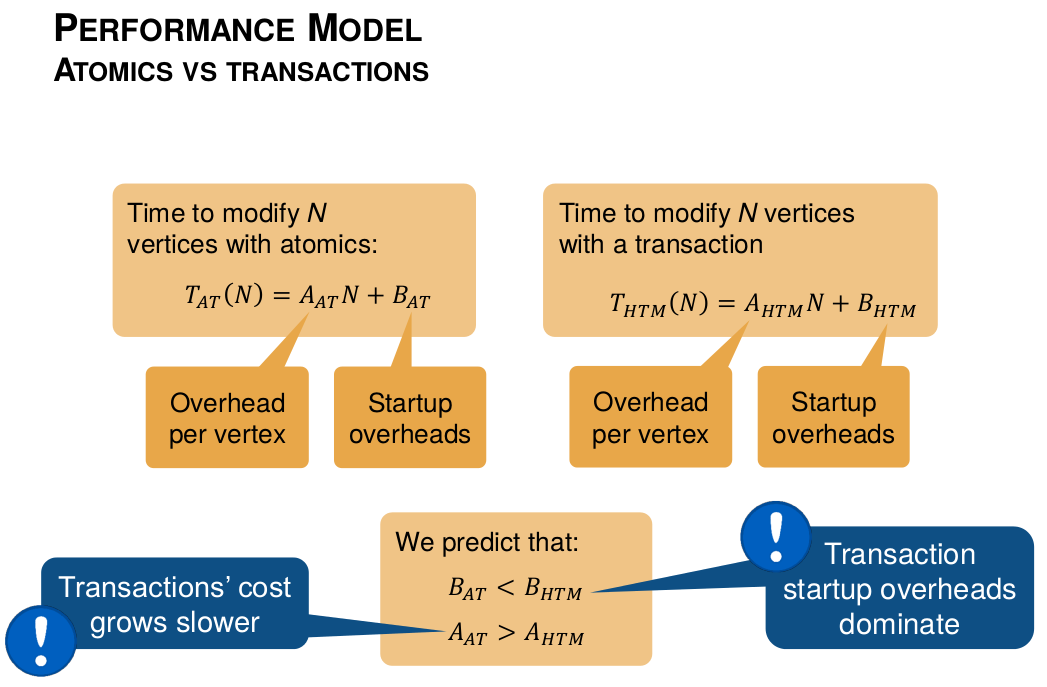
The performance model.
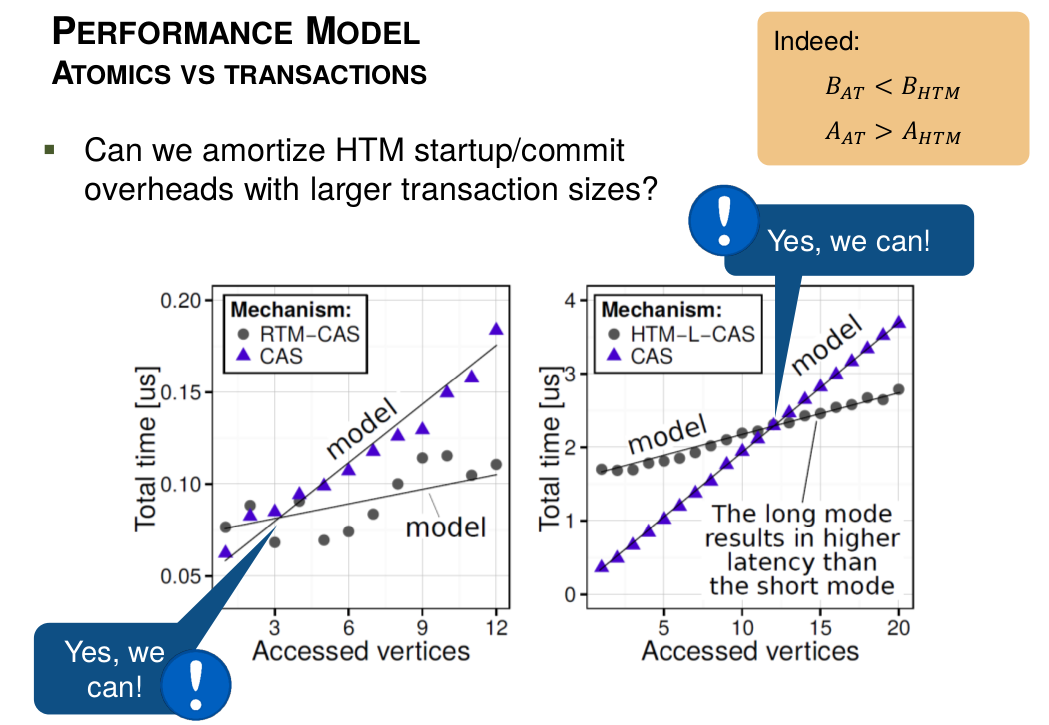
The performance model vs the results. Each data point indicates the time to accesses N vertices with Compare-and-Swap operations that are either implemented as the actual atomic CASes or as code inside a single transaction. The left plot is the analysis for Haswell while the right one refers to BGQ. RTM-CAS stands for Haswell HTM (RTM), CAS is the atomics-based implementation on each architecture, and HTM-L-CAS is the Long Running Mode variant of HTM on BGQ.
Selected interesting analyses
Various sizes of transactions give various speedups:
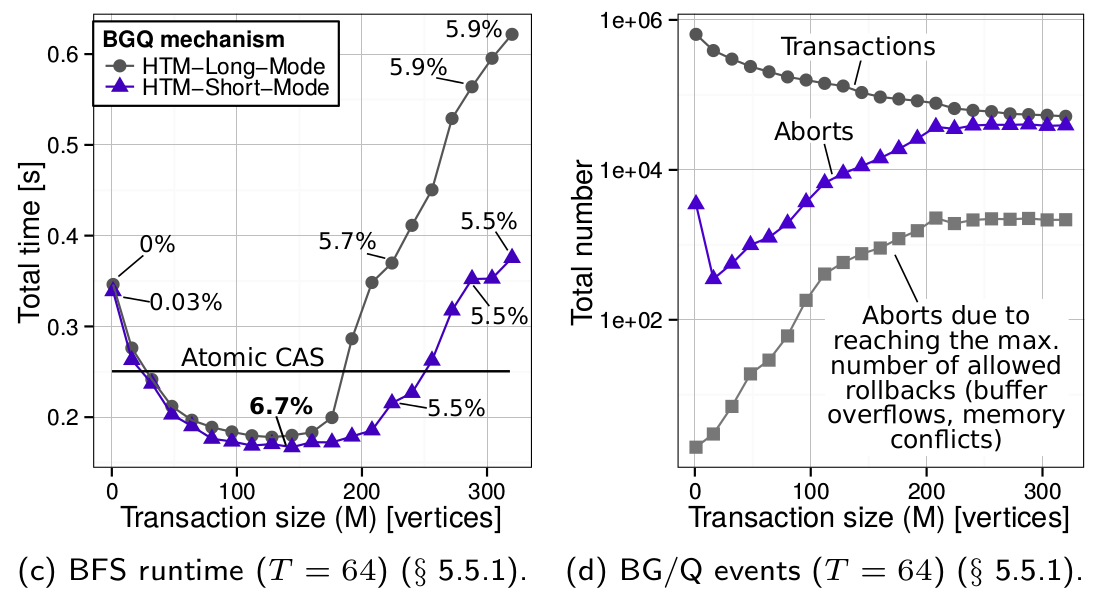
The analysis of the performance of Graph500 OpenMP BFS implemented with hardware transactions on BGQ (64 parallel threads) and atomics (the straight line). In each figure we vary the size of the transactions M (i.e., the number of vertices visited). We also present the results for BFS implemented with atomics (the horizontal lines). The percentages indicate the ratios of the numbers of serializations caused by reaching the maximum possible number of rollbacks to the numbers of all the aborts. Bolded numbers indicate the points with the minimum runtime per figure.
Performance analysis of various types of graphs on BGQ:
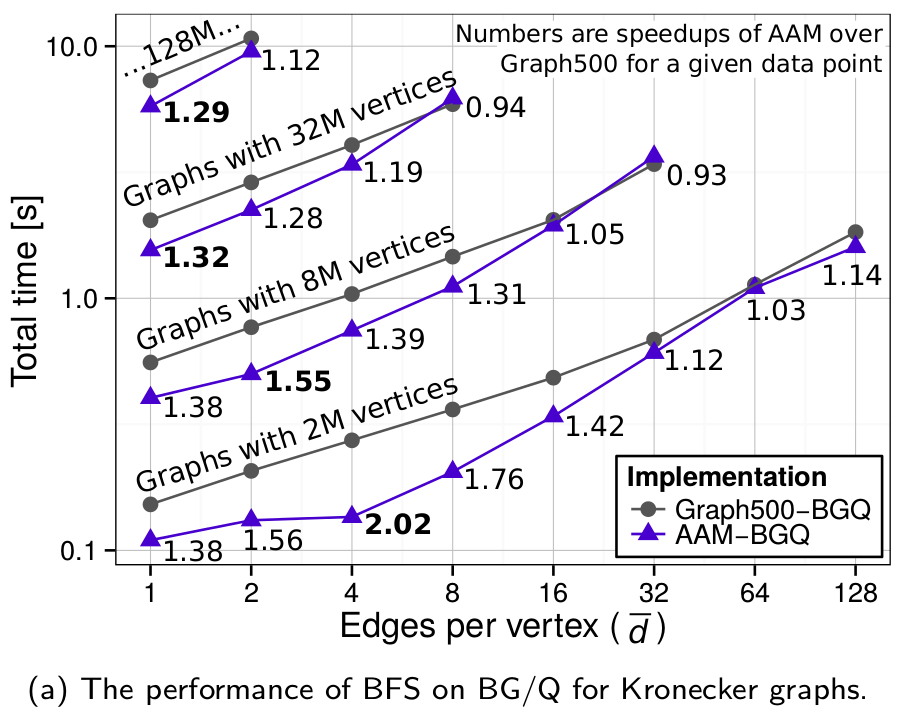
The overview of the performance of intra-node Graph500 BFS implemented with atomics (Graph500-BGQ) and the short mode BGQ HTM (AAM-BGQ).
Performance analysis of various types of graphs on Haswell:
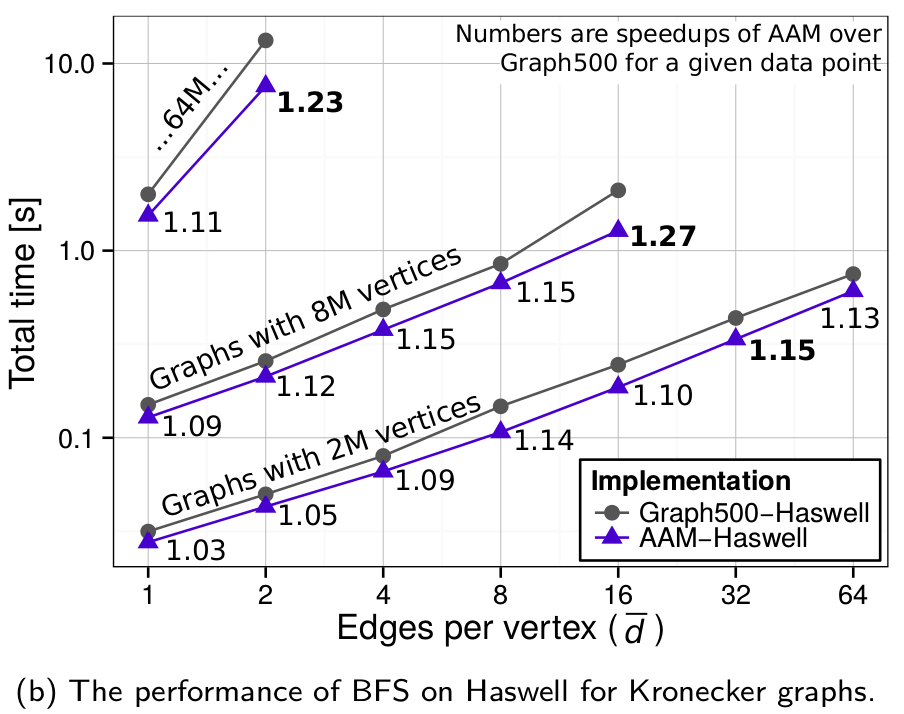
The overview of the performance of intra-node Graph500 BFS implemented with atomics (Graph500-Haswell) and the short mode BGQ HTM (AAM-Haswell).
Others
The accompanying technical report: TR
References
| [1] M. Besta, T. Hoefler: | ||
Accelerating Irregular Computations with Hardware Transactional Memory and Active Messages
In Proceedings of the 24th Symposium on High-Performance Parallel and Distributed Computing (HPDC'15), presented in Portland, OR, USA, pages 161--172, ACM, ISBN: 978-1-4503-3550-8, Jun. 2015, (acceptance rate: 16% (19/116)) Best Paper at HPDC'15 (1/19) 


| ||