|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










sPIN: High-performance streaming Processing in the Network
Motivation
Optimizing communication performance is imperative for large-scale computing because communication overheads limit the strong scalability of parallel applications. Today’s network cards contain rather powerful processors optimized for data movement. However, these devices are limited to fixed functions, such as remote direct memory access. We develop sPIN, a portable programming model to offload simple packet processing functions to the network card. To demonstrate the potential of the model, we design a cycle-accurate simulation environment by combining the network simulator LogGOPSim and the CPU simulator gem5. We implement offloaded message matching, datatype processing, and collective communications and demonstrate transparent full-application speedups. Furthermore, we show how sPIN can be used to accelerate redundant in-memory filesystems and several other use cases. Our work investigates a portable packet-processing network acceleration model similar to compute acceleration with CUDA or OpenCL. We show how such network acceleration enables an eco-system that can significantly speed up applications and system services.
Abstract Machine Model
We design sPIN around networking concepts such as packetization, buffering, and packet steering. Packetization is the most important concept in sPIN because unlike other networking layers that operate on the basis of messages, sPIN exposes packetization to the programmer. Programmers define header, payload, and completion handlers (kernels) that are executed in a streaming way by handler processing units (HPUs) for the respective packets of each matching message. Handlers can access packets in fast local memory and they can communicate through shared memory. sPIN offers protection and isolation for user-level applications and can thus be implemented in any environment.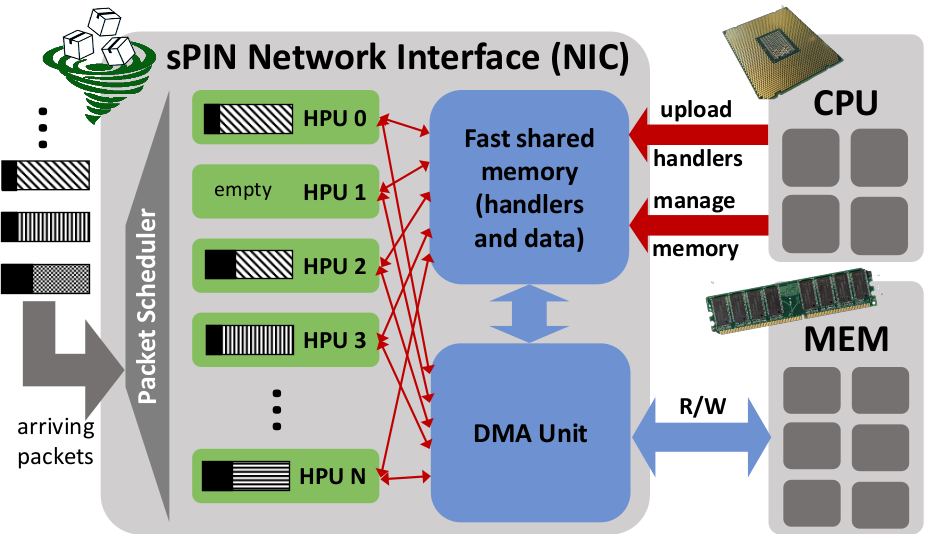
sPIN's philosophy is to expose the highly-specialized packet processors in modern NICs to process short user-defined functions. By "short", we mean not more than a few hundred instructions from a very simple instruction set. In this sense, handlers are essentially pluggable components of the NIC firmware. sPIN offers unprecedented opportunities to accelerate network protocols and simple packet processing functions and it can be implemented in discrete NICs, SoCs, or even in parts of CPU cores. Offering programmable network devices liberates the programmer from restricted firmware functionalities and custom accelerators and is the next step towards full software-defined networking infrastructures.
Programming Interface
sPIN defines three handler types to be invoked on different parts of a message: the header handler works on header information, the payload handler processes the message payload after the header handler completes, and the completion handler executes after all instances of a payload handler have completed. There is no requirement that packets arrive or are processed in order.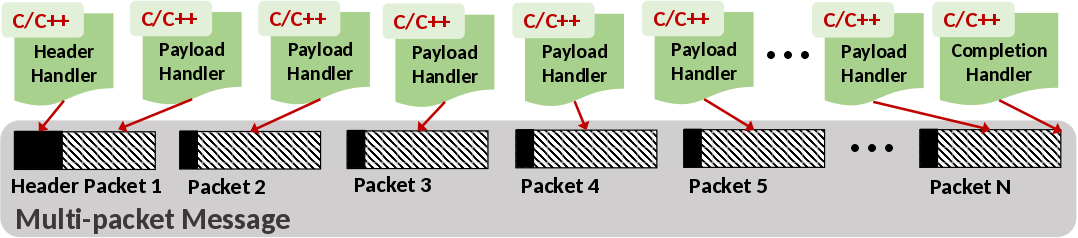
Handlers are programmed by the user as standard C/C++ code to enable portable execution and convenient programming. They can only contain plain code, no system calls or complex libraries. Handlers are then compiled to the specific target network ISA. The program can contain static segments of pre-initialized data. Handlers are not limited in their execution time, yet, resources are accounted for on a per-application basis. This means that if handlers consume too much time, they may stall the NIC or drop packets. Thus, programmers should ensure that handlers can operate at line-rate on the target device.
The function decoration __handler indicates that this function must be compiled for the sPIN device. Handler code is passed at connection establishment. This allows a single process to install different handlers for different connections. Arguments are the packet data and *state, which references local memory that is shared among handlers.
Header Handler: The header handler is called exactly once per message and no other handler for this message is started before the header handler completes. It has access to only the header fields that can include user-defined headers (the first bytes of the payload). User-defined headers are declared statically in a struct to enable fast parsing in hardware. Yet, the struct offers flexibility as it guarantees no specific memory layout. For example, pre-defined headers could be in special registers while user-defined headers can reside in HPU memory. The struct is static such that it can only be used on the right-hand side of expressions. This makes it possible to implement using registers.
__handler int header_handler(const ptl_header_t h, void *state);
Payload Handler: The payload handler is called after the header handler completes for packets carrying a payload. Multiple instances of the payload handler can be executed in parallel and the programmer must account for concurrent execution. Payload handlers share all HPU memory coherently. The illusion of private memory can be created by the programmer, yet no protection exists.
__handler int payload_handler(const ptl_payload_t p, void * state);
Completion Handler The completion handler is called once per message after all header handlers and payload handlers have completed but before the completion event is delivered to the host. The handler can be used for final data collection or cleanup tasks after the message has been processed. The value in dropped_bytes indicates how many bytes of payload data have been dropped by payload handlers. The flag flow_control_triggered indicates that flow control was triggered during the processing of this message and thus some packets may have been dropped without being processed by payload handlers. The pointer state points t the initial data in HPU memory. This data may have been initialized by the host or header handler.
__handler int completion_handler(int dropped_bytes, bool flow_control_triggered, void *state);
Evaluation
To evaluate sPIN at scale, we combine two open-source simulators that have been vetted extensively by the research community: LogGOPSim to simulate the network of parallel distributed memory applications and gem5 to simulate various CPU and HPU configurations. LogGOPSim supports the simulation of MPI applications, injection of system noise, and has been calibrated and validated on InfiniBand clusters. The cycle-accurate gem5 simulator supports a large number of different CPU configurations and is thus an ideal choice for our designs. The detailed simulation configuration can be found in the paper.Ping-Pong
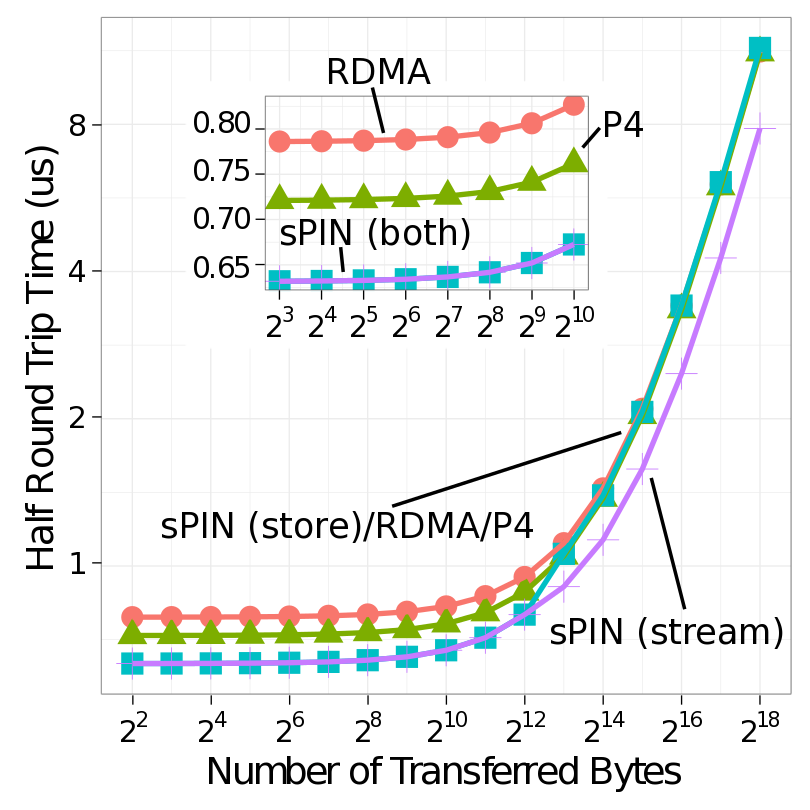
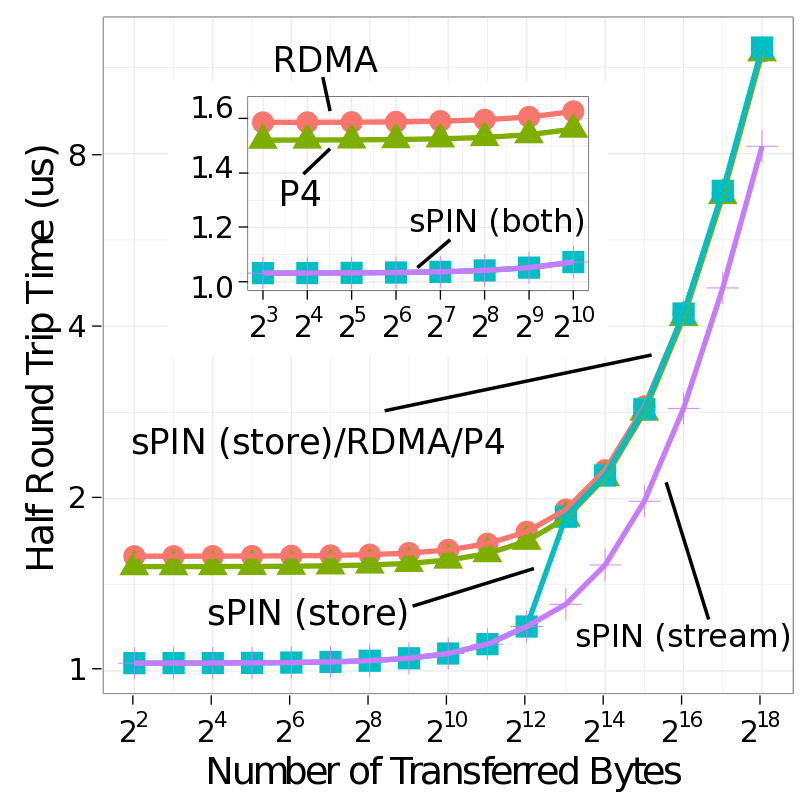
We compare our two sPIN systems with standard RDMA as well as Portals 4 with a simple ping-pong benchmark. This illustrates the basic capabilities of processing messages on the NIC. For RDMA and Portals 4, all messages need to be stored to and loaded from main memory. sPIN can avoid this memory traffic and reply directly from the NIC buffer, leading to a lower latency and less memory traffic at the host.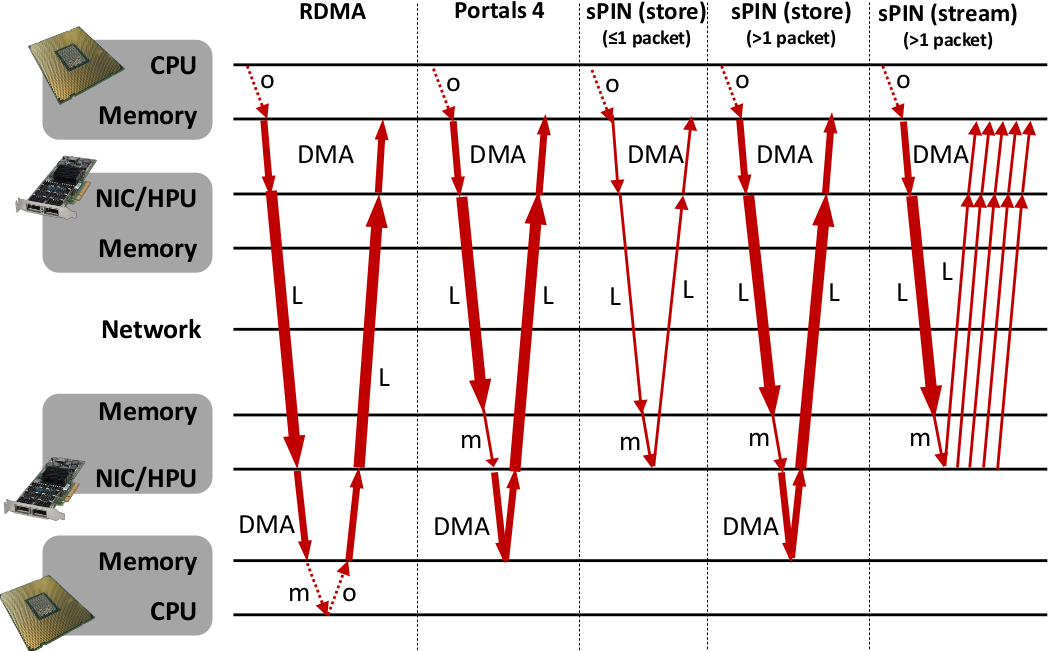
For RDMA, the pong message is sent by the main CPU. Thus, the destination CPU polls for a completion entry of the incoming ping message, performs message matching, and immediately posts the pong message. The completion will only appear after the whole message has been deposited into host memory. Processing occurs on the CPU, therefore, system noise may delay the operation. For Portals 4, the pong message is pre-set up by the destination CPU and the reply is automatically triggered after the incoming message has been deposited into host memory. Thus, system noise on the main CPU will not influence the pong message. Even though the message itself is automatically triggered, the data is fetched via DMA from the CPU’s main memory as in the RDMA case. In sPIN ping-pong, the ping message may invoke header, payload, and/or completion handlers. sPIN gives us multiple options for generating the pong message: (1) (store) the ping message consists of a single packet and a pong can be issued with a put from device, (2) (store) the ping message is larger than a packet and the pong message is issued with put from host using the completion handler after the packet is delivered to host memory, and (3) (stream) a payload handler could generate a pong put from device for each incoming packet. Here the NIC would act as a packet processor and split a multi-packet message into many single-packet messages. The first two correspond to store and forward processing for different message sizes while the last corresponds to fully streaming operation.
 |
 |
| Ping Pong (integrated NIC) | Ping Pong (discrete NIC) |
Header handler:
__handler int pingpong_header_handler(const ptl_header_t h, void *state) { pingpong_info_t *i = state; if (h.length > PTL_MAX_SIZE || !STREAMING) { i->stream = false; i->length = h.length; return PROCEED; //don't execute any other handler }else{ i->source = h.source_id; i->stream = true; return PROCESS_DATA; // execute payload handler to put from device } }
Payload handler:
__handler int pingpong_payload_handler(const ptl_payload_t p, void * state) { pingpong_info_t *i = state; PtlHandlerPutFromDevice(p.base, p.length, 1, 0, i->source, 10, 0, NULL, 0); return SUCCESS; }
Completion handler:
__handler int pingpong_completion_handler(int dropped_bytes, bool flow_control_triggered, void *state) { pingpong_info_t *i = state; if (!i->stream) PtlHandlerPutFromHost(i->offset, i->length, 1, 0, i->source, 10, 0, NULL, 0); return SUCCESS; }
Broadcast
We implement a binomial tree algorithm, which would require logarithmic space on a Portals 4 NIC and would thus be limited in scalability. In sPIN, the algorithm is not limited in scalability while it will occupy one HPU for its execution. We implemented the broadcast operation in RDMA on the CPU, in Portals 4 as predefined triggered operations, and with sPIN using store-and-forward as well as streaming HPU kernels. As for ping-pong, the store-and-forward mode sends messages that are smaller than a packet directly from the device and from host memory otherwise. Thus, the performance is always within 5% of the streaming mode for single-packet messages and to Portals 4 for multi-packet messages. Thus, we omit the store-and-forward mode from the plots.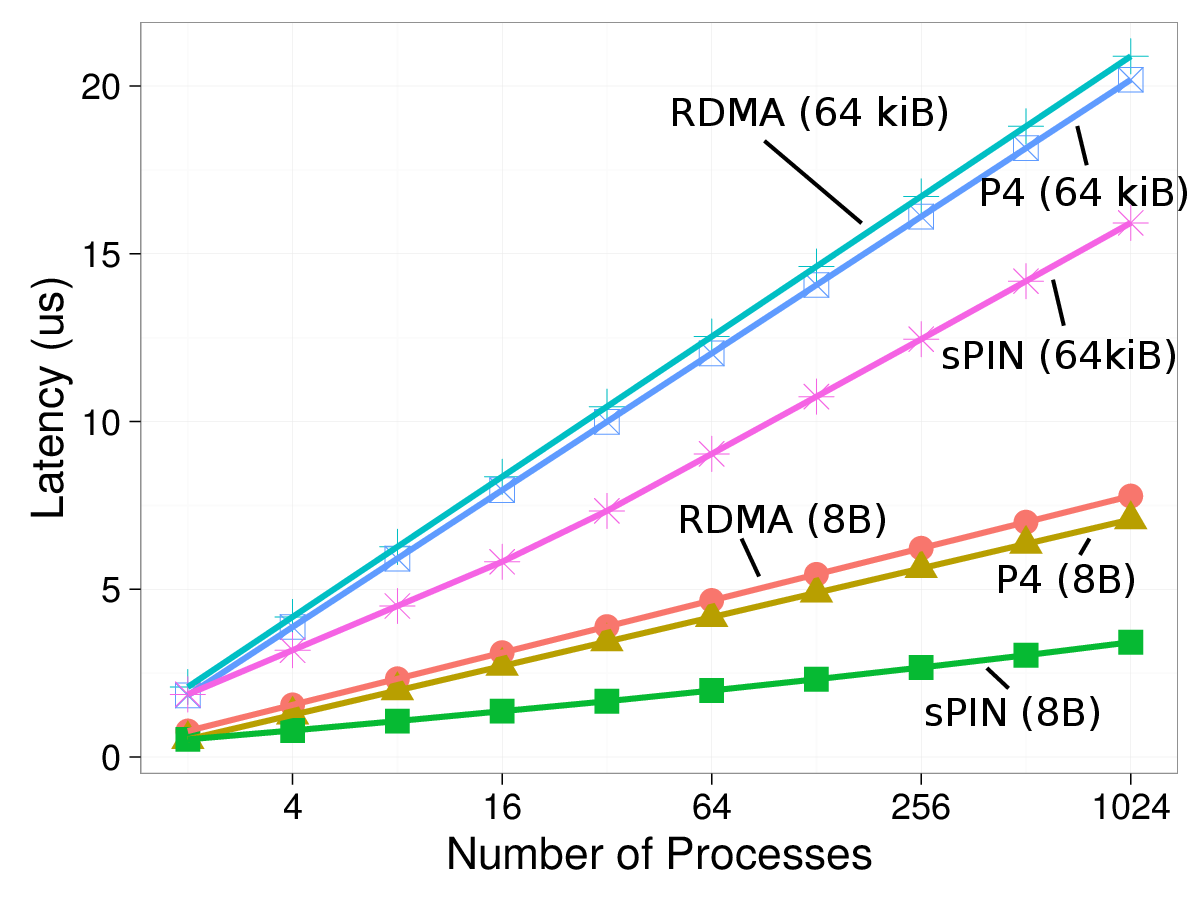
The above figure shows the small message (8 B) and large-message (64 KiB) case for varying numbers of processes and the different implementations. We observe the benefit of direct forwarding for small messages as well as streaming forwarding for large messages. We only show data for the discrete NIC configuration to maintain readability. The integrated NIC has slightly lower differences but sPIN is still 7% and 5% faster than RDMA and Portals 4 at 1,024 processes, respectively.
Other Use Cases
Please refer to the below linked paper for the full set of studied use cases and their evaluation.Download
| Version | Date | Changes |
| spin-0.9.tar.gz - (7.2 MB) | November 01, 2017 | First release |
References
| [1] S. Di Girolamo, K. Taranov, A. Kurth, M. Schaffner, T. Schneider, J. Beránek, M. Besta, L. Benini, D. Roweth, T. Hoefler: | ||
Network-Accelerated Non-Contiguous Memory Transfers
In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC19), Nov. 2019, (acceptance rate: 22.7% (78/344)) 


| ||
| [1] T. Hoefler, S. Di Girolamo, K. Taranov, R. E. Grant, R. Brightwell: | ||
| sPIN: High-performance streaming Processing in the Network
In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC17), Nov. 2017, (acceptance rate: 18% (61/327)) Best Paper Finalist at SC17 (5/61)
| ||