|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










Active Access: A Mechanism for High-Performance Distributed Data-Centric Computations
The key idea in a single sentence
RMA puts and gets can execute remote code handlers when accessing designated memory addresses to improve the performance of RMA workloads and to enrich and accelerate distributed virtual memory systems.
Key motivation: Improving RMA
RMA and PGAS are becoming an important mechanism and abstraction used to
develop HPC and data-center codes that fully utilize the capabilities of the
underlying networking hardware. RMA puts and gets offer high-performance
one-sided communication. However, they entail significant overheads in certain
workloads.
Consider a distributed hashtable. RMA programming improves its
performance in comparison to Message Passing (MP) up to 5x [19] (the reference can
be found in [ICS'15]) if there is no hash collision:
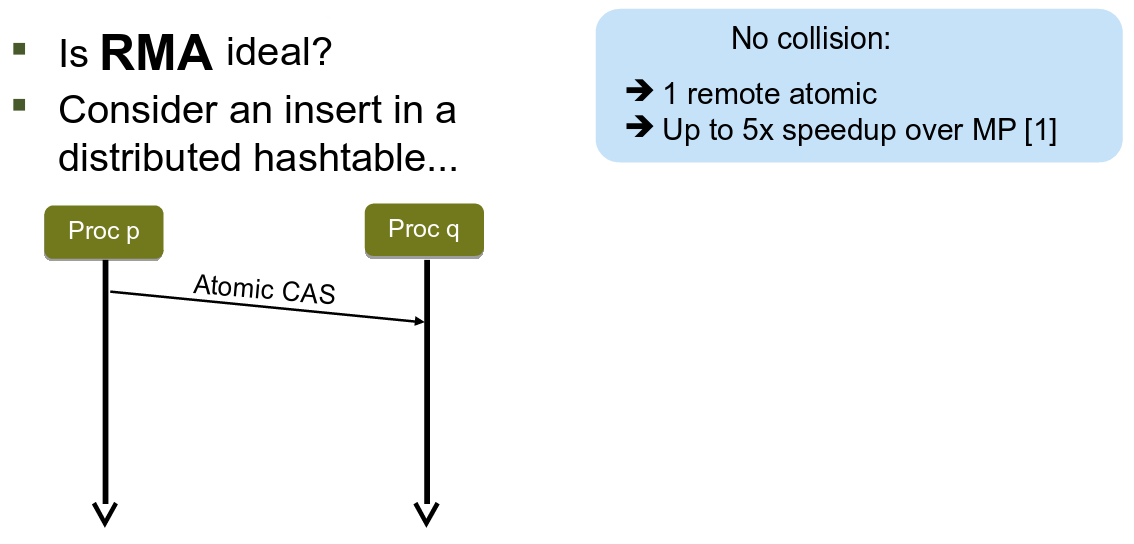
RMA offers very fast inserts into a distributed hashtable if there are no hash collisions. This is thanks to the one-sided communication model of RMA that takes the best of the capabilities of the underlying networking hardware.
Yet, hash collisions impact performance as handling them requires to issue many expensive remote atomic operations (Compare-and-Swap, Fetch-and-Add) and additional memory accesses:
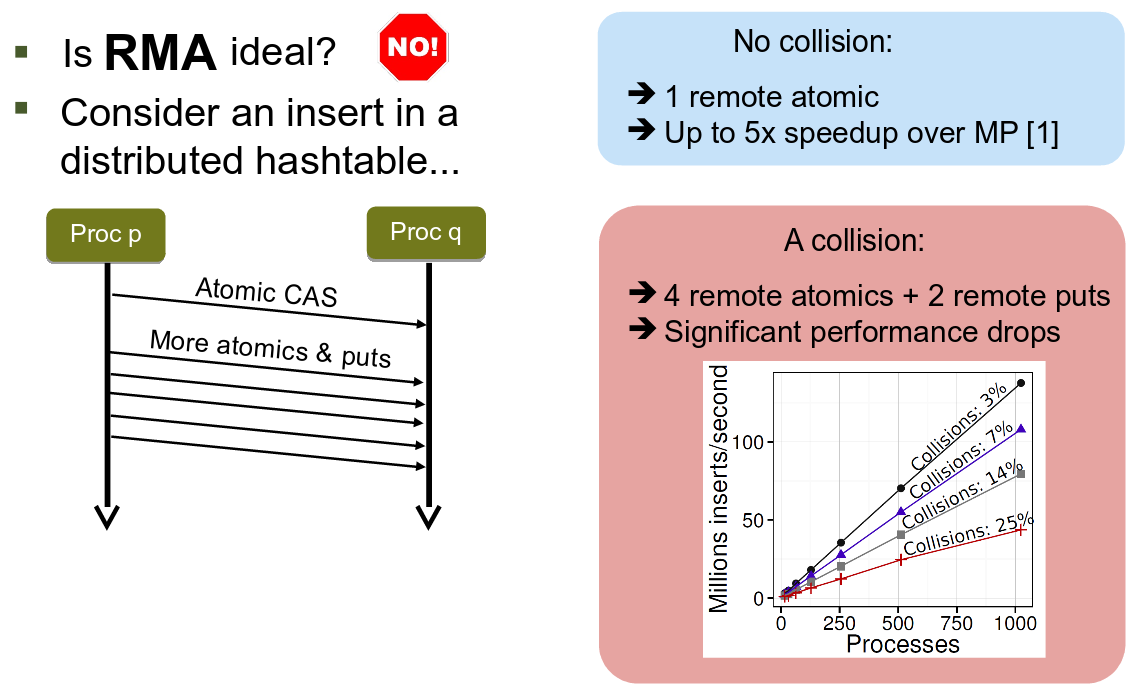
Hash collisions require issuing multiple remote atomics and memory accesses. The one-sided communication model of RMA shows its flaws.
Ideally, we would like a mechanism in which a memory access that touches the hashtable data and causes a hash collision invokes a handler that solves the collision locally. We develop such a mechanism and call it Active Access (AA). In AA, puts and gets become active puts and active gets. Below, an example active put manages the hash collision locally:
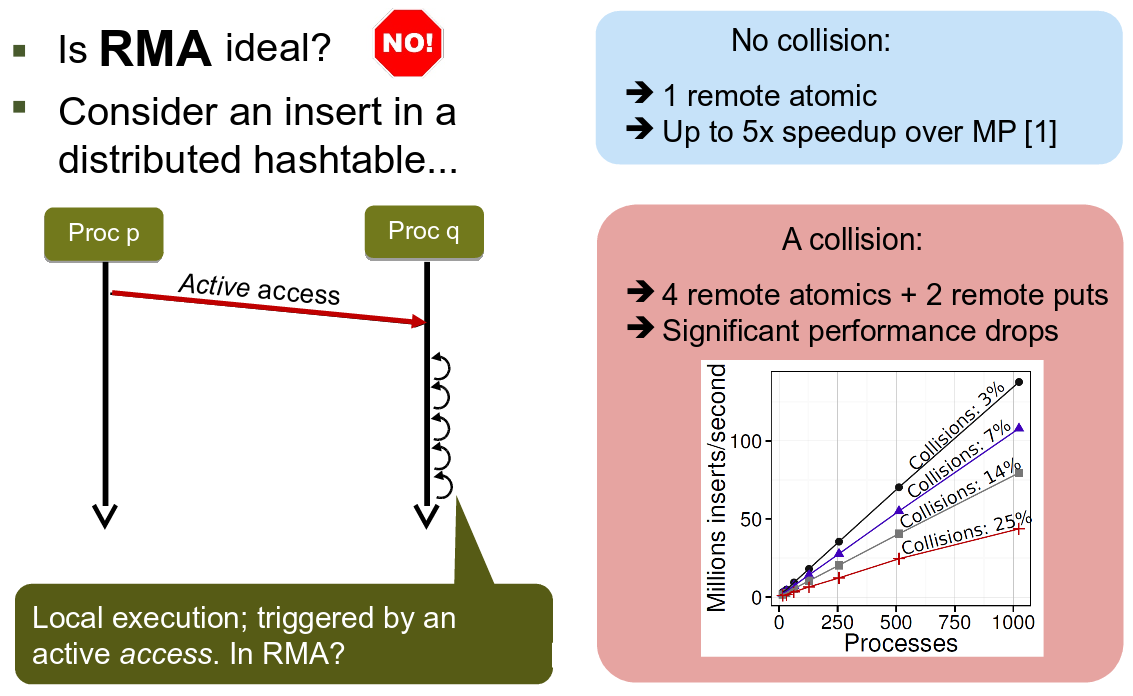
Active Access requires only one remote memory access in the event of a hash collision.
Key method
To develop Active Access and active puts/gets, we propose to use and extend the Input/Output Memory Management Unit (IOMMU): a piece of hardware that sits between the Network Interface Controller (NIC) and the main memory, and is able to intercept the traffic between these two. Thus, it is conceptually similar to the MMU:
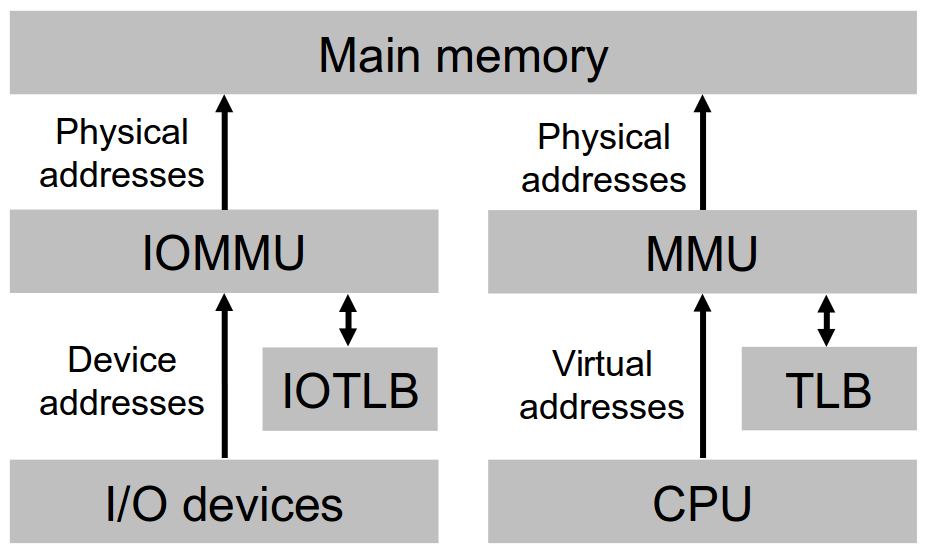
The IOMMU and the MMU.
In the paper, we illustrate a detailed set of extensions to the IOMMU to enable Active Access. A teaser can be found below:
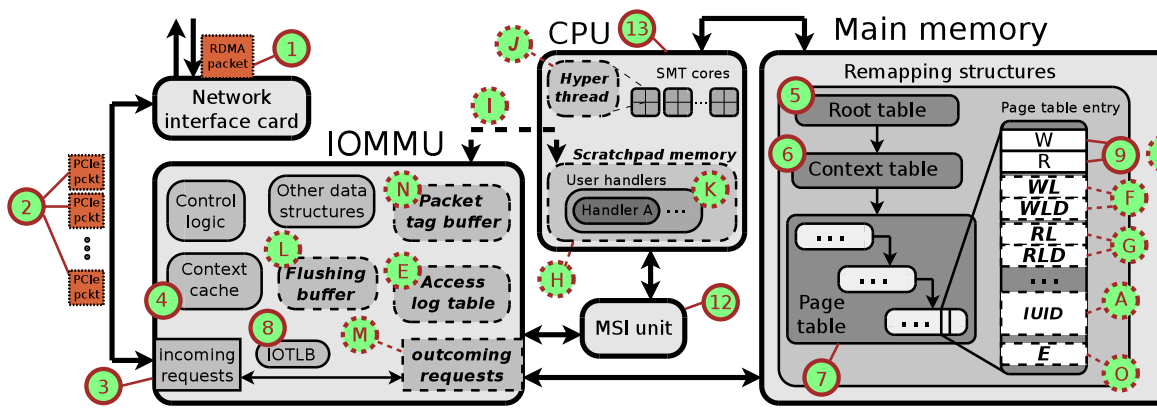
Extending the IOMMU to enable Active Access: The overview of the IOMMU and the cooperating devices. The proposed extensions are marked with dashed edges and bold-italic text. Solid circles with numbers indicate the specific steps discussed in detail in the paper. Dashed circles are extensions presented in the paper.
Summary of work
Our work consists of the following parts.
- Proposing IOMMU extensions to enable active puts and gets: We conduct a detailed analysis of the Intel IOMMU technology (Intel VT-d) as well as PCI Express (PCIe) and illustrate how it can be extended to enable Active Access.
- Designing consistency model for Active Access: We describe the consistency of Active Access similar to that of MPI-3 RMA.
- Illustrating Active Access programming: We show how to use Active Access to develop various codes such as distributed hashtables, logging protocols, and fault tolerance schemes.
- Evaluation: We conduct several benchmarks, illustrating the advantages of Active Access over mechanisms such as Active Messages, RMA, and Message Passing.
- Discussing Virtual Global Address Space: We briefly describe Active Access could enable hardware-based virtual
global address space (V-GAS) with novel enhanced paging
capabilities and data-centric handlers running transparently
to any code accessing the memory.
Key findings and discoveries
- RMA's advantages can be combined with those of Message Passing and Active Messages: Our work illustrates that the advantages of the one-sided communication model of RMA (and the PGAS abstraction) can be combined with those of the two-sided communication delivered by Message Passing and Active Messages.
- RMA can be made data-centric: In Active Access, the execution of the handlers is guided by the data and its addresses.
- IOMMUs could be used to accelerate state-of-the-art HPC and data center codes: The design of Active Access illustrates an interesting novel case for the utilization of IOMMUs.
Active puts and gets
We now illustrate active puts (and gets). Numbers in green circles indicate what happens at each step of an active put (and a get). An access log is a data structure where the payload transferred by a put (and a get) is redirected (copied) by the IOMMU. For more details and explanations, check the paper and the slides.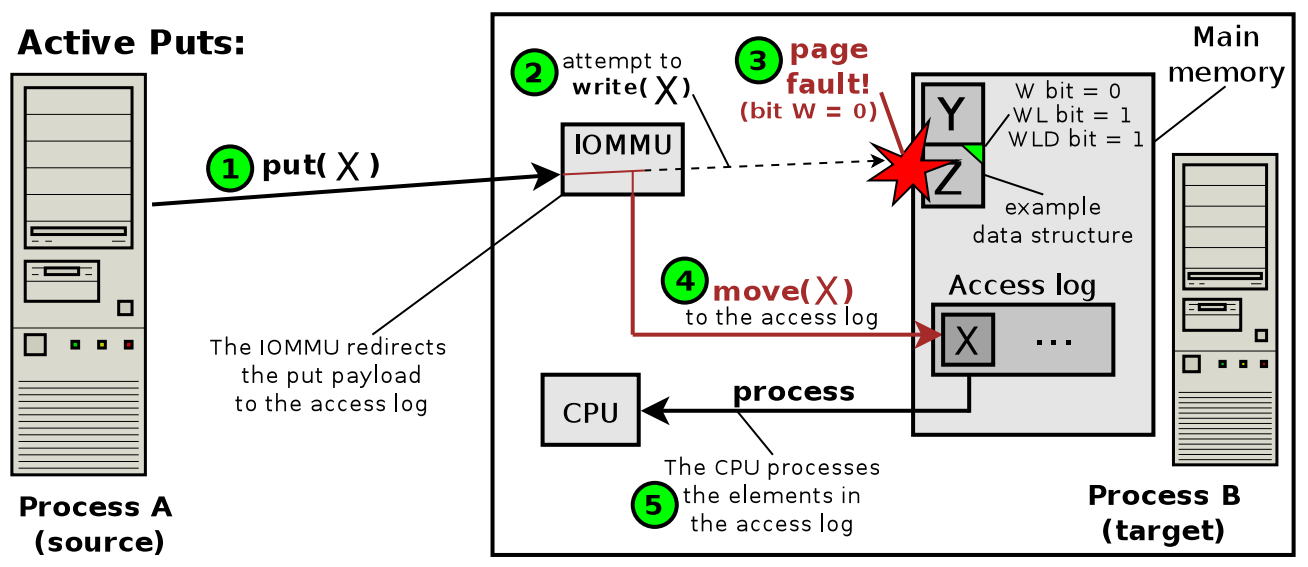
An active put
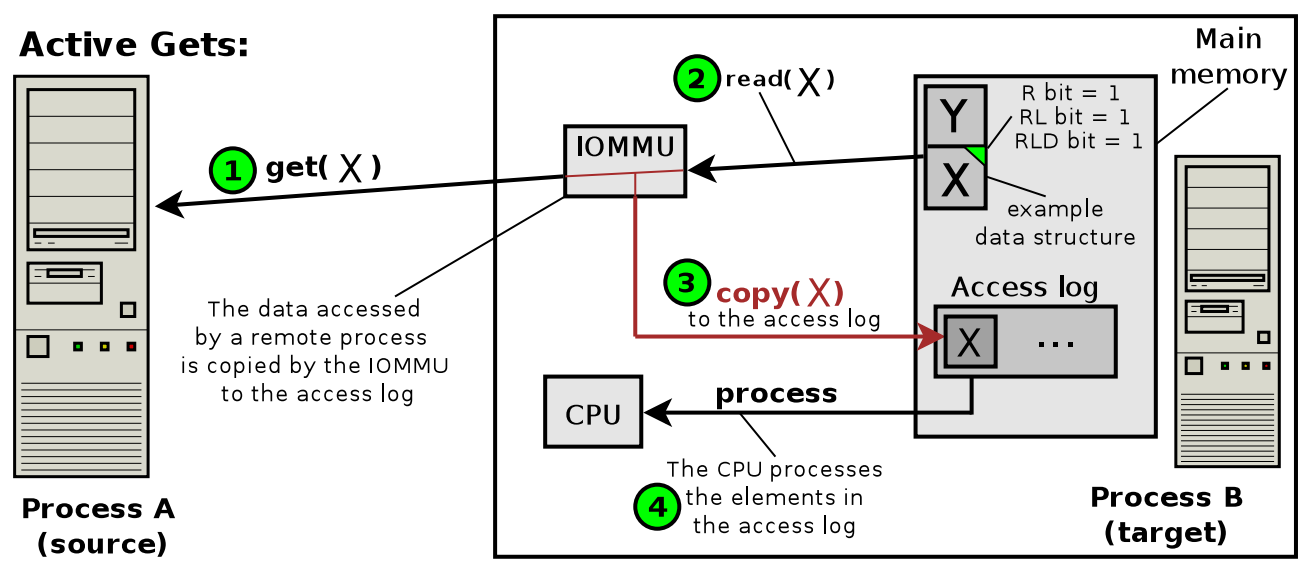
An active get
Hardware-based virtual global address space
Active Access could be used to develop a hardware-based virtual global address space with novel enhanced paging capabilities and data-centric handlers running transparently to any code accessing the memory.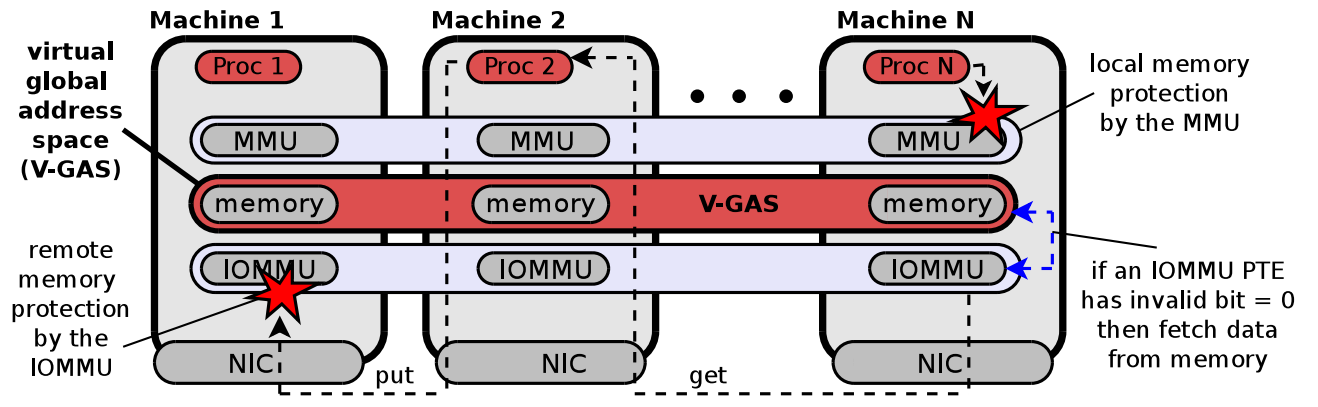
Hardware-based virtual global address space.
Selected interesting analyses
Here, we present several performance analyses.
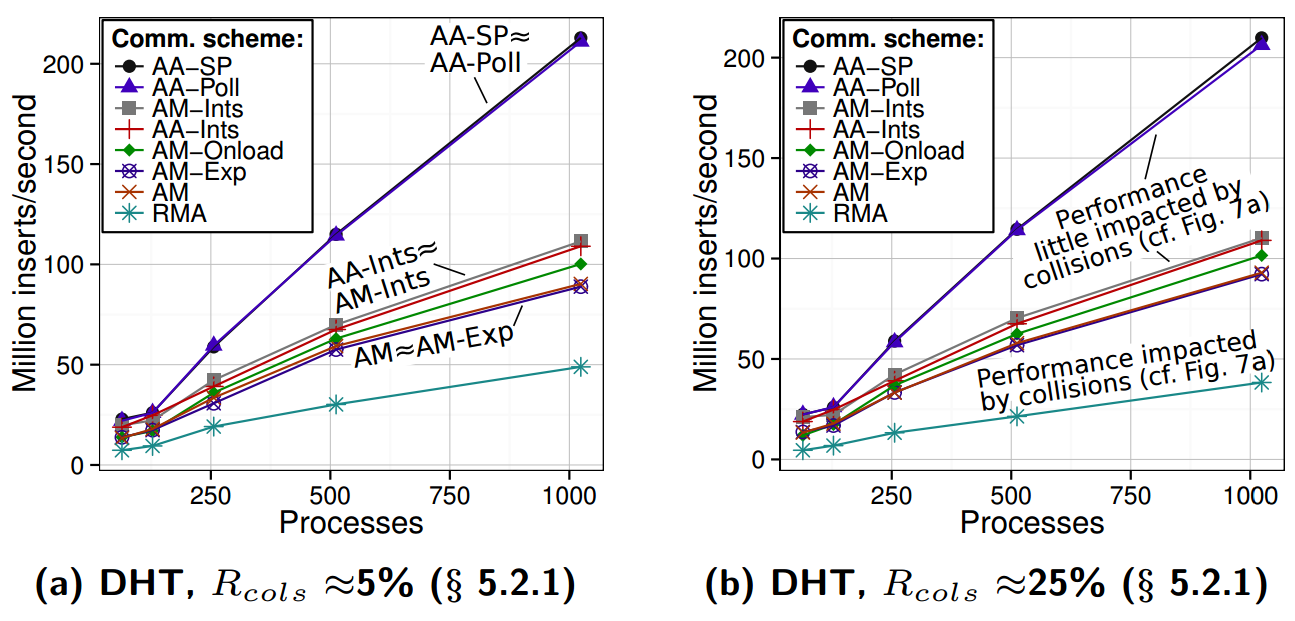
The performance of a distributed hashtable implemented using various variants of Active Access (AA-*), RMA, and various variants of Active Messages (AM-*). Percentages are ratios of hash collisions to all the inserts in a workload.
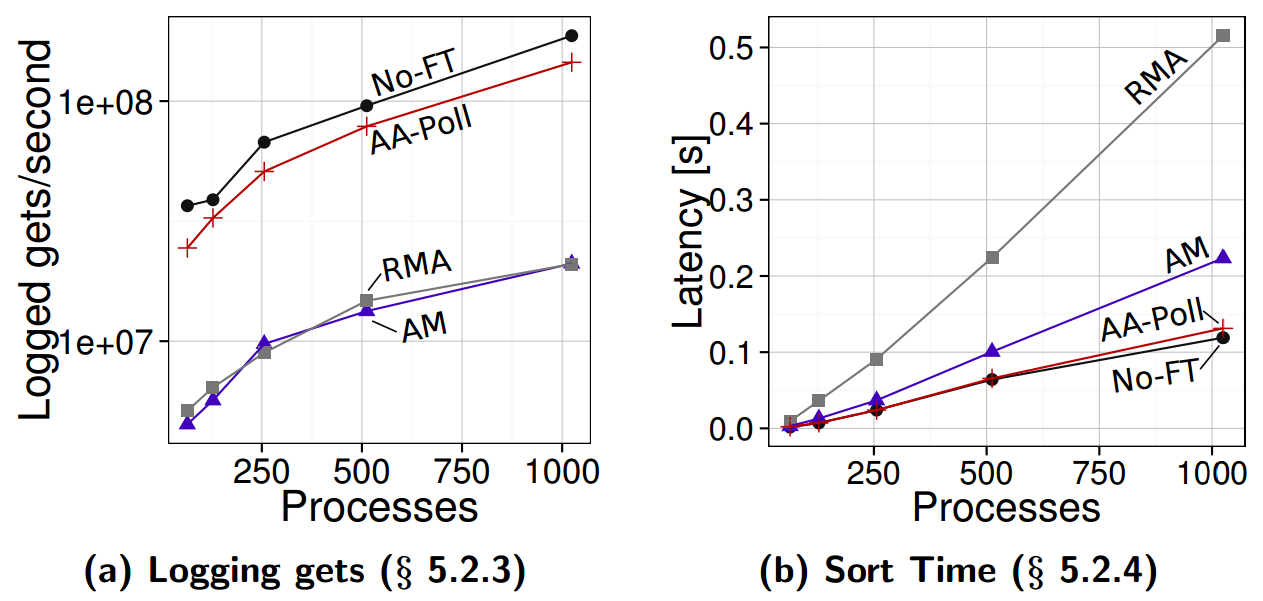
The performance of the logging of RMA gets in a novel fault-tolerance scheme for RMA (on the left) and the performance of fault-tolerant sorting (on the right) in a fault-free run. No-FT is a variant of a code with no fault tolerance and thus zero additional overhead. Our logging adds negligible overheads to the execution of RMA codes compared to variants based on Active Messages (AM) and RMA.
References
| [1] M. Besta, T. Hoefler: | ||
Active Access: A Mechanism for High-Performance Distributed Data-Centric Computations
In Proceedings of the 29th International Conference on Supercomputing (ICS'15), presented in Newport Beach, CA, USA, pages 155--164, ACM, ISBN: 978-1-4503-3559-1, Jun. 2015, (acceptance rate: 25% (40/160)) 


| ||