|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










Fault tolerance for Remote Memory Access (RMA) programming
The key idea in a single sentence
The concept of epochs can be used to make Remote Memory Access (RMA) and Partitioned Global Address Space (PGAS) codes fault-tolerant using logging and coordinated/uncoordinated checkpointing.
Key motivation
RMA and PGAS are becoming an important mechanism and abstraction used to develop HPC and data-center codes that fully utilize the capabilities of the underlying networking hardware. Yet, even if there is a plethora of fault tolerance schemes (logging and checkpointing) for Message Passing, there are virtually no protocols, analyses, and models for the fault tolerance for RMA and PGAS. We perform the first such work that targets hierarchical data centers and HPC machines. We assume limited amounts of memory per core and only consider volatile storage.
Summary of work
Our work consists of three parts.
- Designing a fault-tolerance model for RMA/PGAS codes: We design a model that enables formal reasoning about fault tolerance for RMA/PGAS; its core concept is an epoch of accesses: a period between two memory synchronization actions. The model supports today's hierarchical machines and cover multiple parallel crashes of various HW elements.
- Developing fault-tolerance protocols for RMA/PGAS: Based on the model, we illustrate protocols for coordinated checkpointing, logging of RMA accesses, uncoordinated checkpointing, and causal recovery of crashed processes. The protocols take into account the limited amounts of memories per core.
- Illustrating negligible performance overheads: We show that the proposed schemes add little overheads to fault-free runs.
- Packaging protocols in a fault-tolerance library: the designed protocols
are implemented in a library that requires minimal modifications to the application code.
Key findings and discoveries
- RMA can be made fault-tolerant: Our work illustrates that RMA (and PGAS) codes can be made fault tolerant with mechanisms similar to those associated with Message Passing.
- The concept of epochs can be used to develop various fault-tolerance schemes for RMA: An epoch (at a given process X that accesses the memory of a process Y) is a period between two memory synchronization calls issued by X and targeted at Y. We illustrate that epochs can be the basis of a fault-tolerance model and protocols, enabling formal reasoning about fault-tolerance for RMA.
- Coordinated checkpointing is easier in RMA than in Message Passing: In coordinated checkpointing for Message Passing, one must ensure that there are no messages in flight while a checkpoint is taken. This may be non-trivial. In RMA, this task is much simpler because all the involved communicating processes can flush the communication channels to ensure that all the memory accesses have been finished before the checkpoint.
- Uncoordinated checkpointing and logging is more difficult in RMA than in Message Passing: In RMA, two types of memory accesses are used: puts and gets. Assume a process X accesses the memory of a different process Y. A put transfers some local data from X to the remote memory of Y; a get fetches some remote data from Y's memory to the local X's memory. Assuming volatile memories used for logging, puts and gets should be treated differently by the fault-tolerance protocol. A put can be logged in the memory of the issuing process X. If Y crashes, it will be able to fetch and use the log of this put while recovering to the state before the crash. Contrarily, a get must not be logged in the memory of the issuing process X. This is because, if X crashes, X (and not Y) will have to use this log for the recovery to the state before the crash. Thus, if X were to log this get in its local memory, the log would be lost (the memory is assumed volatile), causing inconsistent recovery.
An example scheme: coordinated checkpointing in RMA
Coordinated checkpointing in Message Passing is challenging because messages in flight must be detected: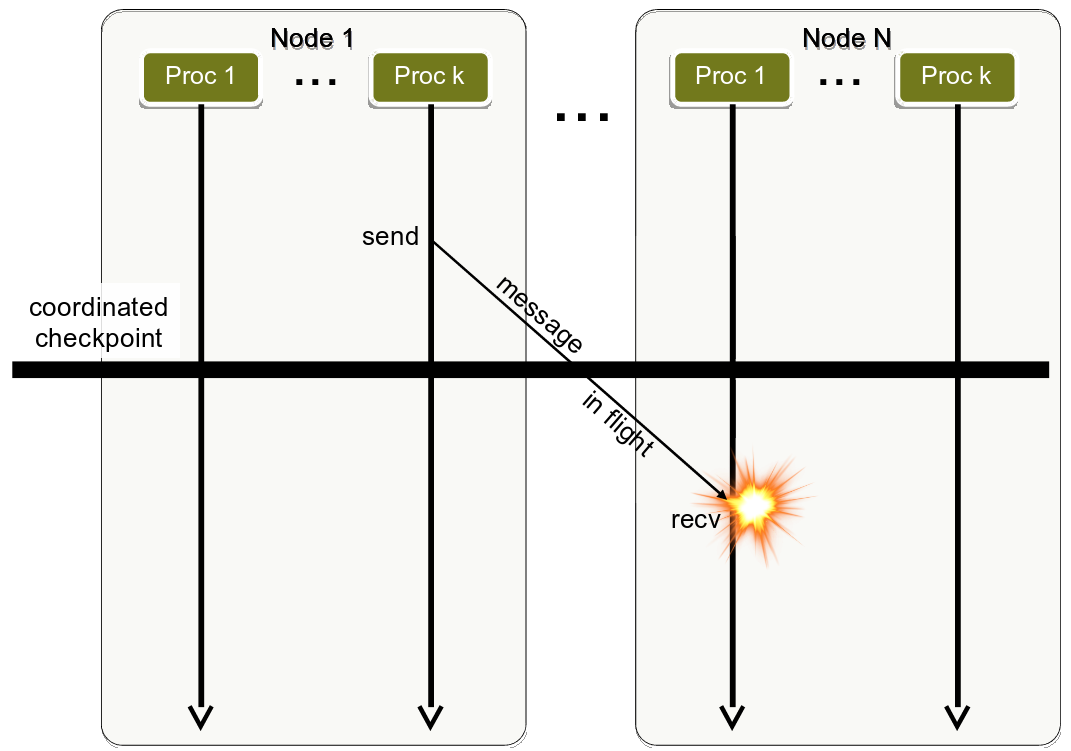
Coordinated checkpointing in Message Passing. The explosion indicates an inconsistent checkpoint taken because of the message in flight.
Coordinated checkpointing in RMA is easier because communication channels can be flushed and the pending memory accesses (e.g., the put below) can be guaranteed complete before the checkpoint:
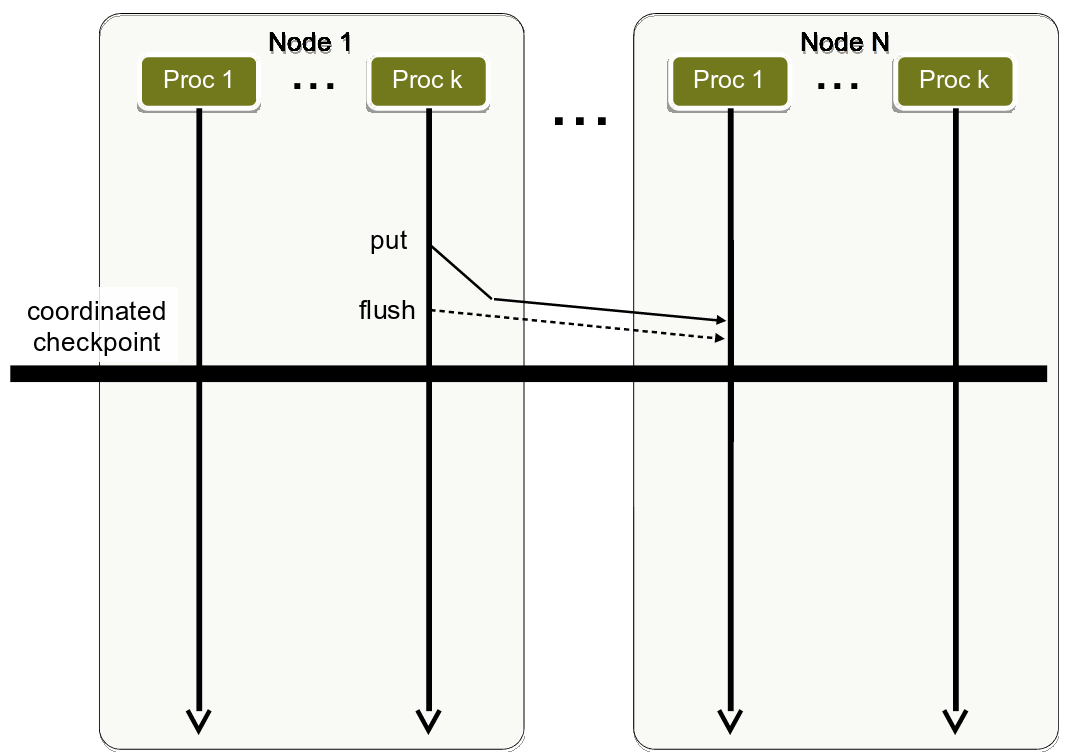
Coordinated checkpointing in RMA. The illustrated flush ensures the completion of a pending put, ensuring a consistent checkpoint.
Covering hierarchical hardware
Our model and protocols use the knowledge of the hierarchy of the underlying machine to increase the level of fault-tolerance. An example hardware hierarchy: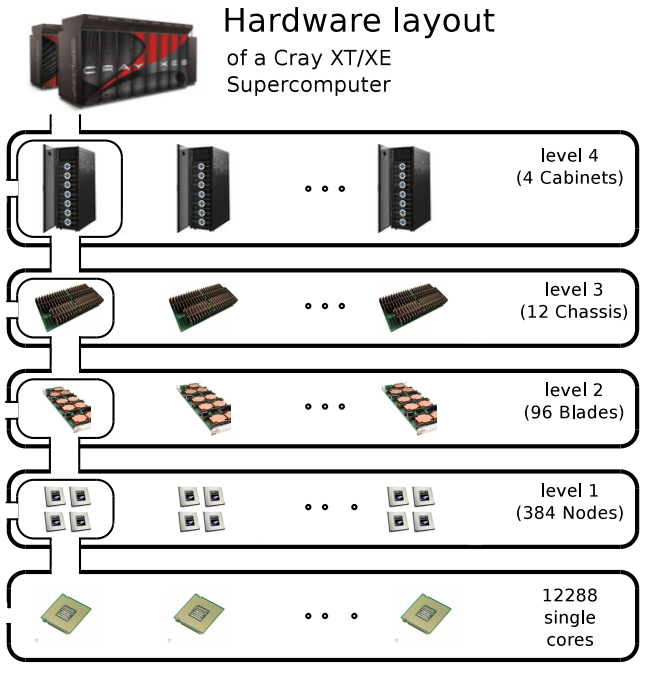
A hardware hierarchy of a Cray supercomputer.
Selected interesting analyses
Here, we present several performance analyses.
Our coordinated checkpointing adds negligible overheads to the execution of RMA codes:
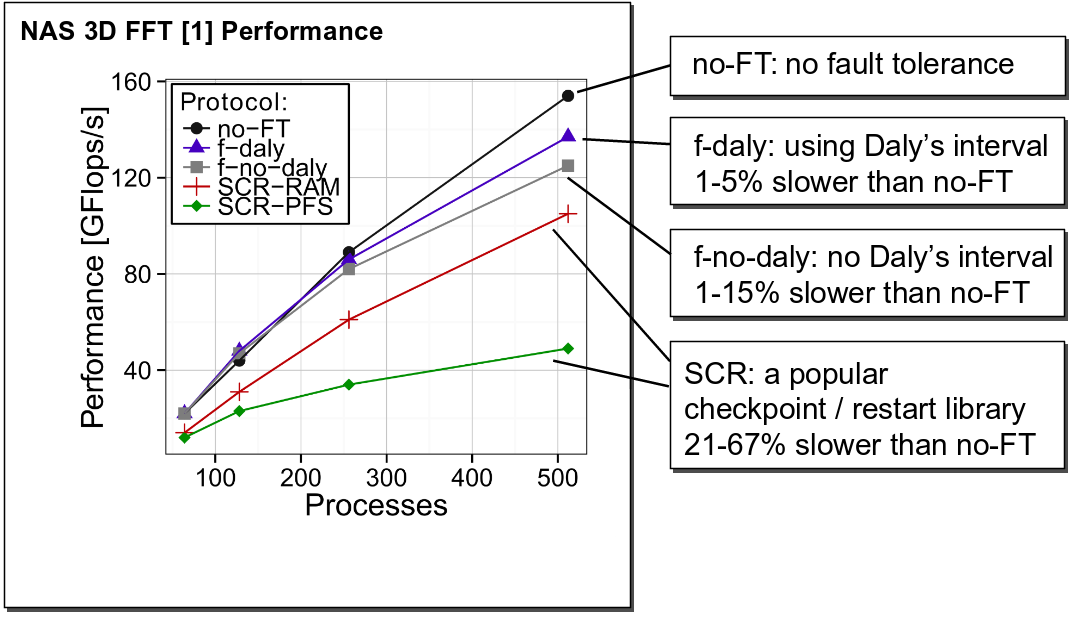
Evaluation of different variants of the 3D FFT code (fault-free runs) when coordinated checkpointing is enabled.
Our logging adds negligible overheads to the execution of RMA codes:
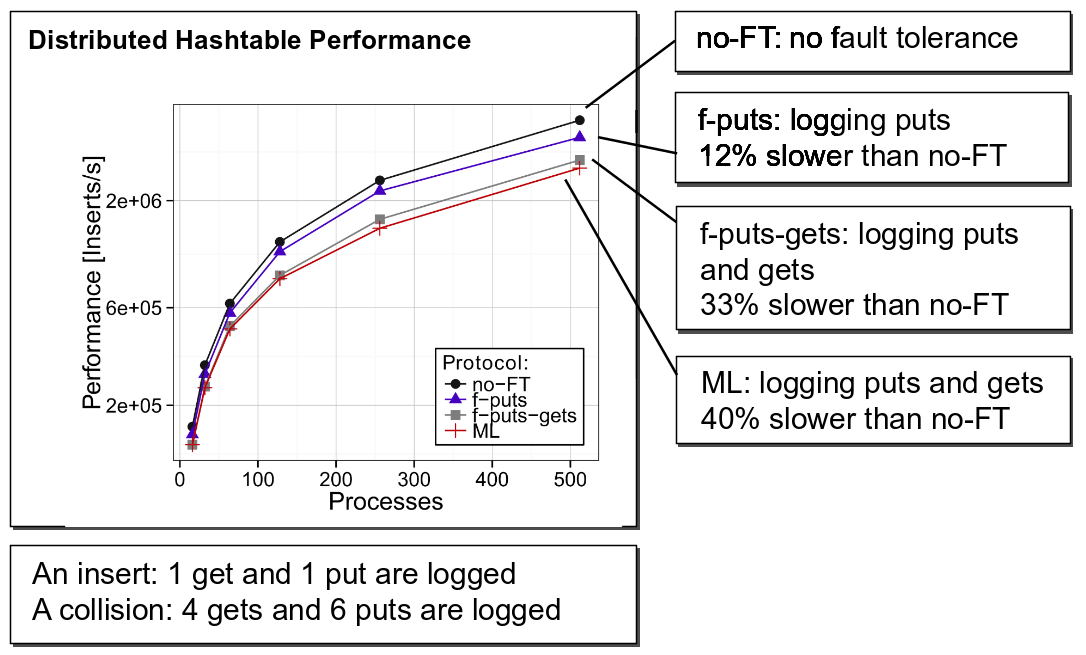
Evaluation of different variants of a distributed hashtable code (fault-free runs) when logging of puts/gets is enabled.
Our protocols enable specifying the maximum amount of memory dedicated to fault-tolerance:
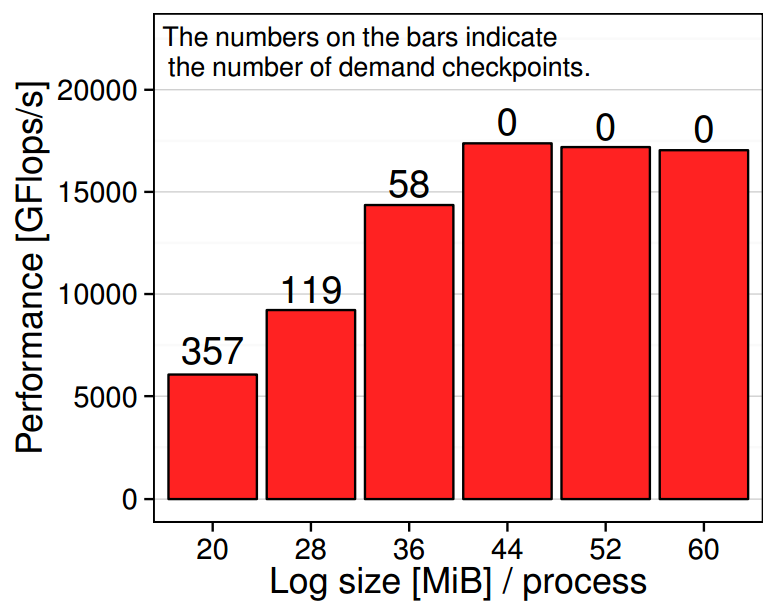
Evaluation of different variants of the 3D FFT code (fault-free runs) with uncoordinated checkpointing enabled; different bars indicate different amounts of storage dedicated to logging. A "demand checkpoint" is a checkpoint taken on demand when it is required to clear a part of the log.
Download: the code and the technical report
The code includes the library and performance experiments.
| Version | Date | Changes |
| ftrma.tar.gz | August, 2014 | First release |
The accompanying technical report is here: TR.
The above code uses extensively the foMPI RMA communication library. In case of
any compilation problems, you can also consult the code here:
foMPI.
References
| [1] M. Besta, T. Hoefler: | ||
Fault Tolerance for Remote Memory Access Programming Models
In Proceedings of the 23rd ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC'14), presented in Vancouver, Canada, ACM, Jun. 2014, (acceptance rate: 16%, 21/130) Best Paper Nominee at HPDC'14 (3/21) 


| ||