|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










What is the true cost/performance of atomic operations?
The key aspect in a single sentence
We model, measure, and understand the performance of various atomic operations such as Compare-and-Swap, Fetch-and-Add, or Swap on miscellaneous modern architectures to facilitate the development of fast parallel codes.
Key motivation
Atomic operations (atomics) such as Compare-and-Swap (CAS), Fetch-and-Add (FAA), and Swap (SWP) are ubiquitous in parallel programming. Yet, performance tradeoffs between these operations and various characteristics of parallel systems, such as the structure of caches, are unclear and have not been thoroughly analyzed. Such an analysis would enable better design and algorithmic decisions in parallel programming on various architectures deployed in both off-the-shelf machines and large compute systems.
Summary of work
We establish an evaluation methodology, develop a performance model, and present a set of detailed benchmarks for latency and bandwidth of different atomics. We also discuss solutions to the discovered performance issues in the analyzed architectures. Finally, we briefly illustrate how our analysis simplifies developing parallel codes.
In benchmarks, we consider the following parameters and aspects:
- State-of-the-art x86 architectures: Intel Haswell (represents commodity servers), Xeon Phi (represents accelerators), Ivy Bridge (represents clusters), and AMD Bulldozer (represents HPC supercomputers).
- Location: L1 cache, L2 cache, L3 cache, local memory banks, remote memory banks (NUMA).
- Cache coherence state: Exclusive, Modified, Shared, Owned, Invalid, MuW (a proprietary AMD state).
- Atomics: Compare-and-Swap (CAS), Fetch-and-Add (FAA), Swap (SWP).
- Contention: various counts of accessing threads.
- Operand size: 64 bits and 128 bits.
- Benchmark type: latency, bandwidth.
- Number of operands fetched: either 1 or 2; this only applies to CAS only.
- Impact from prefetchers and power efficiency mechanisms: Hardware Prefetcher enabled, Adjacent Cache Line Prefetcher enabled, both the prefetchers enabled, Turbo Boost, EIST, C States enabled.
- Alignment: aligned vs unaligned operations.
Key findings and discoveries
The results unveil surprising performance relationships between the considered atomics and architectural properties such as the coherence state of the accessed cache lines.
- All the tested atomics have usually comparable latency and bandwidth. Specifically, contrary to the common view [22] (in PACT'15), the latency of CAS, FAA, and SWP is in most cases identical. Sometimes, CAS is even faster than FAA (e.g., when accessing L1 on Haswell and L3/memory on AMD). We discuss how to use it for more performance in graph processing (see below for details).
- ILP with atomics: The design of atomics prevents any instruction-level parallelism even if there are no dependencies between the issued operations (in the paper, we discuss ways to alleviate it in future architectures).
- Modeling the performance of atomics: A simple performance model that takes into account the cache coherence state of the accessed cache line is enough to account for most performance results of atomics.
- Multiple other insights for specific architectures: check the paper.
Performance model
In our work, we illustrate that a simple performance model that takes into
account the cache coherence state of the accessed cache line is enough to
account for most performance results.
Each atomic fetches and modifies a given cache line (“read-modify-write”). We
predict that an atomic first issues a read for ownership in order to fetch the
respective cache line and invalidate the cache line copies in other caches.
Then the operation is executed and the result is written in a modified state to
the local L1 cache. We thus model the latency L of an atomic operation A
executing with an operand from a cache line in a coherency state S as:
L(A,S) = R(S) + E(A) + O
A denotes the analyzed atomic; (CAS, FAA, SWP). S denotes the coherency state;
(E, M, S, O). R(S) is the latency of the read for ownership (reading a cache
line in a coherency state S and invalidating other caches). E(A) is the latency
of: locking a cache line, executing A by the CPU, and writing the operation
result into a cache line in the coherency state M. As all other copies of the
cache line are invalidated, this will be a write into L1 local to the core
executing the instruction. Finally, O denotes additional overheads related to
various proprietary optimizations of the coherence protocols that we describe
in Section V of the paper.
Selected interesting analyses
The latency of all the considered atomics is identical (Haswell):
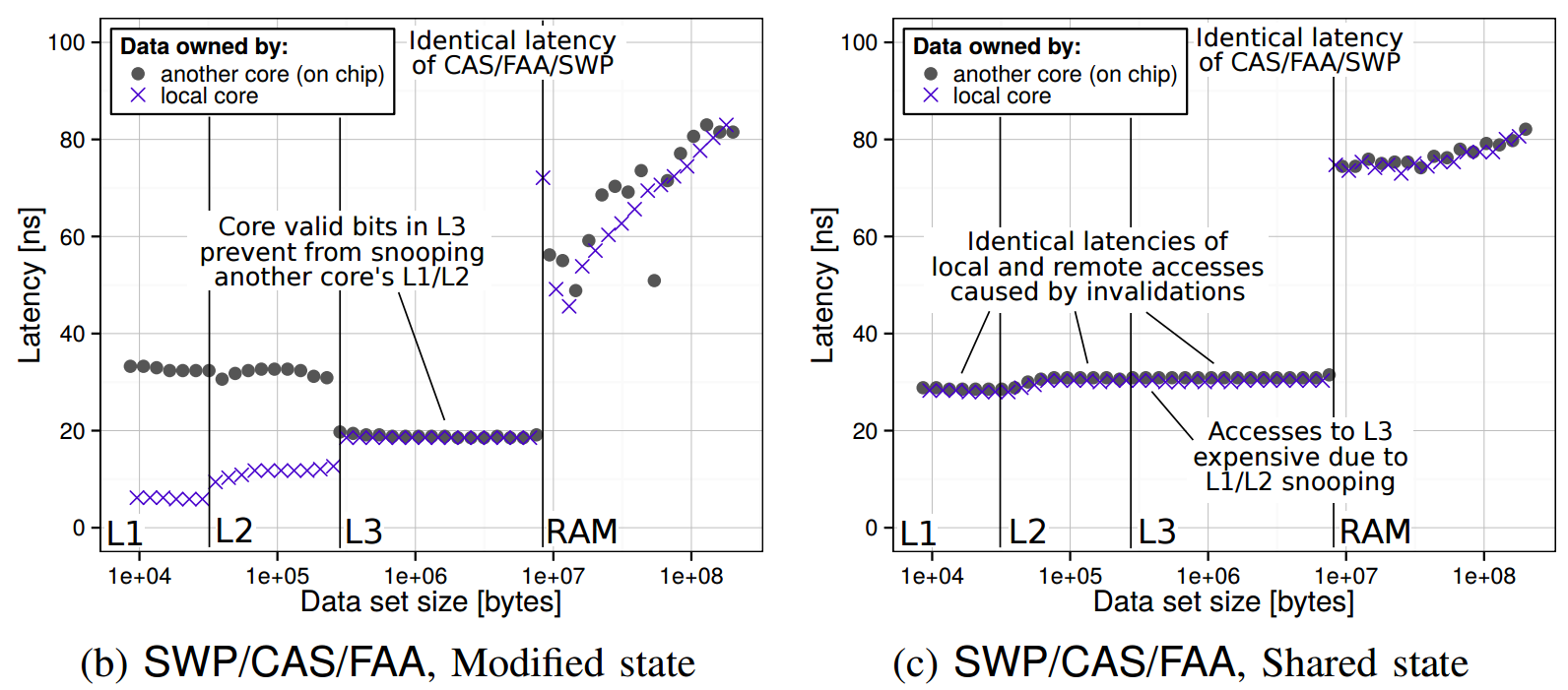
The comparison of the latency of CAS, FAA, and SWP on Haswell. The requesting core accesses its own cache lines (local) and cache lines of a different core from the same chip (on chip). Two states are illustrated: Modified (M) and Shared (S).
CAS can be faster than FAA (AMD Bulldozer):
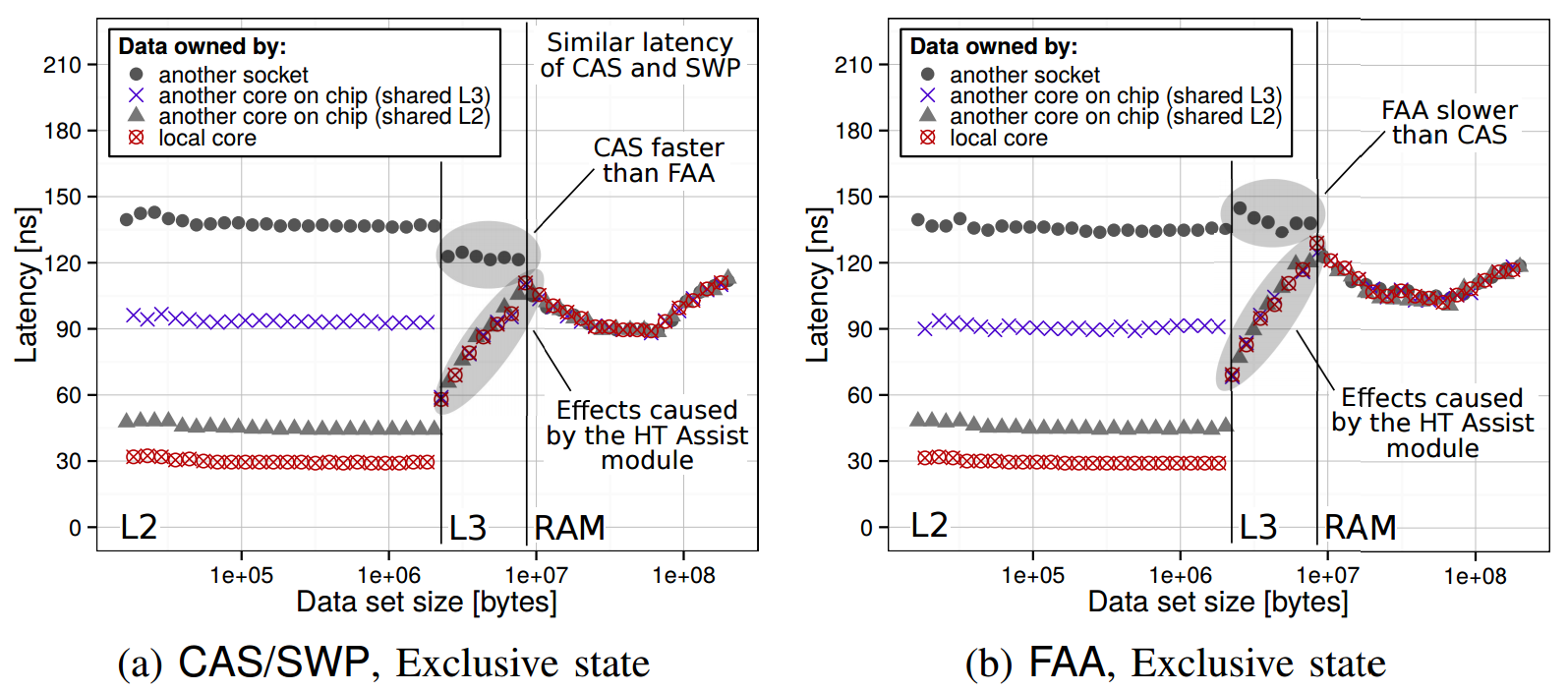
The latency comparison of CAS/FAA/SWP/read on AMD Bulldozer. The requesting core accesses its own cache lines (local), cache lines of different cores that share L2 and L3 with the requesting core (on chip, shared L2 and L3, respectively), and cache lines of a core from a different socket (other socket).
The bandwidth of CAS is higher than that of FAA (Haswell):
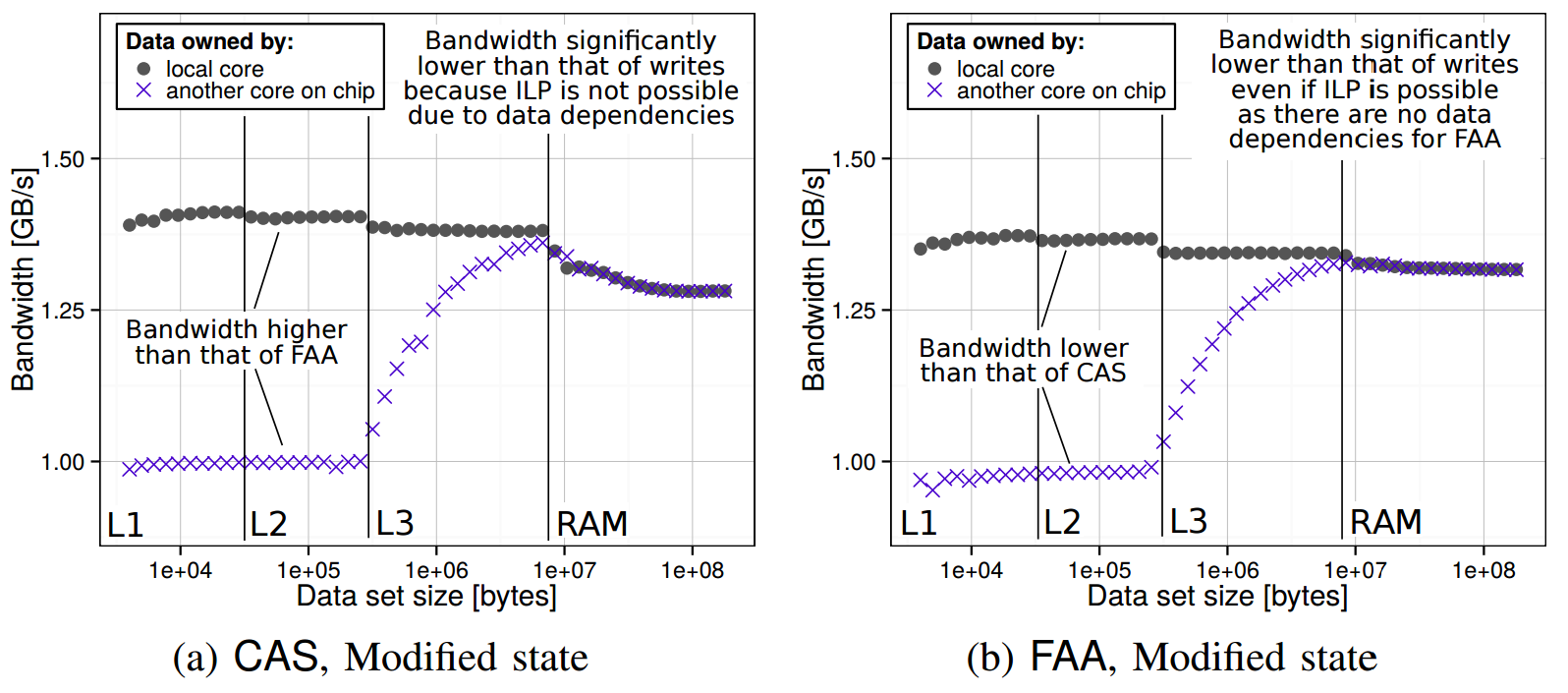
The comparison of the bandwidth of FAA (lower than that of CAS), and writes on Haswell. The requesting core accesses its own cache lines (local) and cache lines of a different core from the same chip (on chip).
Atomics have significantly lower bandwidth than that of writes (Haswell):
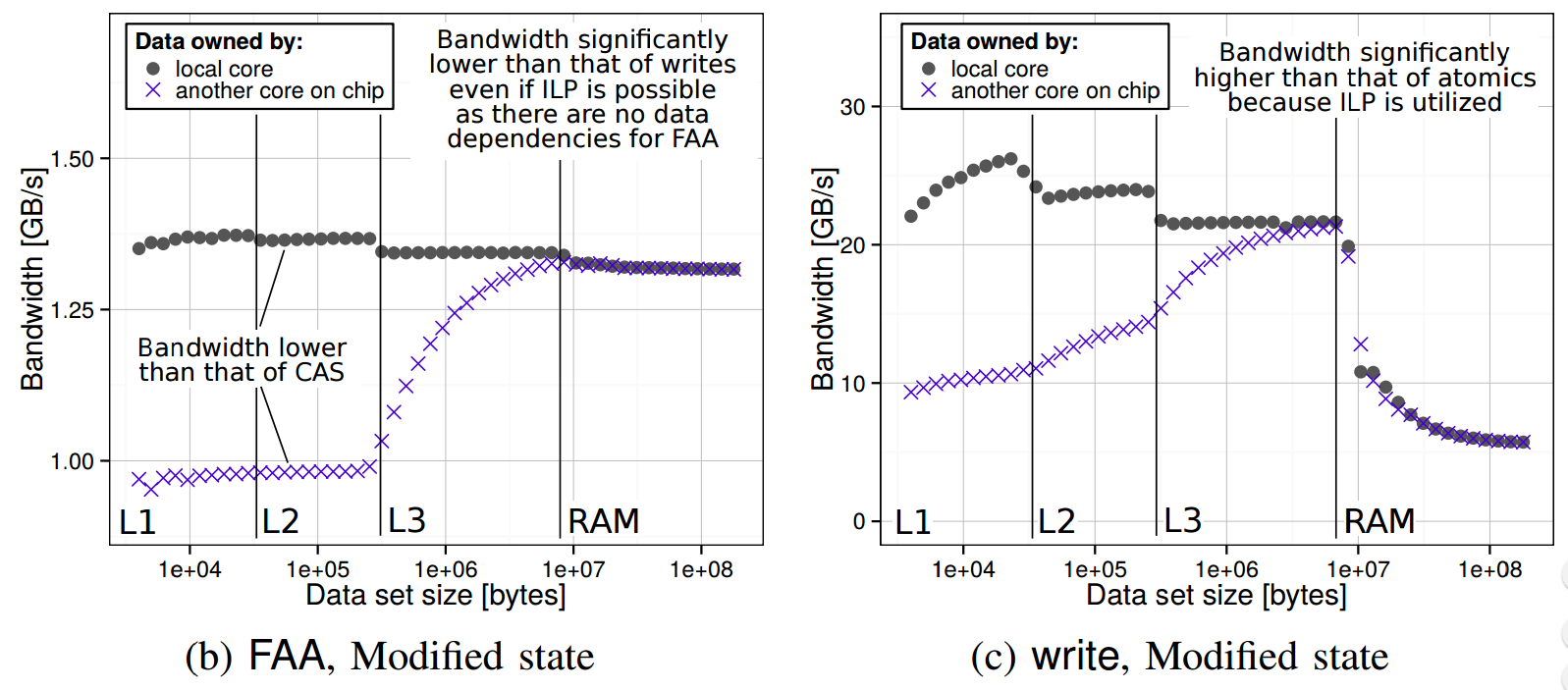
The comparison of the bandwidth of FAA (lower than that of CAS), and writes on Haswell. The requesting core accesses its own cache lines (local) and cache lines of a different core from the same chip (on chip).
The operand size does matter for the latency (AMD Bulldozer):
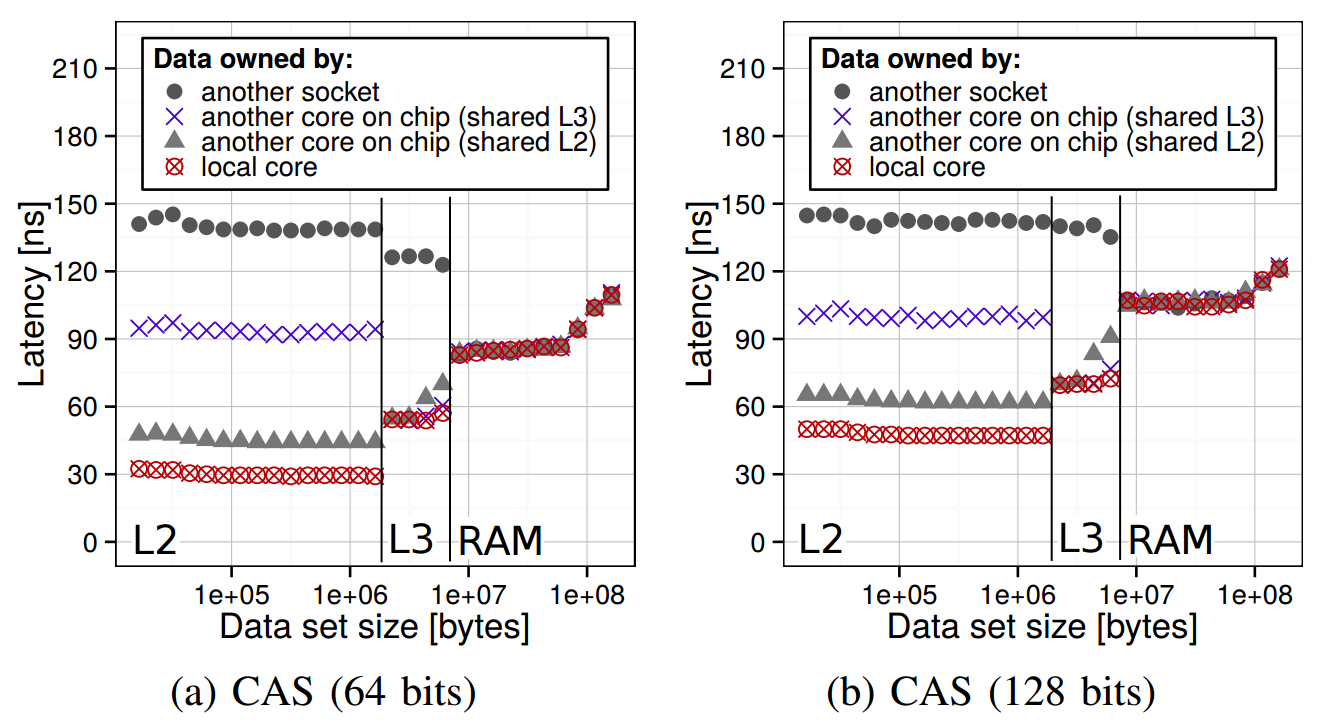
The comparison of the latency of CAS using operands of 64 and 128 bits in size (AMD Bulldozer, the M state).
Different contention results on various architectures:
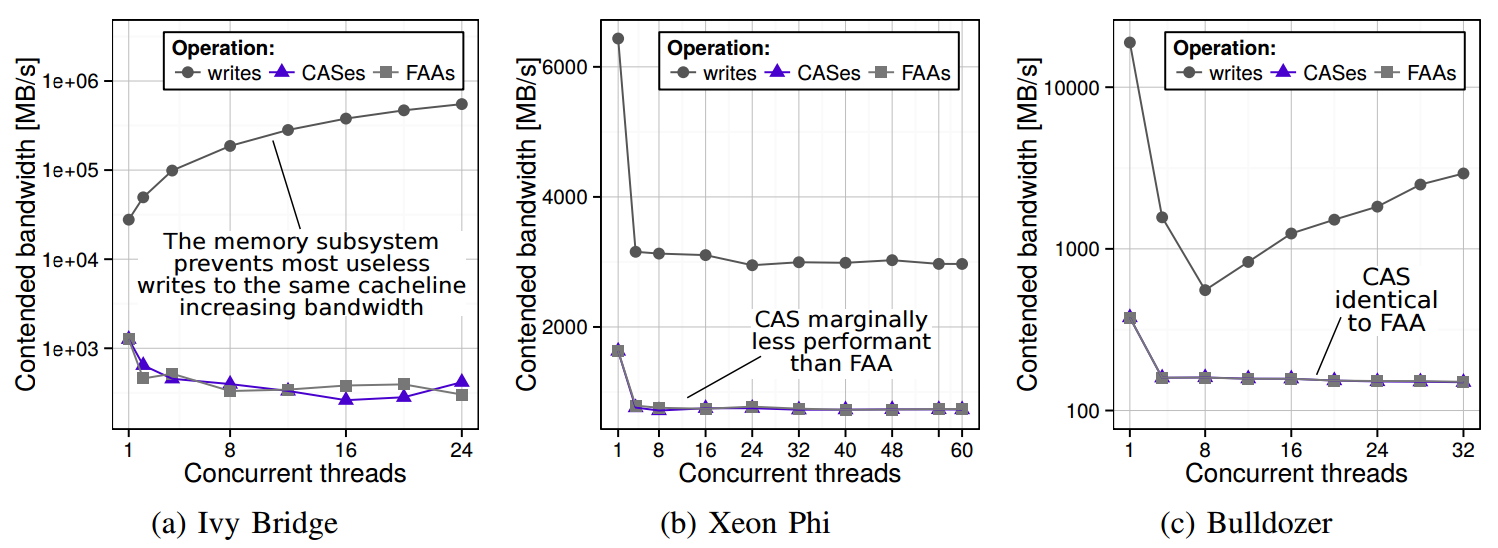
The comparison of the contended bandwidth of CAS/FAA/writes on Ivy Bridge, Bulldozer, and Xeon Phi.
Unaligned CAS is >10x slower than the aligned variant:
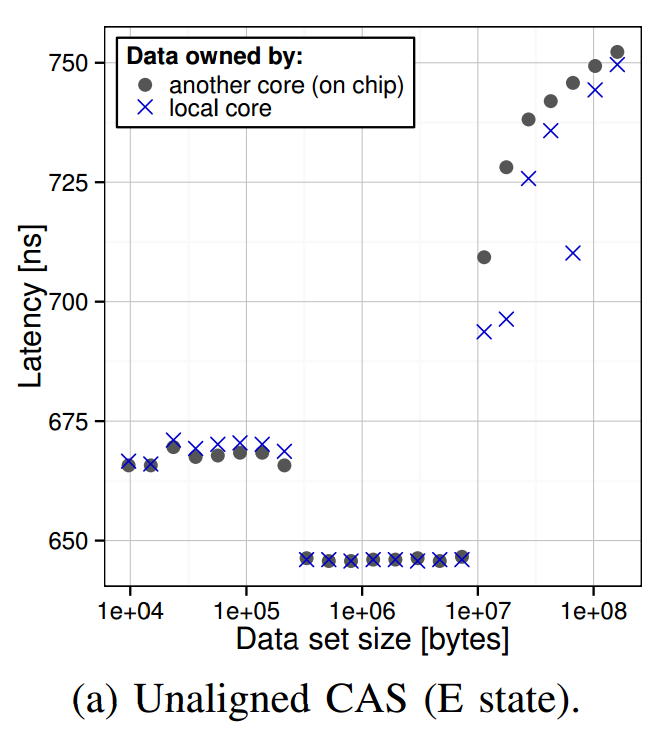
The analysis of unaligned atomics.
Simplifying parallel programming
Our analysis can be used to simplify the development of parallel codes. For example, the provided results indicate that the performance overheads from CAS are not caused by different latency/bandwidth, but are only due to the different semantics: CAS may succeed but may also fail, while FAA and SWP always succeed. We use this insight while developing a breadth-first search (BFS) graph traversal. BFS can be developed with either CAS or SWP. Our above performance analysis indicates they have almost identical latency. Thus, as CAS introduces the wasted work, SWP is the preferred operation to be used. We evaluate both variants; the results are plotted in the figure below. The variant based on SWP indeed results in more edges traversed per second.
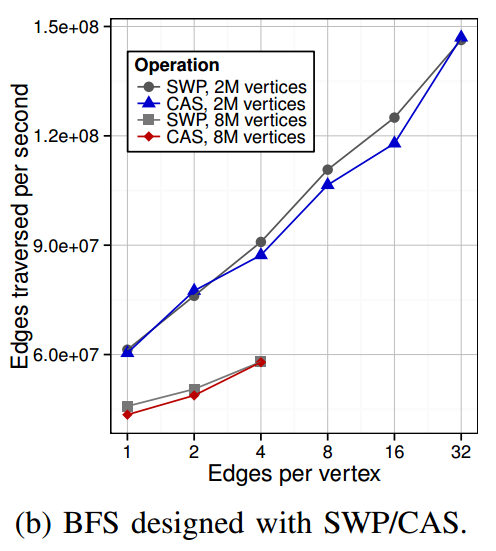
BFS designed with SWP and CAS (Haswell, 4 parallel threads). A traversal is performed on Kronecker graphs [16] (in PACT'15) that model heavy-tailed real-world graphs. The largest graphs fill the whole available memory. The results illustrate that SWP results in more edges traversed per second.
Download and Code Usage
| Version | Date | Changes |
| release-atomics.tar.gz | May 4th, 2016 | First release |
The accompanying technical report: TR
This is an extended version of the code by Molka et al. that can be found here:
X86membench
and here:
BenchIT.
The details on how to use and compile the code can be found under the two above websites.
The code of the benchmarks of the atomics is under the following paths:
BenchITv6/kernel/arch_x86_64/memory_latency/C/pthread/0
BenchITv6/kernel/arch_x86_64/memory_bandwidth/C/pthread
Please consult the README-Atomics file in the archive for the information on
using the code with atomics. The README file contains the general information
on how to compile the code.
References
| [1] H. Schweizer, M. Besta, T. Hoefler: | ||
Evaluating the Cost of Atomic Operations on Modern Architectures
presented in San Francisco, CA, USA, ACM, Oct. 2015, Accepted at the 24th International Conference on Parallel Architectures and Compilation (PACT'15) (acceptance rate: 21%, 38/179) 


| ||