|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










foMPI-NA: enabling Notified Access semantics in MPI
Motivation
Modern interconnects offer Remote Direct Memory Access (RDMA) features. These features reflect the characteristics of RMA programming models in which remote read/write operations and synchronization primitives are defined. RDMA has also been used to implement fast message passing systems. However, both RMA and Message Passing require at least an additional round-trip message between two processes to synchronize. This additional synchronization overhead may drastically reduce the performance of applications where synchronization is needed after the transmission of each message. For instance, this per-message synchronization is used in the well-known producer-consumer class of problems.
Communication Schemes:
The Message Passing programming model mainly provides two calls for exchanging data between processes: the Send and Recv. These two calls ensure both data transfer and synchronization. In current RDMA-based implementations of Message Passing libraries two classes of protocols are mainly used: the Eager and the Rendezvous. The first one is used to provide a very low latency on small transfers. In this case, as soon as the producer invokes the send, the message is directly transferred to a mailbox (a pre-allocated intermediate buffer) at the receiver side. This method can be used only if the message fits the mailbox, it provides low latencies but the use of these pre-allocated buffer is considered not scalable. The second protocol used in Message Passing libraries is the Rendezvous protocol. In this case a longer synchronization phase is needed but the protocol enables zero-copy transfers.
alternately, RMA does not provide data transfer and synchronization within the same primitive. These two phases require the invocation of different primitives. The following figures depict the typical interaction pattern using both communication schemes.
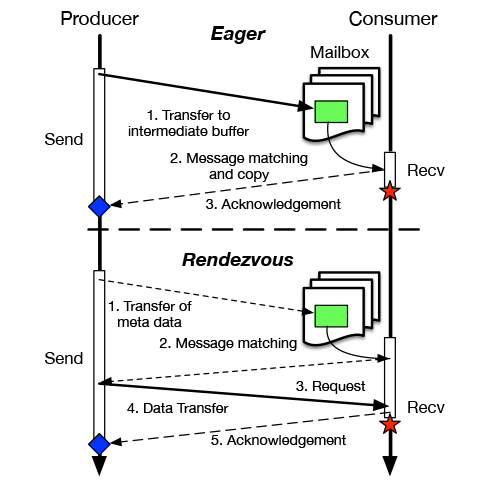
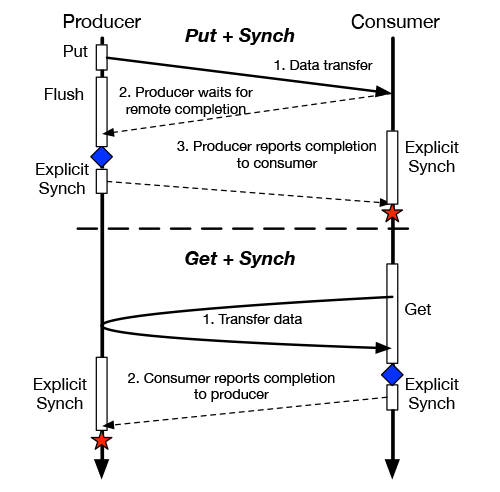
Producer/consumer interactions using Message Passing and RMA.
We propose Notified Access, a new communication scheme that aims to optimize synchronization latencies, especially on fine or medium grain transfers, combining in RMA data transfer and synchronization. Notified Access is a new programming model in which the target of an RMA transfer may be notified (if needed) of remotely instantiated RMA transfers.
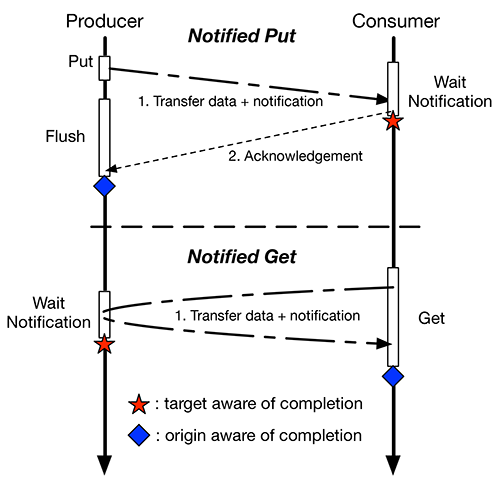
Producer/consumer interactions using Notified Access.
This approach leverages the RDMA characteristics and allows to access all the available performance in state-of-the-art interconnects ensuring the following benefits:
- It minimizes the number of messages needed by the synchronization phase, improving inter-node synchronization latencies and reducing the number of messages that cross the network.
- It enables zero-copy transfers saving energy and reducing cache pollution problems due to unnecessary data movements.
- It provides an increased asynchronous progression of processes and an augmented computation/communication overlap.
- It enables data-flow settings at the cost of a lightweigth notification-matching mechanism.
In order to demonstrate these proprieties we designed and implemented an extension of the MPI-3.0 interface that enables the Notified Access semantics.
Interface
To extend MPI with Notified Access, we introduce a notified variant for each communication operation in MPI RMA. Each variant requires an additional integer value named "tag". This tag value can be retrieved at the target side of an RMA operation querying the notification system.
Communication primitives:
int MPI_Put_notify(void *origin_addr, int origin_count, MPI_Datatype origin_type, int target_rank, MPI_Aint target_disp, int target_count, MPI_Datatype target_type, MPI_Win win, int tag); int MPI_Get_notify(void *origin_addr, int origin_count, MPI_Datatype origin_type, int target_rank, MPI_Aint target_disp, int target_count, MPI_Datatype target_type, MPI_Win win, int tag);
In our interface, the non blocking version of these two calls (MPI_Rget_notify and MPI_Rput_notify) are defined as well. Similar functions can be added to the interface for MPI's Accumulate operations (accumulate, get_accumulate, fetch and op and compare and swap).
In order to enable the target side of an RMA operation to retrieve notifications, we designed MPI_Notify_init. This function requires three notification-matching parameters representing:
- src_rank: the rank of the origin process that will generate the expected notification
- tag: the tag specified by the origin for a specific RMA operation
- expected_count: the expected number of notifications matching src_rank and tag
Wildcards (MPI_ANY_SOURCE, MPI_ANY_TAG) can be used as src_rank and/or tag respectively. The function MPI_Notify_init generates a MPI_Request handle that can be tested multiple times using MPI_Wait or MPI_Test.
Synchronization primitives:
int MPI_Notify_init(MPI_Win win, int src_rank, int tag, int expected_count, MPI_Request *request); int MPI_Start(MPI_Request *request); int MPI_Wait(MPI_Request *request, MPI_Status *status);
The request objects initialized by MPI_Notify_init are Persistent Request objects [Sec. 3.9 MPI-3.0] in order to reduce the overhead of the notification system. Before testing such requests, they have to be enabled using MPI_Start. A single request, if initialized multiple times, can be tested multiple times. However this kind of requests is not automatically freed, when a persistent request is no more needed MPI_Request_free has to be invoked by the user.
Implementation
We introduce foMPI-NA (fast one-sided MPI - Notified Access) a fully-functional MPI-3.0 implementation that enables the Notified Access semantics. Our implementation bases on foMPI an open-source MPI library that targets Cray Gemini (XK5, XE6) and Aries (XC30) systems.
The foMPI-NA implementation utilizes the uGNI API that provides direct access to the Cray's Fast Memory Access (FMA) and Block Transfer Engine (BTE) mechanisms. With both mechanisms is possible to directly notify the completion of an RDMA operation to the target process thanks to the use of uGNI completion queues. The uGNI API allows to attach a 4-byte integer to each remote access that is returned in the completion queue at the destination. Our implementation utilizes 2 Bytes for transmitting the tag and 2 bytes for the origin rank.
Performance Evaluation
The performance reached by foMPI-NA was compared with the performances obtained using MPI Message Passing and MPI-RMA in multiple michrobenchmarks:
- Ping-pong latency using inter-node remote writes
- Ping-pong latency using intra-node remote writes
- Ping-pong latency using inter-node remote reads
- Computation/communication overlap
- Pipeline stencil
- Tree computation
- Cholesky factorization
Microbenchmarks:
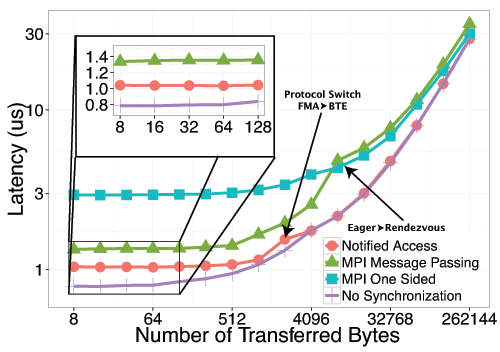
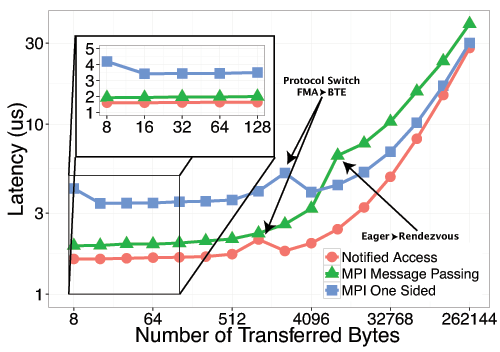
Ping-pong latency results for inter-node Put and Get
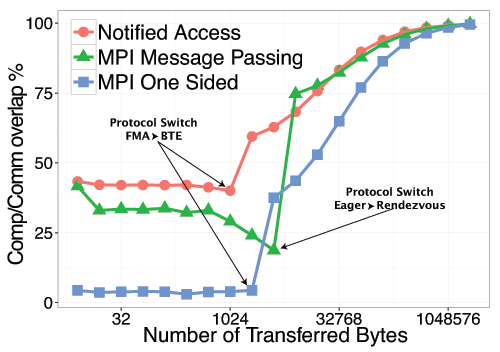
Single message overlap benchmark
These results demonstrates that Message Passing and RMA are not able to fully exploit all the performance available in modern NICs. foMPI-NA is able to reach lower communication latencies than the other two communication schemes. It worth notify that MPI Message Passing, the existing communication method that performs better in our target library, uses a communication progress thread and the low-latency eager protocol. foMPI-NA not only provides lower latencies, but it's also able to better overlap computation to communication, thanks to it's reduced synchronization latency.
Applications:
We implemented several use-cases of notified access: a pipelined stencil, a tree computation, and a parallel Cholesky factorization. Each of these use-cases demonstrates a different version of a producer-consumer problem where notified access can be used.
Our first motif application represents a pipelined stencil computation. For this, we use the Sync_p2p kernel from the Intel Parallel Research Kernels (PRK). We chose this benchmark because it is designed to test the efficiency of point-to-point synchronization.
The second analysed class of parallel applications are Hierarchical computations. We represent such computations by a tree-based communication which represent fan-in/fan-out as well as scatter/gather patterns. To represent these patterns, we implemented a 16-ary tree performing a reduction at each stage.
Finally we present a full Cholesky factorization example to demonstrate the utility of notified access in task data-flow settings.
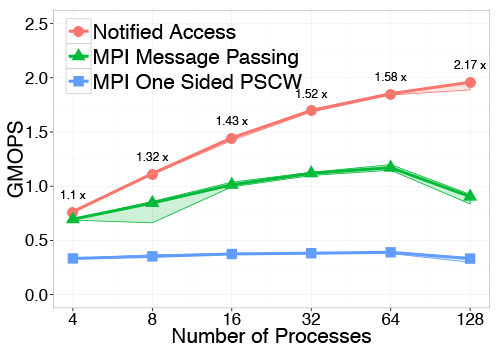
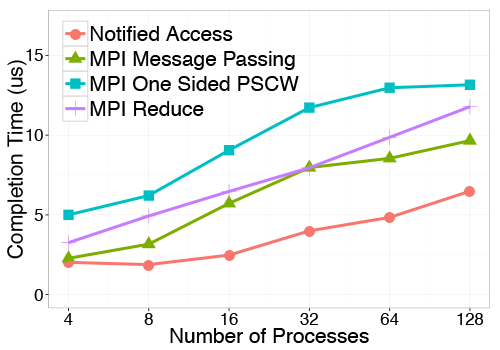
Performances compareison using different communication schemes in a pipeline stencil and in a 16-ary tree based reduce computation (8 bytes per node)
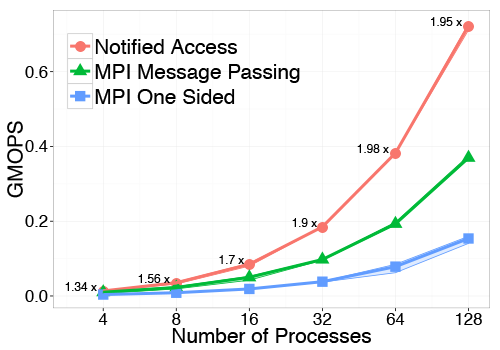
Performances compareison using different communication schemes in a Cholesky factorization
Results demonstrate that Message Passing and RMA are suboptimal when synchronization is needed after the transfer of each message. Notified Access, combining RMA with a lightweight notification mechanism, allows maximum utilization of RDMA hardware and enables efficient producer-consumer schemes. At the same time Notified Access provides also an increased asynchronous progression of processes. For all these reasons we expect that Notified Access will be an important primitive for exploiting future large scale networks towards exascale.
Download
The foMPI-NA download links can be found below. Please consult the README file in the archive for information on building and using foMPI-NA.
| Version | Date | Changes |
| foMPI-NA-0.2.2.tar.gz - (0.4 mb) | October 18, 2014 | First release |
| foMPI-NA-0.2.3.tar.gz - (1.2 mb) | July 6, 2017 | gcc5 compatibility, bug fixes |
| foMPI-NA-0.2.4.tar.gz - (1.2 mb) | April 30, 2018 | fixed a bug in foMPI_Test |
References
| [1] R. Belli, T. Hoefler: | ||
Notified Access: Extending Remote Memory Access Programming Models for Producer-Consumer Synchronization
In Proceedings of the 29th IEEE International Parallel & Distributed Processing Symposium (IPDPS'15), presented in Hyderabad, India, IEEE, May 2015, (acceptance rate: 21,8%, 108/496) Best Paper at IPDPS'15 (4/108) 

| ||