|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










dCUDA: Hardware Supported Overlap of Computation and Communication
Motivation
Today, we usually target GPU clusters using two different programming models. For example, we use MPI to move data between nodes and CUDA to implement the on-node computation. This approach has two main disadvantages: The application developers need to be familiar with both programming models, and the semantics of the programming models encourages the sequential execution of inter-node communication and on-node computation. Overall, the approach results in complex codes that may not fully utilize the costly hardware. Low resource utilization due to the sequential execution of memory accesses and compute operations poses a comparable challenge in processor design. Most processors employ latency minimization techniques such as caching and prefetching to speedup the execution of sequential codes. However, these techniques are not necessarily the best fit for the parallel workloads that commonly appear in GPU computing. Alternatively, we can overlap memory accesses and compute operations of parallel execution streams. This latency hiding technique enables high resource utilization for throughput oriented compute tasks. The CUDA programming model and the underlying hardware architecture implement automatic latency hiding. The application developer is only left with providing enough parallelism. With the dCUDA (distributed CUDA) programming model we apply latency hiding at cluster scale. To enable the automatic overlap of inter-node communication and on-node computation, dCUDA implements GPU-side remote memory access operations that execute concurrently with the compute operations performed by other threads.
Programming Model
dCUDA programs implement their application logic using a single CUDA kernel that performs explicit communication during kernel execution. To enable efficient latency hiding, every GPU has to run many parallel execution streams called ranks. We therefore map dCUDA ranks to CUDA blocks. To move data between the ranks, dCUDA implements a significant subset of the remote memory access capabilities of MPI. For example, dCUDA defines windows, GPU-side put and get operations, and notifications that enable target synchronization.
The following listing shows a stencil code implemented using dCUDA:
__shared__ dcuda_context ctx; dcuda_init(param, ctx); dcuda_comm_size(ctx, DCUDA_COMM_WORLD, &size); dcuda_comm_rank(ctx, DCUDA_COMM_WORLD, &rank); dcuda_win win, wout; dcuda_win_create(ctx, DCUDA_COMM_WORLD, &in[0], len + 2 * jstride, &win); dcuda_win_create(ctx, DCUDA_COMM_WORLD, &out[0], len + 2 * jstride, &wout); bool lsend = rank - 1 >= 0; bool rsend = rank + 1 < size; int from = threadIdx.x + jstride; int to = from + len; for (int i = 0; i < steps; ++i) { for (int idx = from; idx < to; idx += jstride) out[idx] = -4.0 * in[idx] + in[idx + 1] + in[idx - 1] + in[idx + jstride] + in[idx - jstride]; if (lsend) dcuda_put_notify(ctx, wout, rank - 1, len + jstride, jstride, &out[jstride], tag); if (rsend) dcuda_put_notify(ctx, wout, rank + 1, 0, jstride, &out[len], tag); dcuda_wait_notifications(ctx, wout, DCUDA_ANY_SOURCE, tag, lsend + rsend); swap(in, out); swap(win, wout); } dcuda_win_free(ctx, win); dcuda_win_free(ctx, wout); dcuda_finish(ctx);
The example program starts with the initialization of windows that define a global address space. Next, the time loop implements the stencil computation and the halo exchange communication. At the end of the time loop, the example program waits for the notifications that signal the arrival of the halo exchange data sent by the neighboring ranks. Note that the example program does not implement manual overlap of computation and communication, instead the compute and communication phases of different ranks running on the same GPU overlap automatically.
Implementation
We implement dCUDA using an MPI based runtime system that moves data directly from GPU to GPU using GPUrdma. We thereby use the host processor to control communication and to distribute incoming notifications among the ranks running on the attached GPU. We rely on memory mapped circular buffers to efficiently move control information between host processor and GPU.
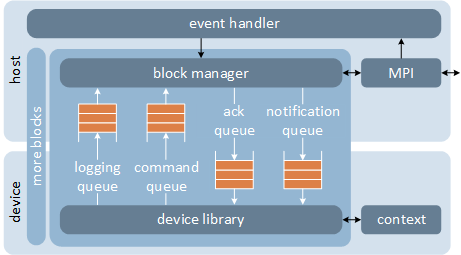
Architecture overview of the dCUDA runtime system
Evaluation
To evaluate dCUDA, we implement three example applications using both MPI-CUDA and dCUDA. Two out of three example applications significantly benefit from the automatic overlap of computation and communication provided by dCUDA.
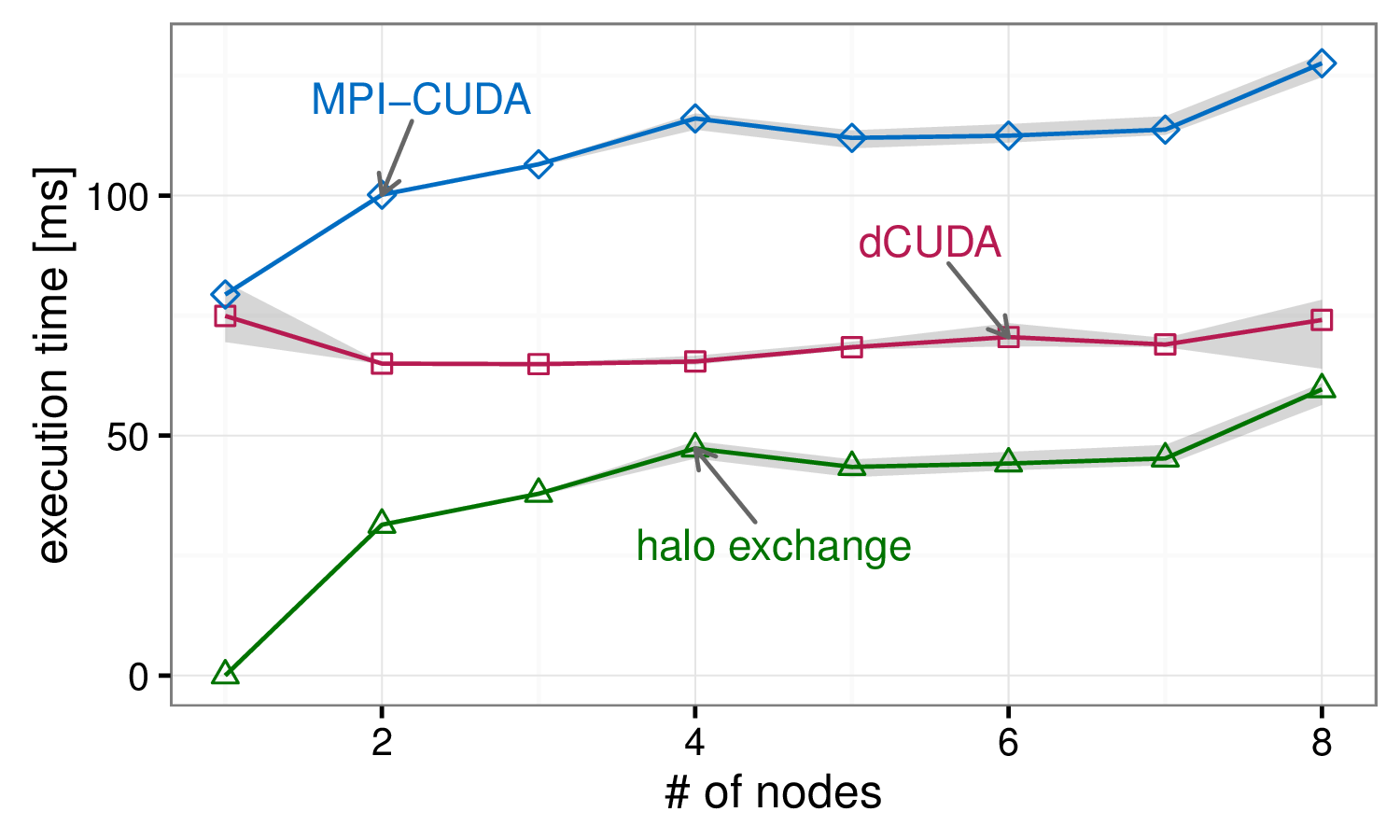
Weak scaling of the stencil application
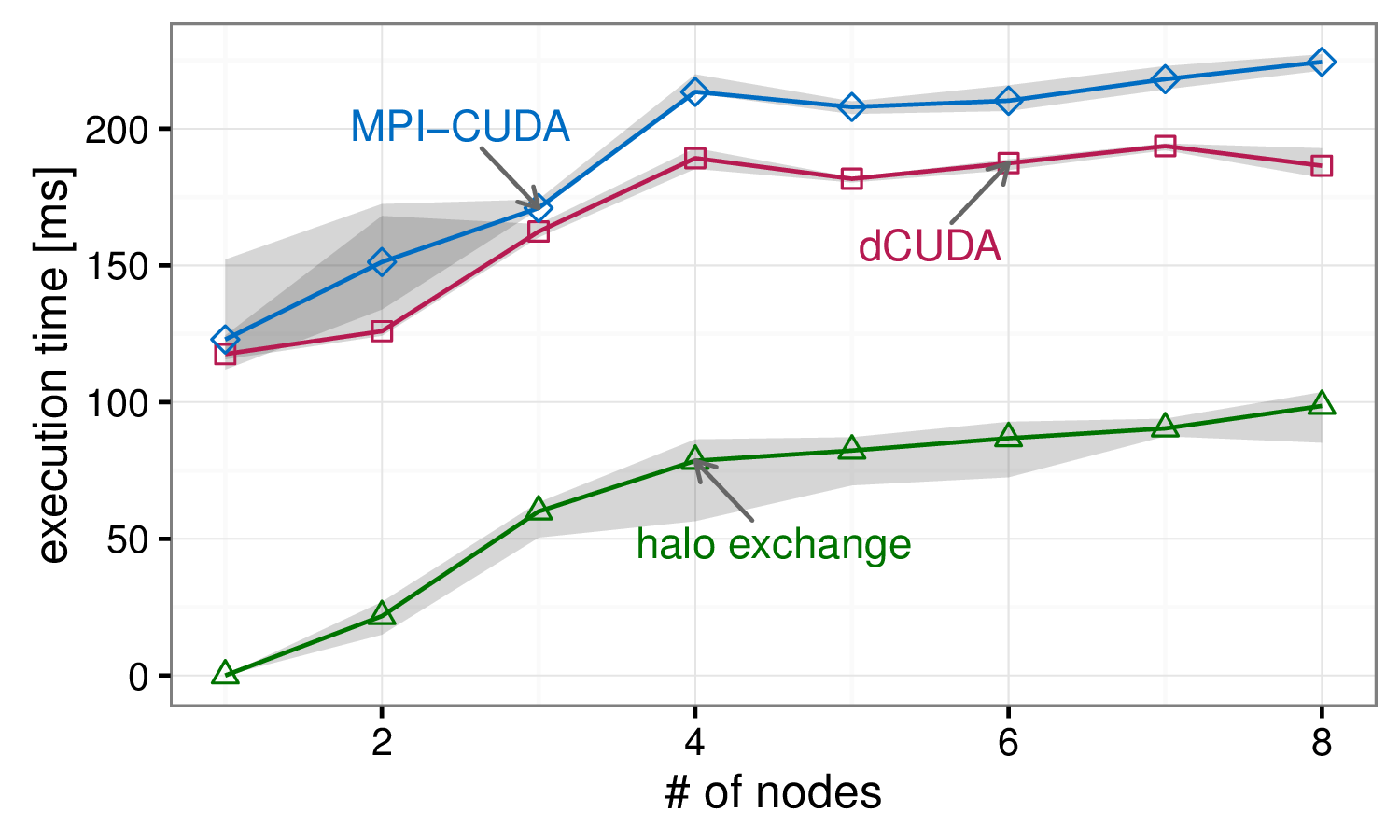
Weak scaling of the particle application
The weak scaling graph of the stencil application shows flat scaling for the dCUDA variant, while the scaling costs of the MPI-CUDA variant roughly correspond to the halo exchange overhead. In case of this regular application the dCUDA variant can completely overlap the communication overhead. However, the scaling costs of the particle application are partly attributed to load imbalances. The dCUDA variant clearly outperforms the MPI-CUDA variant, but the automatic overlap can only hide the communication costs and not the load imbalances.
Download
| Version | Date | Changes |
| dcuda.tar.gz - (93 kB) | September 8, 2016 | First release |
References
| [1] T. Gysi, J. Baer, T. Hoefler: | ||
dCUDA: Hardware Supported Overlap of Computation and Communication
In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC16), presented in Salt Lake City, Utah, pages 52:1--52:12, IEEE Press, ISBN: 978-1-4673-8815-3, Nov. 2016, (acceptance rate: 18% (82/446)) 

| ||