|
SPONSORS
|
||||
|




|
COLLABORATIONS
|
||||||||||
|










foMPI: A Fast One-Sided MPI-3.0 Implementation
Motivation
Network interfaces evolve rapidly to implement a growing set of features directly in hardware. A key feature of today’s high-performance networks is remote direct memory access (RDMA). RDMA enables a process to directly access memory on remote processes without involvement of the operating system or activities at the remote side. This hardware support enables a powerful programming mode similar to shared memory programming. Directly programming RDMA hardware allows benefits in the following three dimensions:
- time by avoiding message matching and synchronization overheads
- energy by reducing data-movement, e.g., it avoids additional copies of eager messages
- space by removing the need for receiver buffering
Implementation
We introduce our implementation foMPI (fast one-sided MPI), a fully-functional MPI-3.0 RMA library implementation for Cray Gemini (XK5, XE6) and Aries (XC30) systems. foMPI is implemented using scalable protocols requiring O(log p) time and space per process on p processes to support post-petascale computers.
The foMPI implementation assumes only small bounded buffer space at each process, no remote software agent, and only put, get, and some basic atomic operations for remote memory access, which is true for most RDMA hardware. In order to maximize asynchronous progression and minimize overhead, foMPI interfaces to the lowest available hardware APIs. For inter-node (network) communication, foMPI uses the DMAPP (Distributed Memory Application), which has direct access to the hardware (GHAL) layer. For intra-node communication, we use XPMEM, a portable Linux kernel module that allows to map the memory of one process into the virtual address space of another. For fast intra-node communication, foMPI uses a optimized SSE memcpy.
Performance Evaluation
foMPI was evaluated using microbenchmarks (latency, message rate and overlap), two motif applications (a distributed hashtable and a dynamic sparse data exchange), the full production code MIMD Lattice Computation (MILC) and the NAS 3D FFT. foMPI was compared to Cray MPI’s highly tuned point-to-point as well as its relatively untuned one sided communication and two major HPC PGAS languages: Unified Parallel C (UPC) and Co-Array Fortran (CAF), both specially tuned for Cray systems. All benchmarks were executed on the Blue Waters system using the Cray XE6 nodes.
Microbenchmarks:
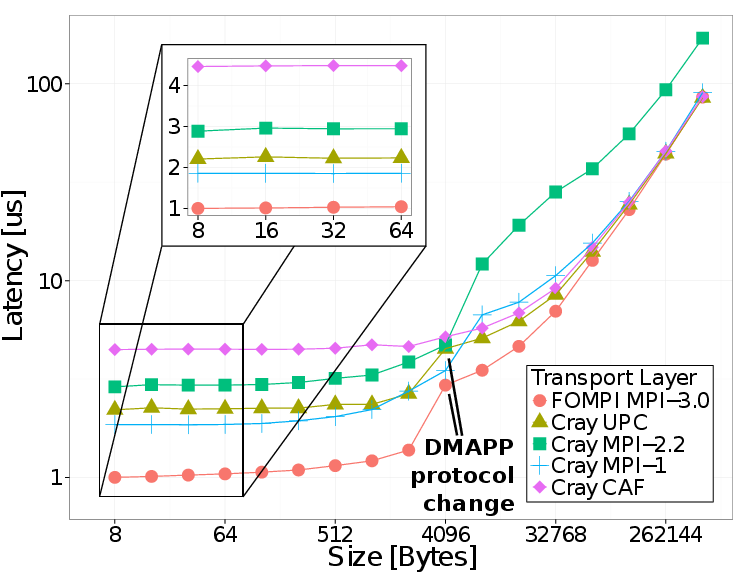
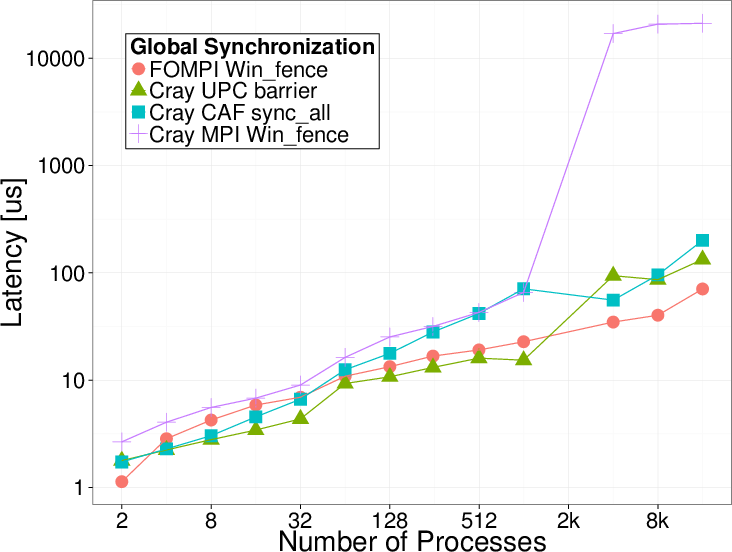
Latency results for inter-node Put and Global Synchronization
Applications:
We used MPI and UPC versions of the NAS 3D FFT
benchmark. For a fair comparison, our foMPI implementation uses the same
decomposition and communication scheme like the UPC version and required
minimal code changes resulting in the same code complexity. The figure
shows the performance for the strong scaling class D benchmark (2048 ×
1024 × 1024) on different core counts.
The MIMD Lattice Computation (MILC) represents the field of Quantum Chromodynamics (QCD), the theory of strong interaction. Again, the foMPI implementation used the same scheme as the UPC version without leveraging advanced concepts like MPI Datatypes. The figure shows the execution time of the whole application for a weak-scaling problem with a local lattice of 4 x 4 x 4 × 8.
The MILC application was scaled successfully up to 524,288 processes with all implementations. This result and our microbenchmark demonstrate the scalability and performance of our protocols and that the new RMA semantics can be used to improve full applications to achieve performance close to the hardware limitations in a fully portable way. foMPI further demonstrates that the new MPI-3.0 RMA interface delivers comparable performance to tuned, vendor-specific compiled languages like CAF and UPC.
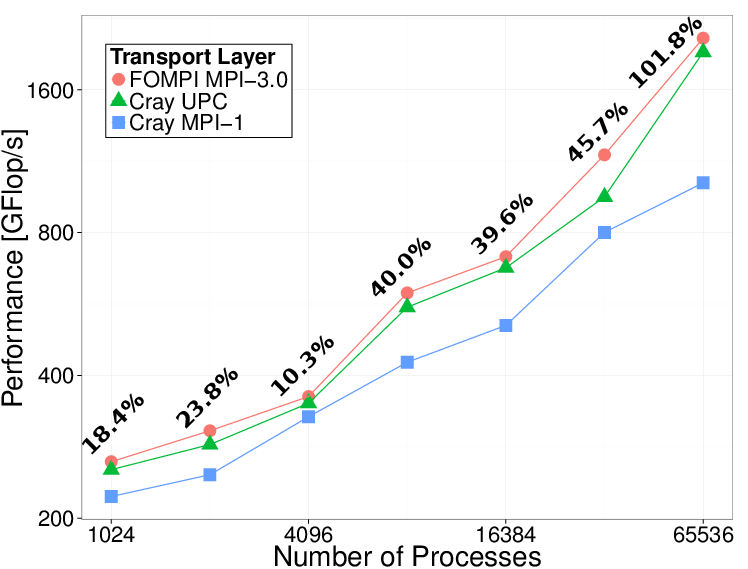
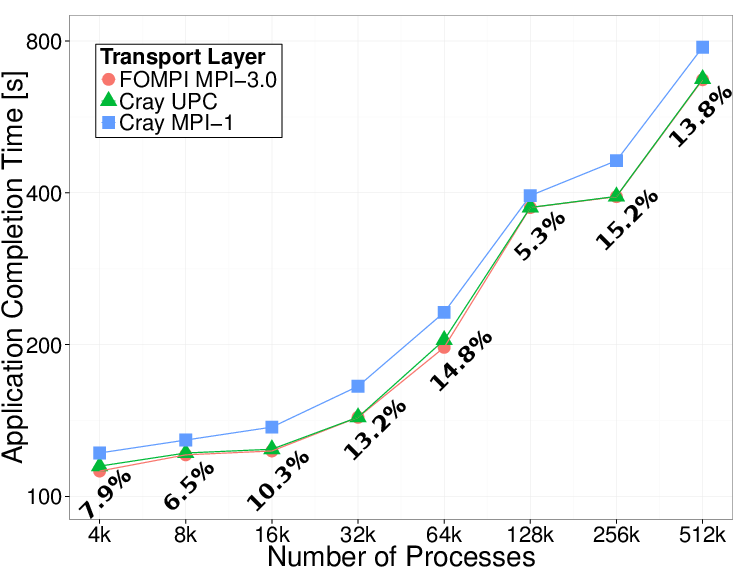
3D-FFT and MILC (full application execution time) results. The annotations represent the improvement of foMPI over MPI-1.
A patch file for the MILC source code can be found in the Download section. For more details and additional results see reference.
Download
The foMPI download links can be found below. It offers Fortran and C interfaces. The archive contains the libraries MPITypes and libtopodisc by William Gropp. Please consult the README file in the archive for information on building and using foMPI. Development versions are available on Github
| Version | Date | Changes |
| hashtable_foMPI.tar.gz - (0.4kb) | May 15, 2014 | parallel hashtable implementation using foMPI |
| MILC 7.6.3 foMPI patch - (17mb) | April 28, 2014 | |
| foMPI-0.2.1.tar.gz - (0.4 mb) | September 13, 2013 | tested with Intel compiler, easier build system |
| foMPI-0.2.0.tar.gz - (2.2 mb) | July 09, 2013 | full Fortran interface |
| foMPI-0.1.1.tar.gz - (2.2 mb) | May 03, 2013 | minor bug fix |
| foMPI-0.1.tar.gz - (2.2 mb) | May 01, 2013 | initial release, C support only |
References
| [1] R. Gerstenberger, M. Besta, T. Hoefler: | ||
Enabling Highly-Scalable Remote Memory Access Programming with MPI-3 One Sided
In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (SC'13), presented in Denver, CO, USA, pages 53:1--53:12, Association for Computing Machinery, ISBN: 978-1-4503-2378-9, Nov. 2013, (acceptance rate: 20%, 92/457) Best Student Paper Finalist (8/92) and Best Paper (1/92) 


| ||